

1. 서 론
2. 기존 항타공식과 AI 모델
2.1 수정 Hiley 공식
2.2 K-최근접 이웃(KNN)
2.3 랜덤 포레스트(Random Forest)
3. 데이터 분석 방법
3.1 데이터 구성
3.2 데이터 분석 방안
4. 분석 결과 및 해석
4.1 KNN 모델 예측 결과
4.2 랜덤 포레스트 모델 예측 결과
5. 결 론
1. 서 론
국내 건설 현장에서 말뚝 기초는 구조물의 하중을 지반에 안전하게 전달하기 위한 핵심 요소이며, 그 시공 품질은 전체 구조물의 안정성과 직결된다. 특히 PHC(Prestressed High-strength Concrete) 말뚝을 이용한 항타 공법은 반복 시공이 용이하고, 시공 속도 및 경제성 측면에서 장점이 있어 현장에서 널리 활용되고 있다(Cao et al., 2020; Huynh et al., 2022; Kou et al., 2016, Kim and Kim 2019). 이러한 항타 방식에서는 시공 중 확보 가능한 관입량(set)과 항타 에너지 등의 데이터를 바탕으로 말뚝의 품질을 간접적으로 관리하는 방식이 일반화되어 있다. 이는 모든 말뚝에 대해 정재하시험이나 PDA를 이용한 동재하시험을 적용하는 것이 시간적·경제적 제약으로 인해 현실적으로 어렵기 때문이다(Kim et al., 2024).
관입량 기반의 품질 관리는 시공 중 간편하게 적용 가능하다는 장점이 있지만, 단편적인 항타 데이터만으로 말뚝의 지지력을 신뢰성 있게 평가하기에는 근본적인 한계가 존재한다. 이에 따라 항타 데이터를 체계적으로 해석하여 정량화된 지지력을 산정할 수 있는 항타 공식이 실무에서 활용되고 있다. 이러한 항타 공식은 주로 항타 말뚝을 대상으로 개발된 경험식으로, 해머의 낙하 에너지와 관입량 간의 관계를 바탕으로 말뚝 지지력을 추정한다. 항타 시 발생하는 동역학적 반응을 활용하여 지지력을 산정하는 방식으로, 여러 연구자에 의해 지속적으로 개선됐다. 매입 말뚝도 시공 마지막 단계에서 최종 경타를 수행하는 경우, 항타 말뚝과 유사한 동역학적 거동을 보이므로, 항타 공식을 적용하여 지지력 예측이 가능하다.
항타 공식 중, 수정 Hiley 공식은 해머 에너지와 관입량뿐 아니라 리바운드(rebound) 값을 반영함으로써 더욱 정밀한 지지력 산정이 가능한 공식으로 평가받고 있다. 리바운드는 말뚝과 지반 사이의 반발 저항을 정량화할 수 있는 변수로, 이론적으로는 지지력 산정에 유의미한 역할을 한다. 그러나 실무 현장에서는 리바운드 값을 안정적이고 정밀하게 계측하는 데 여러 가지 한계가 존재한다. 실제로 대부분의 현장에서는 리바운드와 관입량을 펜과 종이에 수기로 기록하는 방식에 의존하고 있으며, 이에 따라 작업자 간 편차와 오차가 발생할 가능성이 높으며 안전에 위험이 있다(Yun et al., 2005; Ha et al., 2003). 이에 따라 최근에는 고속 카메라나 고정밀 센서 등 정밀 계측 장비를 활용하려는 시도가 이루어지고 있으나, 고비용 및 장비 운용의 복잡성으로 인해 실질적인 보급은 매우 제한적이다. 또한 계측 방식에 대한 표준화가 미흡하여 동일 조건에서도 반복성과 재현성을 확보하기 어려운 상황이다. 따라서 리바운드의 활용은 이론적으로는 유효하지만, 계측 신뢰성이 낮고 실무 적용성이 떨어진다는 근본적인 제약을 안고 있다. 이러한 현실적인 한계로 인해, 실제 시공 현장에서는 관입량(set)만을 활용하여 관리만 하는 실정이다. 하지만 이는 구조 안전성 저하로 이어질 우려가 있으며, 장기적인 성능 저하와도 연결될 수 있다. 따라서 리바운드와 같이 계측이 어렵고 신뢰성이 낮은 변수를 제외하되, 여전히 높은 예측 정밀도를 유지할 수 있는 새로운 분석 기법의 도입이 요구된다.
최근 건설 분야에서는 인공지능(AI)을 활용한 데이터 기반 예측 기법이 점차 다양한 분야에 도입되고 있으며, 이는 기존에 정형화된 경험적 또는 이론적 모델이 가지는 적용 한계를 보완할 수 있는 대안으로 주목받고 있다. 예를 들어, 딥러닝 모델을 활용하여 지반 지지층 깊이를 예측하는 연구, 터널과 같은 지반구조물의 안정성을 분석하는 연구, 인공신경망을 통해 점성토 지반의 전단파속도를 예측하는 연구, 암반 사면의 전단강도를 산정하는 연구들이 발표되었다(Kim et al., 2014; Lee et al., 2022; Jang et al., 2022; Lee et al., 2025). 이러한 연구들은 AI 모델이 지반 특성 예측에 효과적으로 활용될 수 있음을 보여주며 특히 시공 중 수집되는 항타 관련 데이터는 비교적 간편하게 확보 가능하다는 장점이 있음에도 불구하고, 단편적인 계측값만으로 정밀한 지지력 예측을 수행하기에는 신뢰성과 반복성 측면에서 많은 제약을 내포하고 있다. AI 기반 예측 모델의 도입은 시공 데이터를 더욱 체계적으로 해석하고 예측 정확도를 실시간으로 향상시킬 수 있는 수단으로 활용될 수 있다(Heo and Jeong, 2021; Kim et al., 2017).
본 연구에서는 리바운드 값을 포함한 항타 정보를 활용하여 말뚝 지지력을 예측하기 위해, 대표적인 머신러닝 회귀 기법 중 K-최근접 이웃(K-Nearest Neighbors, KNN)과 랜덤 포레스트(Random Forest) 모델을 선정하였다. K-최근접 이웃은 거리 기반 모델로서 단순한 구조와 해석 용이성을 바탕으로, 소규모 데이터셋 및 제한된 입력 변수 환경에서의 예측 성능을 확인하는 데 적합하다. 반면, 랜덤 포레스트는 다수의 결정 트리를 결합한 앙상블 구조로, 변수 간 비선형 상호작용을 반영하고 변수 중요도 해석이 용이하다는 점에서 본 연구의 분석 목적과 부합한다. 일부 고성능 회귀 모델 중 하나인 서포트 벡터 회귀는 예측 성능이 우수한 것으로 알려져 있으나, 하이퍼파라미터 설정에 민감하고 실시간 현장 적용을 고려할 경우 계산 비용과 해석 난이도가 높아 실용적 한계가 존재한다. 따라서 본 연구에서는 단순한 변수 영향 평가를 넘어, 현장 적용성, 해석 가능성, 자동화 연계성 등을 고려하여 K-최근접 이웃과 랜덤 포레스트를 중심으로 분석을 수행하였다.
기계학습 기반 회귀 모델은 비선형적이고 상호작용적인 변수 관계를 효과적으로 학습할 수 있으며, 데이터가 축적될수록 예측 정밀도가 향상된다는 점에서 지속적인 개선 가능성을 가진다. 본 연구에서는 거리 기반 모델인 K-최근접 이웃(K-Nearest Neighbors, KNN)과, 다수의 결정 트리를 활용하여 예측의 안정성과 해석력을 높이는 앙상블 모델인 랜덤 포레스트(Random Forest)를 적용하였다. 두 모델은 서로 다른 예측 방식과 구조적 특징을 가지기 때문에, 리바운드 변수의 포함 여부가 예측 성능에 미치는 영향을 다각도로 분석할 수 있는 장점이 있다.
이를 위해, 국내 매입말뚝 현장 최종경타시점에 측정된 167개의 동재하시험(PDA) 데이터를 기반으로 AI 학습용 데이터 세트를 구성하였으며, 각 예측 모델의 결과를 대표적인 항타 공식인 수정 Hiley 공식과 정량적으로 비교하였다. 특히 리바운드 값과 같은 변수는 이론적으로는 의미 있는 정보이지만, 계측 신뢰성의 한계로 인해 실무에서 적용이 어려운 경우가 많다. 본 연구는 이러한 상황에서도 AI를 활용하면 일정 수준 이상의 예측 정확도를 확보할 수 있다는 가능성을 실증적으로 제시하고자 하였다.
2. 기존 항타공식과 AI 모델
2.1 수정 Hiley 공식
항타 공식(Pile driving formula)은 말뚝-지반 상호작용의 시간 의존성을 반영하지 않기 때문에, 장기 지지력을 평가하는 데에는 일정한 한계가 존재하며, 시간적 요소가 반영된 정재하시험 결과와 직접 비교하는 것은 어렵다. 따라서, 항타 공식의 유효성은 최종 항타 직후(End of Initial Driving, EOID)에 수행된 동재하시험과의 비교를 통해 판단하는 것이 타당하다(Cho and Lee, 2001).
현재까지 사용되고 있는 다양한 항타 공식들은 초창기 간단한 형태에서 출발하여 여러 연구를 통해 개선됐으며, 대표적으로 Gates 공식과 Hiley 공식이 가장 보편적으로 활용되고 있다(Oh and Lee, 2003). 이 중 수정 Hiley 공식은 항타 시 해머에서 말뚝에 전달되는 에너지에 더해 관입량과 리바운드 변수를 함께 고려함으로써 지지력을 산정할 수 있도록 구성된 공식이다(Cho et al., 2001). 수정 Hiley 공식은 다음과 같다.
여기서, : 지지력(N), : 말뚝에 전달된 에너지(N·m), : 관입량(m), : 관입량 + 리바운드(m)를 의미한다.
해당 공식은 말뚝과 지반의 상호작용을 더욱 정밀하게 반영할 수 있어, 국내외에서 가장 신뢰도 높은 항타 공식 중 하나로 평가되고 있다. 기존 연구에서 161개의 동재하시험 데이터를 기반으로 수정 Hiley 공식을 검토한 결과, 기존 항타 공식 중 가장 높은 정확도를 보이는 것으로 확인되었다(Kim et al., 2024). 그러나 수정 Hiley 공식의 활용에는 명확한 한계가 존재한다. 우선, 수정 Hiley 공식은 동재하시험로부터 취득된 값을 활용해야 온전한 정확도를 가질 수 있다. 또한, 공식에 필요한 리바운드 값은 시공 중 수기로 계측되는 경우가 많으며, 작업자 숙련도와 계측 환경에 따라 오차가 크게 발생할 수 있다. 마지막으로, 고정밀 센서를 활용한 정량 계측 시스템의 보급은 아직 미흡한 상황이다. 정확한 리바운드의 계측이 어렵고 모든 말뚝에 대해 동재하시험이 불가능한 실제 현장에서는 해당 공식의 활용이 제한적일 수밖에 없다.
그럼에도 불구하고, 본 연구에서는 수정 Hiley 공식을 AI 기반 예측 모델의 비교 기준으로 선정하였다. 이는 단순한 관입량 기반 품질관리 방식보다 정량적 해석 수준이 높고, 기존 항타 공식 중 비교적 높은 정확도를 갖춘 수정 Hiley 공식과의 비교를 통해 AI 모델의 상대적 성능을 검증하는 것이 더 실질적인 평가 기준이 될 수 있다고 판단하였기 때문이다. 또한, 기존 공식과의 정량 비교는 AI 모델이 실제 현장 적용 가능성을 확보하기 위한 최소한의 실무 검증 수단으로 활용될 수 있다. 따라서 본 연구에서는 리바운드 없이도 이와 유사한 지지력 예측 성능을 달성할 수 있는지를 검토함으로써 AI 기반 대체 모델의 타당성을 입증하고자 한다.
2.2 K-최근접 이웃(KNN)
K-최근접 이웃 모델은 지도학습 기반의 비모수(non- parametric) 회귀 기법으로, 예측하고자 하는 값에 대해 학습 데이터 중 가장 가까운 K개의 데이터를 선택하여 이들의 평균값 또는 가중평균 값을 예측값으로 사용하는 방식이다(Burba et al., 2009). 이 모델은 간단한 원리로 구현이 가능하며, 데이터의 분포나 함수 형태에 대한 사전 가정이 필요 없다는 장점이 있다. 또한, 입력 변수 간의 복잡한 비선형 관계를 모델링할 수 있어 말뚝 항타 데이터와 같은 다양한 변수가 포함된 환경에서도 유용하게 활용될 수 있다.
K-최근접 이웃 모델은 거리 기반 모델이기 때문에 변수 간 단위 차이가 큰 경우 성능 저하가 발생할 수 있으며, 데이터의 밀도가 낮은 영역에서는 예측 정확도가 낮아질 수 있다. 따라서 변수 정규화 및 적절한 하이퍼파라미터(K, 거리 측정 방식 등)의 선택이 모델 성능에 중요한 영향을 미친다. 본 연구에서는 리바운드 값의 포함 여부에 따라 K-최근접 이웃 모델의 예측 정확도(R2) 및 평균 절대 백분율 오차(MAPE)를 비교하고, GridSearchCV를 활용한 최적 하이퍼파라미터 조정을 통해 모델 성능을 정량적으로 분석하였다.
2.3 랜덤 포레스트(Random Forest)
랜덤 포레스트 모델은 배깅(Bagging) 기법을 기반으로 다수의 결정트리(Decision Tree)를 결합한 앙상블 학습 모델로, 높은 예측 정확도와 과적합 방지 능력으로 다양한 회귀 및 분류 문제에서 널리 활용되고 있다(Breiman, 2001). 각 트리는 전체 데이터셋 중 임의로 선택된 부분 샘플과 일부 변수만을 사용하여 독립적으로 학습되며, 최종 예측값은 모든 트리의 평균값으로 산출된다.
랜덤 포레스트 모델의 큰 장점 중 하나는 변수 중요도(feature importance)를 자동으로 계산할 수 있다는 점으로, 이는 변수 간 상관성 및 예측 기여도를 파악하는 데 유리하다. 또한 비선형성과 변수 간 상호작용을 잘 처리할 수 있어 복잡한 구조의 말뚝 시공 데이터를 해석하는 데 적합하다. 본 연구에서는 리바운드 변수의 포함 여부가 예측 성능에 어떤 영향을 미치는지를 확인하고, 튜닝 전후의 성능 변화를 바탕으로 AI 기반 지지력 예측 모델의 활용 가능성을 검토하였다.
3. 데이터 분석 방법
3.1 데이터 구성
분석에는 총 167건의 동재하시험 결과가 활용되었으며, 사용된 말뚝은 모두 직경 600mm의 PHC 말뚝이다. 해당 데이터는 9개의 서로 다른 현장에서 수집되었으며, 이 중 5개 현장에서 취득된 77개의 데이터는 상부는 풍화토, 하부는 풍화암으로 구성된 국내에서 비교적 흔한 지반 조건을 포함하고 있으며, 풍화암까지의 깊이는 대체로 10~ 20m 수준이다. 또한, 활용된 지지력 데이터는 약 200톤에서 600톤 사이의 다양한 범위를 포함하고 있어, 예측 모델의 일반화 가능성 확보에 유리한 특성을 지닌다. 입력 변수는 해머 항타 높이(hammer_height), 해머 효율이 반영된 해머 무게(hammer_weight), 관입량, 리바운드로 구성되며, 타깃 변수는 동재하시험으로 계측된 지지력(pda_ capacity)이다. 본 연구에서 활용된 리바운드 값은 동재하시험 DMX를 통해 도출된 리바운드 값을 활용하였기 때문에 기존 수기 측정 방식보다 상대적으로 정확도가 높으며 일관성이 있다. 분석은 리바운드 변수를 포함한 경우와 제외한 경우의 두 가지 조건으로 나누어 동일한 절차로 반복 수행되었다. 각 데이터셋은 8:2 비율로 학습용과 테스트용으로 나누었으며, 모델 성능 평가지표로는 결정계수(R2)와 평균 절대 백분율 오차(Mean Absolute Percentage Error, MAPE)를 사용하였다.
이러한 분석 설계를 통해 리바운드 값이 포함될 경우와 제외될 경우의 AI 모델별 말뚝 지지력 예측 정확도를 정량적으로 비교하고, AI 모델에서의 변수 활용 방식이 기존 항타 공식의 물리적 해석과 어떠한 차이를 보이는지 확인하였다.
3.2 데이터 분석 방안
본 연구에서는 말뚝 항타 데이터 기반의 지지력 예측을 위해 AI 모델인 K-최근접 이웃과 랜덤 포레스트를 활용하였다. Fig. 1은 본 연구에서 제안한 AI 기반 말뚝 지지력 예측 모델의 전체 워크플로우를 나타낸다. 입력 변수부터 모델 학습, 하이퍼파라미터 튜닝, 5-fold 교차검증을 통한 평가, 그리고 기존 Hiley 공식 및 동재하시험 결과와의 비교까지의 전체 과정을 시각화하였다. 각 데이터셋은 8:2 비율로 학습용과 테스트용으로 나누었다. 데이터를 통해 학습된 두 AI 모델을 이용하여 지지력을 예측 및 평가 후, 하이퍼파라미터 튜닝을 통해 모델을 개선하고 성능을 재평가하였다. 모든 결과는 기존 항타 공식(수정 Hiley 공식)과의 비교를 통해 유효성을 검토하였다. 본 연구에서 선택한 두 AI 기법은 실제 엔지니어링 분야에서 널리 활용되는 대표적인 지도 학습 기반의 회귀 모델로, 비교적 적은 데이터 세트에서도 높은 예측 성능을 보이며, 복잡한 비선형 관계를 효과적으로 모델링할 수 있다는 장점을 갖는다(Halder et al., 2024; Zhu, 2020). 랜덤 포레스트 모델은 트리 기반 알고리즘으로 변수의 스케일에 영향을 받지 않기 때문에 별도의 정규화 과정을 수행하지 않았으며, K-최근접 이웃 모델은 거리 기반 특성상 일반적으로 정규화가 필요하나, 본 연구에서는 변수 간 스케일 차이가 크지 않아 정규화 없이도 일정 수준 이상의 예측 성능을 보였다.
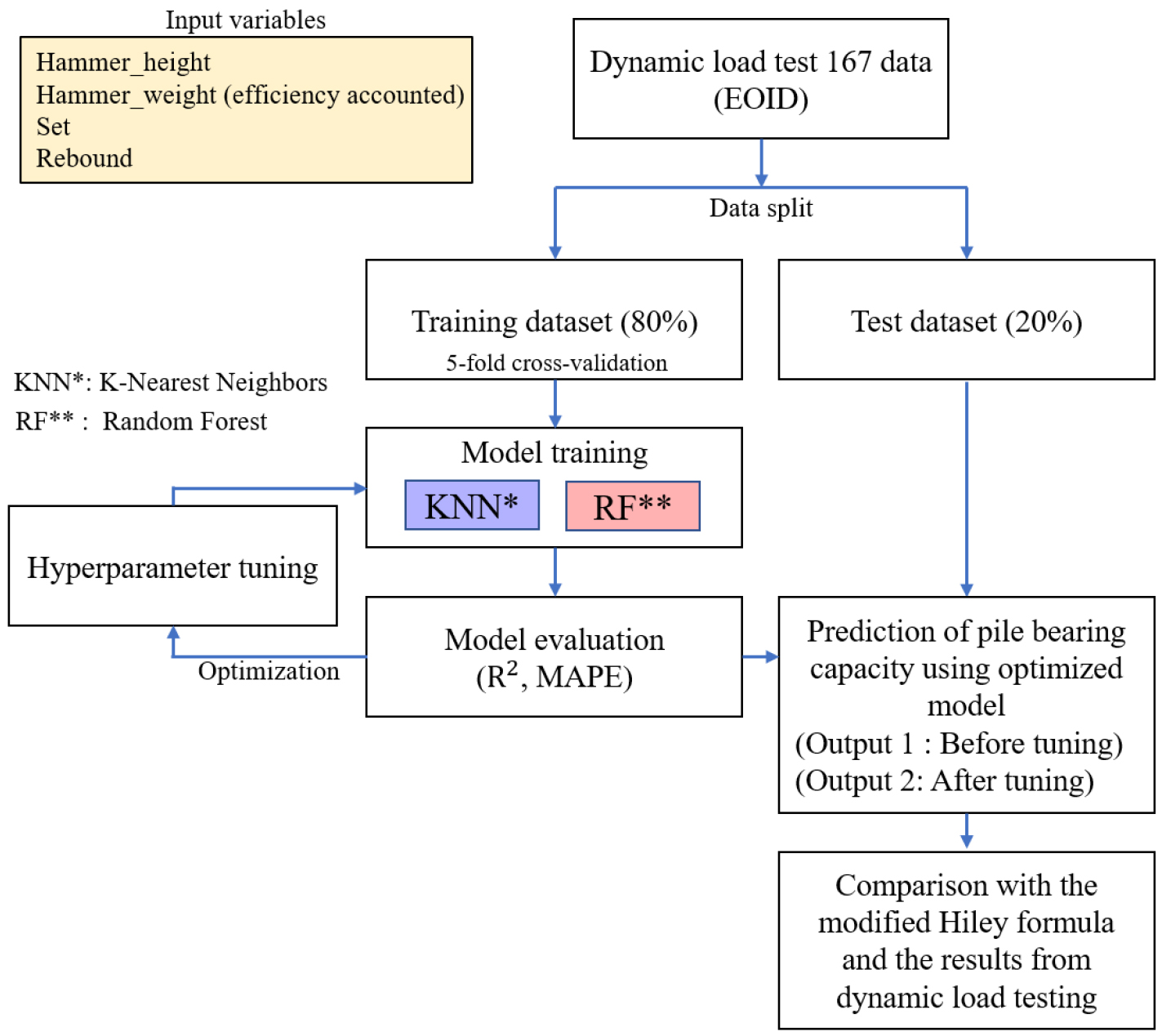
K-최근접 이웃 모델은 알고리즘이 단순하면서도 해석이 직관적이며, 입력 변수의 분포에 민감하게 반응하는 특징이 있어 항타 데이터를 기반으로 한 정량 예측에 적합하다고 판단하였다. 랜덤 포레스트는 변수 간 상호작용을 자동으로 포착할 수 있으며, 이상치(outlier)에 대한 내성이 높고 변수 중요도(feature importance)를 해석 가능하다는 점에서 말뚝 시공과 같은 복합 시스템의 예측 문제에 적합한 모델이다. 이러한 특성은 기존 토목공학 및 지반공학 분야의 다양한 연구에서도 입증됐으며, 예컨대 구조물 잔존 수명 예측, 콘크리트 강도 예측, 토질 분류, 도로 노면 상태 예측, 기초 거동 해석 등의 문제에서 널리 활용되고 있다(Goh, 1995; Shahin et al., 2001; Gupta et al., 2006).
특히 본 연구는 K-최근접 이웃과 랜덤 포레스트 두 모델이 각각의 원리에 따라 데이터를 해석하는 방식이 상이하다는 점에 주목하고, 리바운드 변수의 유무가 예측 정확도에 어떤 영향을 미치는지를 정량적으로 비교하고자 하였다. 이를 통해 각 모델이 지지력 예측 문제에 적합한 이유와 한계를 종합적으로 검토하였다.
모든 예측 모델의 성능은 동재하시험의 결과와 비교 때 결정계수(R2)와 평균 절대 백분율 오차(MAPE)를 기준으로 평가하였으며, 동일한 테스트 세트에서 산출된 수정 Hiley 공식의 예측값과의 비교를 통해 AI 모델의 상대적 유효성을 비교하였다.
4. 분석 결과 및 해석
4.1 KNN 모델 예측 결과
K-최근접 이웃 모델의 분석 결과, 동재하시험을 통해 산정된 지지력과 비교시 리바운드 포함 여부에 따라 약간의 성능 차이를 보였다. 하이퍼파라미터 튜닝 전에는 리바운드를 포함한 모델이 결정계수(R2) 0.795, 평균 절대 백분율 오차(MAPE) 10.59%를 나타냈고, 리바운드를 제외한 모델은 R2 0.751, MAPE 10.92%로 나타나 큰 차이를 보이지 않았다(Table 1). 하이퍼파라미터 튜닝 후에는 리바운드를 제외한 모델의 R2가 0.765로 소폭 증가하였으나, 포함된 모델의 성능은 오히려 0.784로 약간 감소하였다. 이러한 현상은 K-최근접 이웃 모델의 특성에서 기인한다. K-최근접 이웃 모델은 입력 변수 간 중복된 정보에 민감하며, 거리 기반의 예측 방식이 국지적인 데이터 밀도와 변수 간 높은 상관성에 영향을 받기 때문이다(Altman, 1992). 실제로 Pearson Correlation 상관성 분석 결과, 리바운드는 해머 무게와 각각 0.71의 높은 상관성을 보였다. 따라서 리바운드를 포함하면 변수 간 중복성이 증가하여 거리 기반 계산이 왜곡될 수 있다.
Table 1.
Comparison of KNN prediction performance (R2, MAPE)
이와 같은 분석 결과는 Fig. 2(a)와 Fig. 2(b)에 시각적으로 정리하였다. Fig. 2(a)는 리바운드 포함 여부와 하이퍼파라미터 튜닝에 따른 K-최근접 이웃 모델의 결정계수(R2) 변화를 비교한 것으로, 네 가지 모델의 상대적인 예측 성능과 수정 Hiley 공식의 정확도를 한눈에 확인할 수 있다. Fig. 2(b)는 동일한 조건에서의 평균 절대 백분율 오차(MAPE) 결과를 비교한 것으로, 리바운드 변수의 포함 여부가 모델의 정확도에 미치는 영향을 정량적으로 나타낸다.
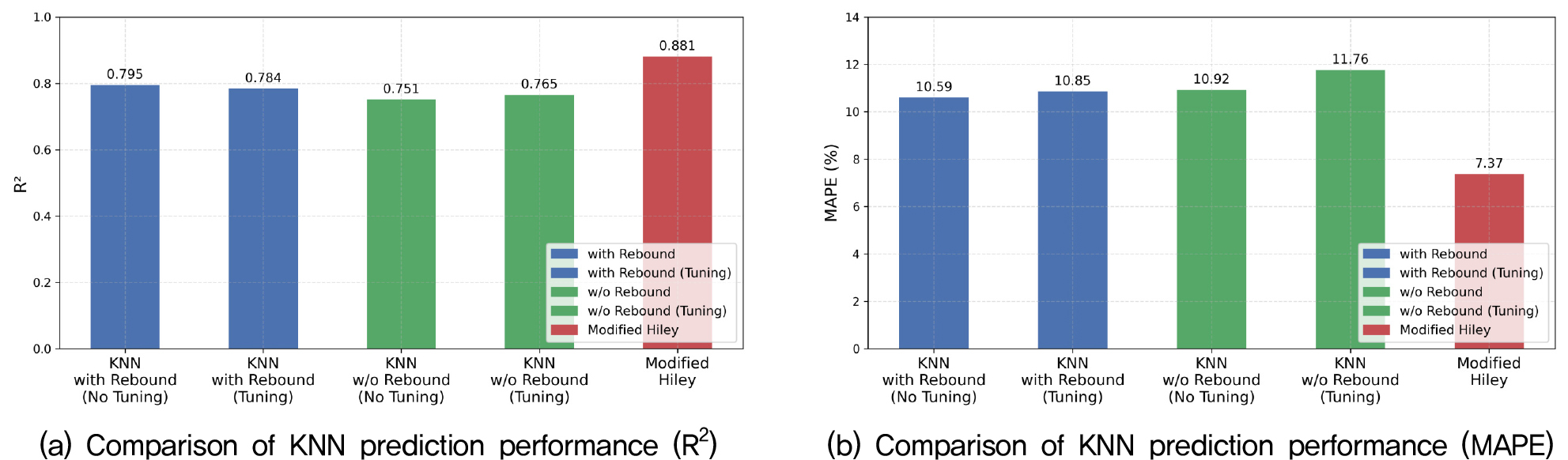
Fig. 3과 Fig. 4는 K-최근접 이웃 모델의 예측값과 실제 PDA 측정값 간의 비교 결과를 시각화한 것이다. Fig. 3(a)와 3(b)는 리바운드를 포함한 경우, Fig. 4(a)와 4(b)는 리바운드를 제외한 경우의 예측 성능을 각각 나타낸다. 모든 조건에서 K-최근접 이웃 모델은 PDA 결과와 비교적 높은 상관성을 보였으며, 이는 해당 모델이 적절한 입력 변수만 확보된다면 말뚝 지지력 예측에 실용적으로 활용될 수 있음을 시사한다. 하지만 수정 Hiley 공식이 가장 높은 정확도(R2 0.881, MAPE 7.37%)를 보였다. 이는 동재하시험 데이터에 최적화된 수정 Hiley 공식 계산에 동재하시험 데이터가 온전히 활용되었기 때문이다. 실제 현장에서는 모든 말뚝에 대해 동재하시험을 수행할 수 없으며, 수기를 통해 취득된 리바운드 값의 정확도 또한 낮으므로 이러한 결과를 기대하기 어렵다. 이러한 현실적인 요소들을 고려한다면 리바운드를 포함하지 않은 모델의 상대적인 예측 정확도가 더 높을 것으로 기대된다.
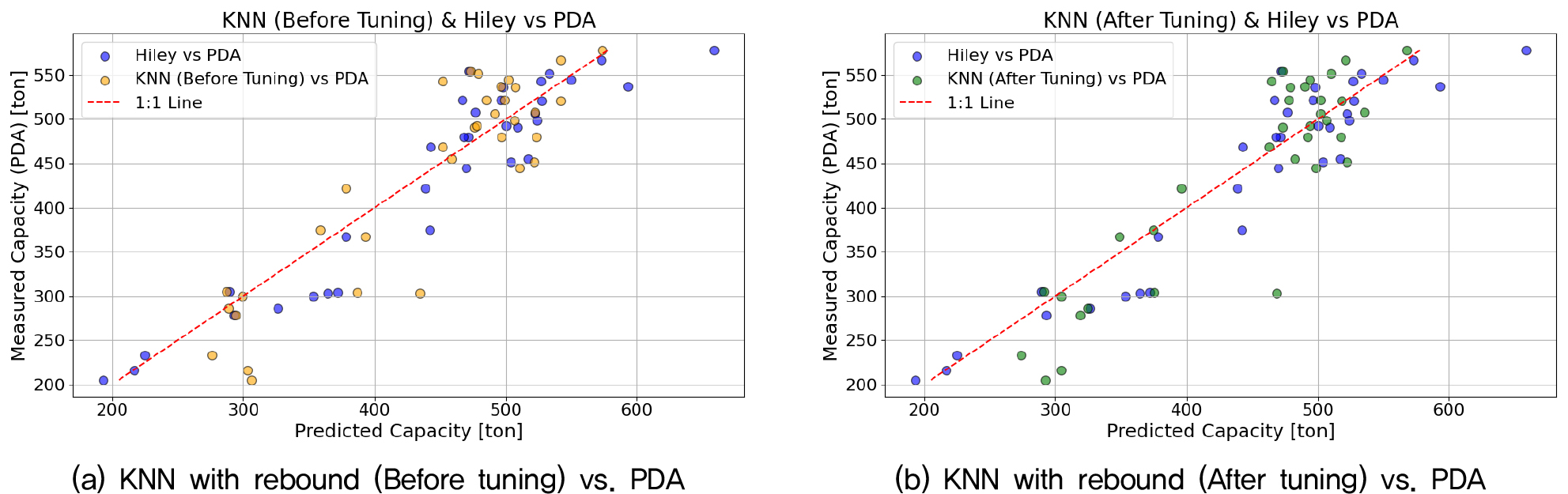
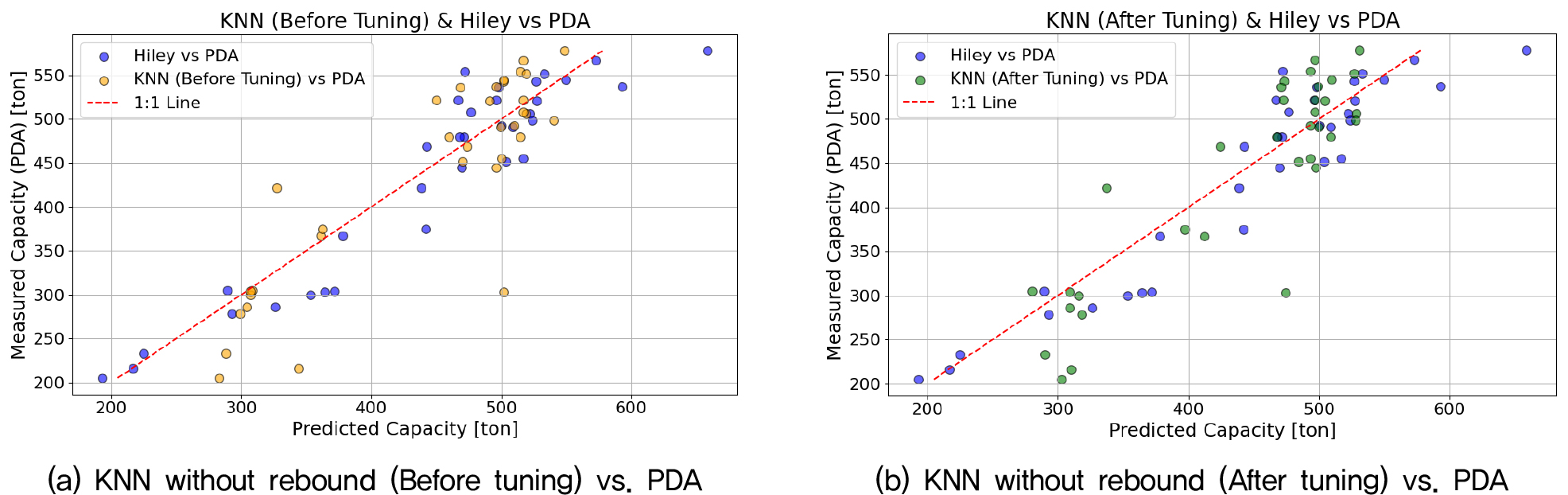
4.2 랜덤 포레스트 모델 예측 결과
랜덤 포레스트 모델은 트리 기반의 앙상블 학습 구조로 변수 간의 비선형 관계와 이상치에 강건한 특성을 보인다. 본 연구에서 리바운드 포함 모델의 경우 튜닝 전 R2는 0.834, MAPE는 8.93%였으며, 튜닝 후 성능이 R2 0.843, MAPE 8.89%로 소폭 개선되었다(Table 2). 리바운드를 제외한 경우 튜닝 전 R2 0.811, MAPE 9.09%에서 튜닝 후 R2 0.833, MAPE 8.58%로 개선되었다.
Table 2.
Comparison of random forest prediction performance (R2, MAPE)
리바운드를 제외한 모델이 더 낮은 MAPE를 기록한 점은 랜덤 포레스트가 리바운드 변수의 중요도를 상대적으로 낮게 평가했기 때문이다. 이는 리바운드가 다른 변수들과의 높은 상관성으로 인해 중복된 정보를 제공한 것으로 판단된다. 랜덤 포레스트의 튜닝 전후 성능 차이가 비교적 작았던 이유는 이 모델이 기본적으로 높은 일반화 능력과 안정성을 갖기 때문이다(Breiman, 2001). 랜덤 포레스트는 다수의 결정 트리를 이용하여 과적합을 방지하고, 변수 선택과 관련된 민감도가 낮다(Toloşi and Lengauer, 2011, Gregorutti et al., 2017). Table 2의 결과를 시각화한 Fig. 5(a)와 Fig. 5(b)는 랜덤 포레스트 모델의 예측 성능을 정량적으로 비교한 그래프이다. Fig. 5(a)는 리바운드 포함 여부 및 하이퍼파라미터 튜닝 전후에 따른 R2 변화 양상을 보여주며, Fig. 5(b)는 동일 조건에서의 MAPE 값을 비교한 결과를 나타낸다. 두 그래프를 통해, 랜덤 포레스트 모델은 전반적으로 튜닝 이후 성능이 소폭 향상되며, 리바운드 변수를 포함하지 않은 조건에서 더 낮은 MAPE를 기록함을 확인할 수 있다.
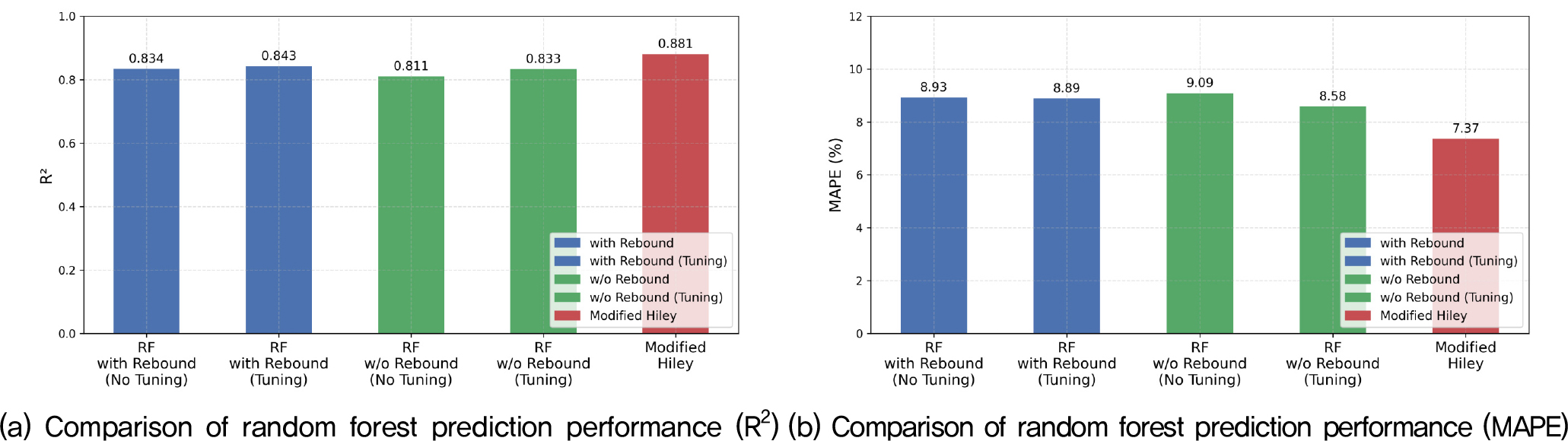
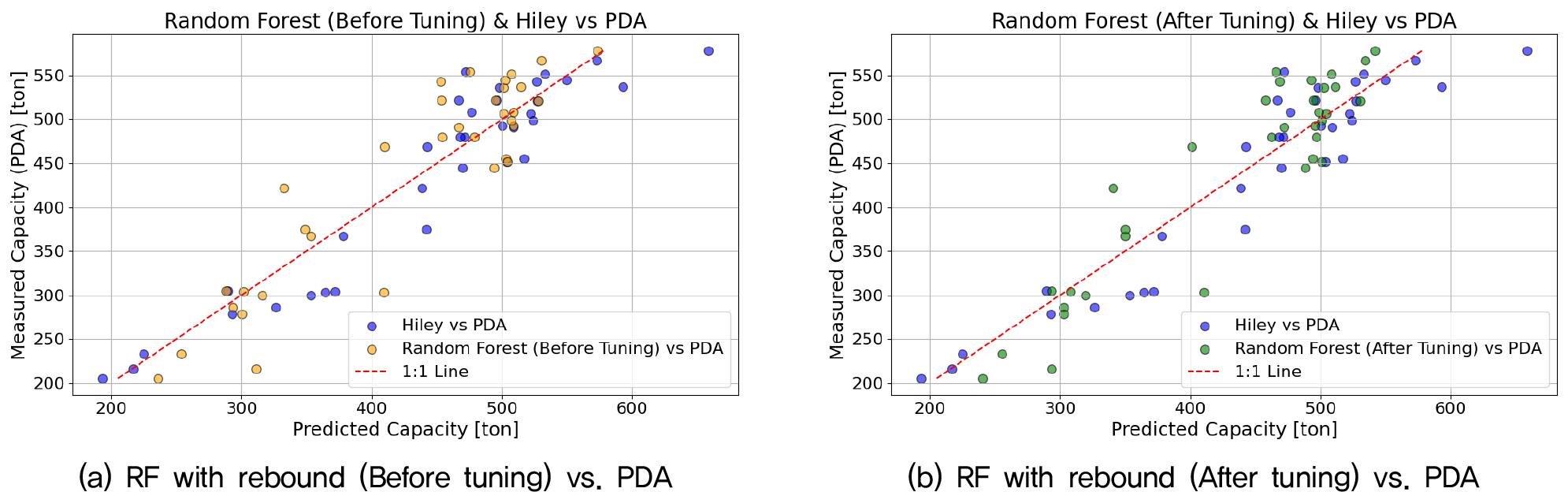
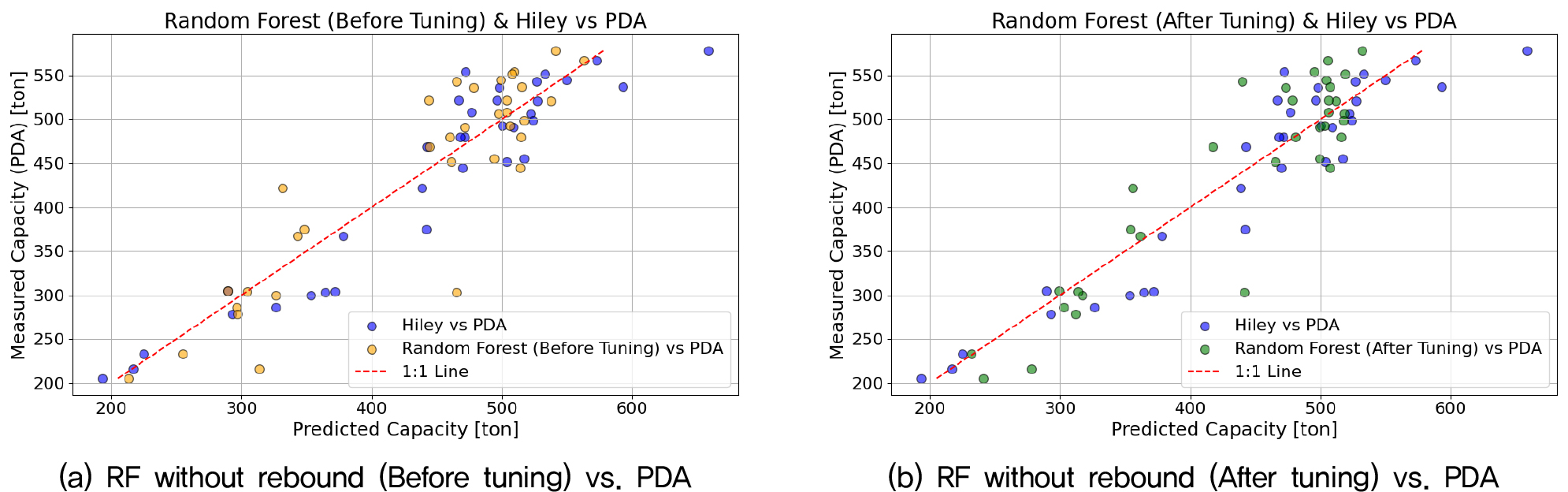
Fig. 6와 Fig. 7은 랜덤 포레스트 모델의 예측 결과와 PDA 측정값 간의 비교를 시각화한 결과로, Fig. 5는 리바운드를 포함한 경우, Fig. 6은 리바운드를 제외한 경우의 결과를 나타낸다. 각각 (a)는 튜닝 전, (b)는 튜닝 후의 결과이며, 전반적으로 예측값이 1:1 대각선 선상에 고르게 분포함을 확인할 수 있다. 특히 고지지력 영역에서는 수정 Hiley 공식보다 예측이 안정적으로 수렴하는 경향이 관찰되어, 랜덤 포레스트 모델이 현장 설계 및 시공 시 활용 가능한 예측 도구로서의 가능성을 보여준다. 랜덤 포레스트 모델이 수정 Hiley공식의 결과와 근접한 성능을 보이면서 AI 모델의 현장 적용 가능성을 뒷받침하였다. 수정 Hiley 공식이 가장 정확한 예측 결과를 보였지만, 해당 결과는 동재하시험으로 취득된 이상적인 데이터를 기반으로 한 결과이기 때문에 실제로는 상대적인 차이가 더 적거나 오히려 리바운드값을 고려하지 않은 AI 모델 결과가 가장 좋을 것으로 예상된다. 결론적으로 본 연구는 AI 기반 모델이 리바운드값을 제외하고도 현장에서 효과적인 예측 도구로 활용될 수 있음을 보여준다.
5. 결 론
본 연구는 말뚝 항타 시공 시 리바운드 계측의 어려움과 신뢰성 부족 문제를 해결하기 위한 대안으로 인공지능(AI) 기반 예측 기법의 가능성을 정량적으로 검토하였다. 167건의 동재하시험 데이터를 바탕으로, K-최근접 이웃과 랜덤 포레스트 두 가지 대표적 AI 모델을 적용하였고, 리바운드 변수의 포함 여부에 따른 예측 정확도를 비교 분석하였다.
분석 결과, 랜덤 포레스트 모델은 리바운드 없이도 R2 = 0.833, MAPE = 8.58%의 높은 예측 성능을 보였으며, 이는 리바운드를 포함한 경우와 큰 차이가 없는 수치이다. KNN 모델의 경우에도 리바운드를 포함하지 않고도 R2 = 0.765, MAPE = 11.76%의 성능을 나타내어, 실무 적용이 가능한 수준의 정밀도를 확보할 수 있음을 확인하였다. 특히 두 모델 모두, 리바운드 값을 생략하더라도 예측력이 많이 감소하지 않았으며, 이는 리바운드 정보가 기존 변수들과 높은 상관성을 가지거나 중복된 정보를 제공하고 있다는 점을 시사한다. 또한 하이퍼파라미터 튜닝은 모델의 성능에 일정 부분 영향을 미쳤으나, 개선을 보장하지는 않는다는 점도 확인되었다. K-최근접 이웃 모델의 경우 튜닝 이후 성능이 오히려 감소한 사례도 존재하였으며, 이는 데이터 특성과 모델의 민감도에 따라 튜닝 방향이 달라져야 함을 보여준다. 반면, 랜덤 포레스트는 튜닝 전후 안정적인 성능을 유지하며, 실무 적용 시 신뢰성 있는 모델로 평가될 수 있다.
Hiley 공식과의 비교 결과, AI 기반 모델은 기존 항타 공식 대비 약간 낮은 예측 정확도를 보였으나, 이는 동재하시험을 활용한 이상적인 조건으로 실제와는 차이가 있을 것으로 판단된다. 특히 랜덤 포레스트 모델은 리바운드 없이도 수정 Hiley 공식에 근접하는 성능을 보여주었으며, 이는 리바운드 계측이 어려운 현장 조건에서 AI 모델의 대체 가능성을 시사한다.
향후 연구에서는 다양한 지반 조건과 말뚝 유형에 따른 데이터 확장 및 모델에 입력되는 변수를 물리적 해석 기반으로 재구성하는 등의 후속 분석이 필요할 것으로 보인다. 또한 실시간 계측 시스템과 AI 기반 예측 모델의 연계를 통해 스마트 시공 관리 체계 구축에 기여할 수 있을 것으로 기대된다.
