

1. 서 론
2. 데이터 측정 및 전처리 방법
2.1 고속검측차량을 통한 궤도틀림 분석
3. 데이터의 이상치 분석 및 기여도
3.1 이상치 분석
3.2 기계학습의 최적화 과정
4. 가속도데이터를 이용한 TQI의 예측
4.1 적용모델
4.2 예측결과
5. 결 론
1. 서 론
최근 제4차 산업혁명의 키워드는 인공지능, 사물인터넷, 빅데이터, 증강현실 등 기존 기술 간의 경계를 허무는 융합기술로 발전되고 있으며 특히 빅데이터를 활용한 연구개발이 활발히 진행되고 있다. 기계학습 또는 머신러닝 기법은 비정형화된 데이터로부터 패턴을 학습하여 새로운 데이터에 적절한 작업을 수행하여 예측분석 등에 많이 활용되고 있다. 이러한 기법은 데이터를 통해 지식을 얻는 부분은 데이터 마이닝과 비슷하지만 데이터 마이닝은 주로 지식을 제공하는 반면 머신러닝은 충분한 데이터와 적합한 알고리즘을 이용하여 학습된 알고리즘으로 새로운 데이터를 예측할 수 있기 때문에 최적의 예측평가와 이를 자동적으로 처리하는 장점이 있다고 할 수 있다. 우리가 알고 있는 기계학습은 일반적으로 지도학습, 비지도학습, 강화학습으로 분류된다(Jeong and Jeong, 2019). 지도학습은 레이블이 있는 훈련데이터를 모델에 학습시켜 경험하지 못한 데이터에 대한 예측이 가능하도록 하는 방법이며, 비지도학습은 레이블이 없고 데이터의 의미를 정확히 알지 못할 경우에 데이터의 패턴을 찾고 의미를 추론하기 위하여 사용되고 있다.
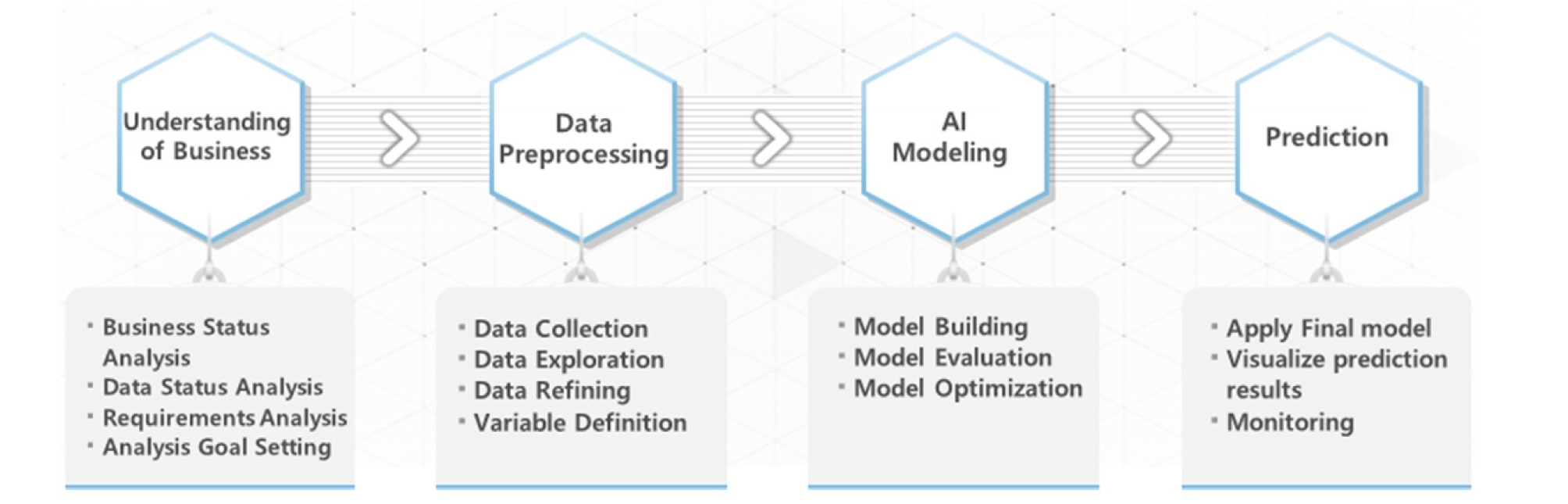
이러한 인공지능을 비즈니스에 적용하기 위해서는 먼저 현업관계자와의 원활한 커뮤니케이션을 통한 비즈니스 이해가 필요하다고 할 수 있다. 따라서, 비즈니스의 이해와 정확한 예측이 성립되기 위해서는 충분한 데이터군과 적합한 알고리즘을 선택하는 것이 중요하다고 할 수 있다. 이를 위해 기계학습을 위한 단계별 적용방안은 Fig. 1과 같다. Fig. 1에서와 같이 총 4단계의 절차로서 첫 번째 단계에서는 데이터의 현황, 요구사항 분석을 통해 분석목표를 설정하는 것, 두 번째 데이터 전처리 단계에서는 데이터를 수집 및 정제하고 분석에 의미있는 변수를 정의하여야 한다. 세 번째는 모델학습에서는 보유한 데이터와 분석목표에 맞는 알고리즘 사용하여 모델을 구축하고 평가를 통해 가장 최적화된 모델을 선택하여야 한다. 이러한 선행작업을 수행하면 마지막 예측단계에서는 최종적으로 선택한 모델을 적용하여 예측하고 시각화하여 예측결과의 활용하는 것이다.
철도분야에서도 다양한 계측자료를 바탕으로 머신러닝 기법을 이용하여 예측하는 시도가 점차적으로 증가하고 있는 실정이다. Jeong and Jeong(2019)은 레일 표면조도 데이터를 이용하여 전동소음 예측하여 정확도 향상시킬 수 있는 예측모델을 검토하였으며, Jung and Park(2018)은 차륜 및 차축베어링 고장진단 데이터를 기반으로 랜덤 포레스트모델을 이용하여 베어링과 차륜 부품의 고장진단을 예측하였다. 또한, 침목의 이상균열 패턴과 개소을 머신러닝을 활용하여 추정하였으며, 레일표면 조도데이터를 이용하여 전동소음을 예측한 다수의 논문이 발표되었다. 토목뿐만 아니라 신호통신과 전력공급장치인 전차선로를 대상으로 이상개소를 추출하는 연구도 진행되고 있다.
Lee et al.(2018)은 PC침목 균열을 영역 및 픽셀기반의 심층학습 기법을 이용하여 작은 침목균열에 대한 검지 가능성과 픽셀기반의 대상물 검지기법을 적용성을 평가하여 가능성을 확인하였으며, 경계검지기법의 적용방안을 제안하였다. Gibert et al.(2017)은 BB 모형에 기반한 영역기반 심층학습 기법(Region based Convolutional Neural Network)을 제안하여 궤도시스템내 각 부품의 탈락, 손상 및 균열 등에 대한 검지기법을 제안하였다. Lasisi and Attoh-Okine(2018)는 궤도품질지수를 머신러닝을 통해 예측하여 궤도유지관리에 활용 여부를 평가하였다. 국내에서는 궤도틀림과 차량의 검측데이터와의 상관성 연구가 일부 수행되고 있다(Kang, 2006; Woo et al., 2009). Choi et al.(2015)은 궤도틀림은 주행안전성에 영향이 크며, 궤도틀림에 따라 진동가속도의 방향성과 상호연관성이 높다는 것을 확인하였다. 이와같이 궤도의 상태평가에 영향을 주는 인자와 데이터를 활용하여 보수관리를 예측하는 기법 연구가 활발히 진행되어 철도 유지보수 기법에 적용 가능성이 높다고 하였다.
이 논문에서는 차량주행안전성 평가기준인 주행안전성을 UIC 518(2009)기준에 부합되는 차상가속도 데이터와 궤도틀림데이터를 통해 도출되는 궤도품질지수를 예측하여 데이터간의 상관성을 분석하여 기여도와 민감도 분석을 하였다. 이러한 결과를 바탕으로 3종류의 머신러닝 모델을 적용하여 궤도품질지수를 예측하는데 가장 정확한 모델을 확인하였다.
2. 데이터 측정 및 전처리 방법
2.1 고속검측차량을 통한 궤도틀림 분석
Fig. 2와 같이 차량진동가속도와 궤도품질지수를 예측하기 위하여 3가지 절차에 따라 분석영역을 확산하였다. 첫 번째로, 통계분석을 통해 각 데이터의 이상치를 살펴보고, 각 변수별 상관분석을 수행하였다. 두 번째로는 클러스터링을 통해 비슷한 습성을 가진 키로정을 군집화하였으며, 의사결정나무를 통해 궤도품질지수에 따른 차량진동가속도 규칙을 찾아내었다.
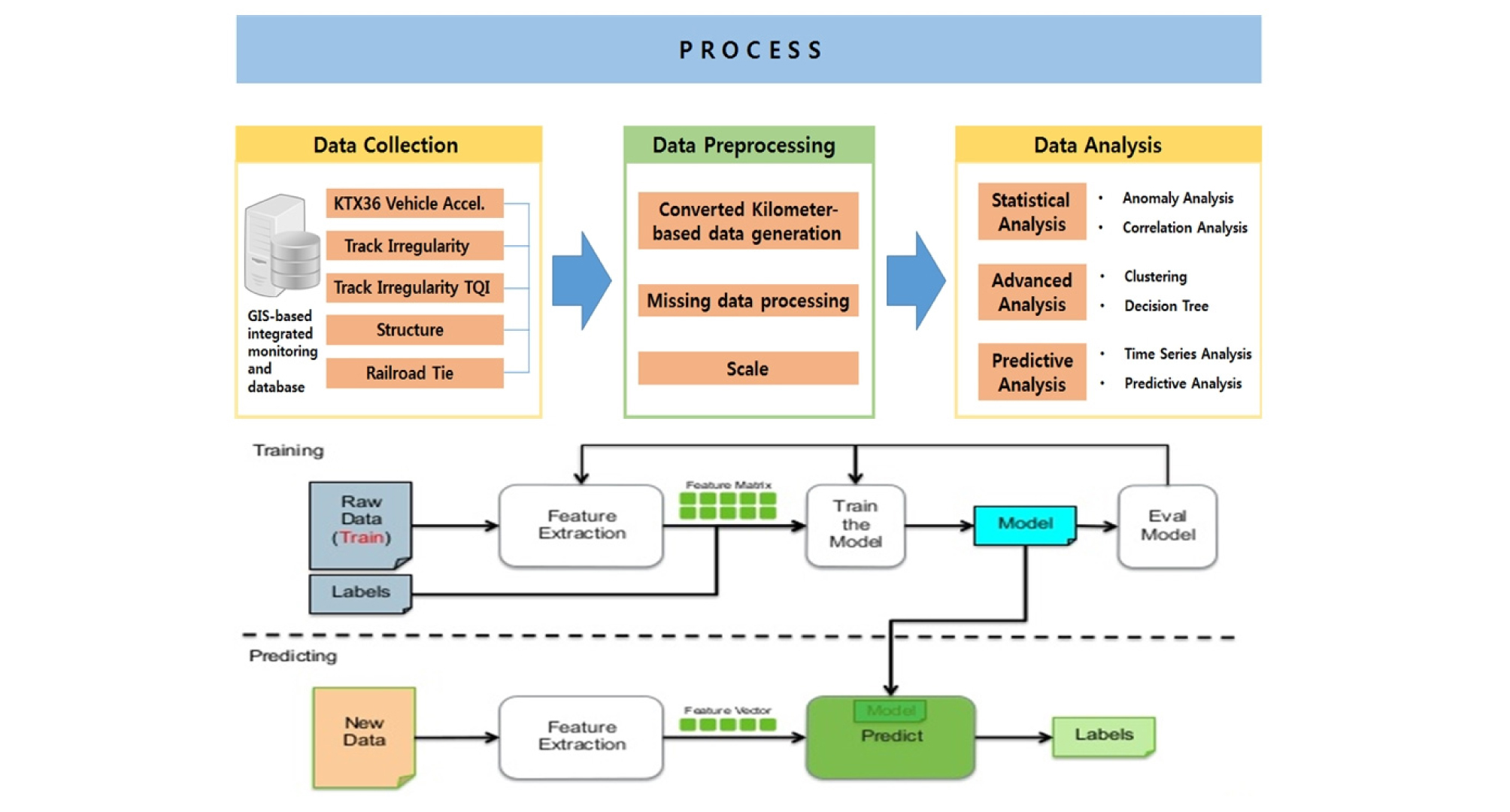
Table 1은 궤도틀림과 차량진동가속도와의 상관성에 대한 정리한 표이다. Choi et al.(2015)는 궤도틀림과 차량진동가속도간의 상관성을 검토한 결과 수평틀림은 차량의 롤링, 스웨이, 뒤틀림의 원인이 되고, 고저틀림은 차량의 피칭과 바운스를 유발하고, 방향틀림과 궤간틀림은 과도한 횡방향 힘을 유발하여 탈선과 궤도구성품의 손상의 원인이 된다고 알려져 있다.
Table 1. Relationship between domestic track irregularity and vehicle response [7]
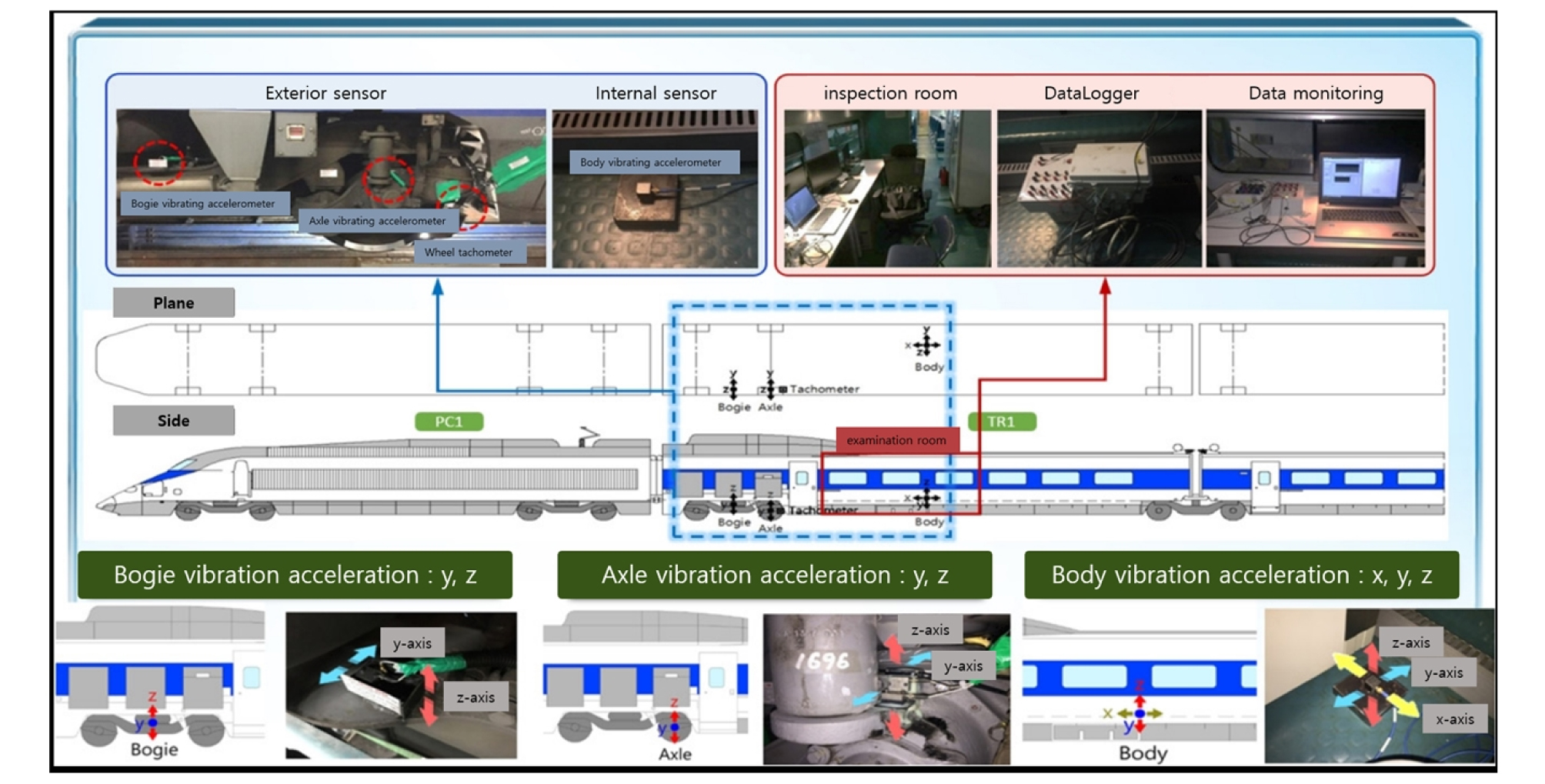
이 논문에서 차량진동가속도 측정방법은 UIC518에서 제안하고 있는 측정방법을 준용하였으며, 계측시스템의 구성과 센서는 Fig. 3와 같다. 계측지점은 KTX 열차에 차축과 대차 및 차체에 아래 그림과 같이 진동가속도계를 설치하고 위치를 파악하기 위하여 차량 내부에 GPS 안테나를 설치하고 차륜에 타코메터를 설치하였다. 차량진동가속도는 KTX열차에서 측정되고 궤도틀림값은 고속검측차량에서 측정되기 때문에 서로 다른 2개의 시스템에 대한 위치를 동기시킬 필요가 있다. 따라서 고속검측차량과 KTX열차의 GPS 안테나를 설치하고 시스템을 표준시간으로 설정하여 위치동기화를 구현하였다.
현재 운영기관에서 궤도상태를 파악하기 위해서 궤도의 속성이나 특성별로 동질성이 확보될 수 있도록 궤도품질지수로 평가하고 있다. 궤도품질지수는 200m 구간의 궤도틀림값을 표준편차와 평균값으로 산정할 수 있다. Table 2는 국내 선로유지관리지침에서 고속검측차량에서 20m 현방식으로 고저와 방향에 대한 표준편차 관리기준을 명시하고 있다. 궤도품질지수는 궤도의 품질상태가 좋을수록 즉, 궤도틀림 개소와 양이 적을수록 또는 계산된 실측길이가 짧을수록 작은 값을 갖게 되며, 이에 반해 궤도의 상태가 불량하면 높은 값을 갖게 된다.
Table 2. TQI Management Standard criteria
| Sort | 10 m Versine | 20 m Versine | ||
| Caution Criteria | Target Criteria | Caution Criteria | Target Criteria | |
| Vertical | 1.9 | 1.3 | 2.6 | 1.7 |
| Lateral | 1.5 | 1.0 | 2.1 | 1.4 |
수집된 데이터는 차량진동가속도와 궤도틀림값, 궤도품질지수로 구분된다. 대부분의 데이터가 킬로미터(km Point, KP)를 기준으로 수집이 되었으나 각 데이터에 따라 측정된 샘플링과 측정시간이 다르기 때문에 하나로 데이터를 통합하기에 어려움이 있다. 예를 들면 각 데이터의 샘플링은 차상진동가속도 초당 2kHz, 궤도틀림데이터 20m에 1개, 궤도품질지수는 20m에 1개의 데이터로 다르게 측정되었다. 본 논문에서 분석된 데이터는 거리로 1km 기준으로 데이터를 분석하였다. 또한 궤도틀림과 차량진동가속도 측정일자가 다르기 때문에 가장 근접하게 측정된 날짜와 데이터손실이 적은 선에서 데이터셋을 생성하였다. 분석된 계측자료 시간적 범위는 17년 6월부터 17년 12월로 6개월 측정된 데이터로 분석하였으며, 호남고속선 OO 상행선 일부구간 26km 구간에서 측정하였다. 차량진동가속도는 중간값 0에서 진동하기 때문에 최대와 최소값으로 분석하였으며, 궤도틀림은 평균, 최대, 최소값으로 정리하였다.
Table 3은 사용된 기호로 차축(Axle)가속도와 대차(Bogie)가속도, 차체(Body)가속도의 최대와 최소값과 궤도품질지수 궤간(Gauge), 뒤틀림(Twist), 줄틀림(Alignment), 수평틀림(Cant), 면틀림(Surface)으로 평균값으로 정의하였다.
Table 3. Definition of each symbol with measurement data in this study
3. 데이터의 이상치 분석 및 기여도
3.1 이상치 분석
이상치 분석은 통계모델링과 머신러닝 기반에서 많이 사용하는 분석방법으로 데이터에서 예기치 못한 이상치를 분석하여 예측결과에 영향을 미치는 요소를 식별하기 위하여 활용되는 기법이다. 특히 박스플롯은 데이터를 분석하기에 앞서 많은 데이터를 육안으로 확인하기 어려울 때 데이터 집합의 범위와 중앙값을 빠르게 확인할 수 있어 영향요소를 식별하는데 도움을 준다.
궤도틀림 종류별로 이상치를 분석하여 그 결과는 Fig. 4과 같다. 궤간틀림의 경우 다른 궤도틀림과 달리 정상값의 범위가 넓고 이상치가 나타나지 않는 것을 볼 수 있으며, 이러한 결과는 콘크리트궤도의 체결력이 양호하기 때문에 궤간 확대 및 축소가 되지 않고 유지관리가 매우 양호하게 관리되고 있다고 볼 수 있다. 고저틀림과 방향틀림은 정상치가 좁고 이상치가 발생하고 있는 것을 볼 수 있다. 고저틀림과 방향틀림은 완화곡선부에서 종단선형과 캔트체감 등으로 좌우 레일의 평면성을 저해하기 때문에 이러한 결과가 나타난 것으로 판단된다. 장기적으로 유지관리가 미흡할 경우 이러한 개소에서는 주로 차량의 좌우 유동이 발생하여 주해안전성과 승차감 측면에서 불리할 수 있다. 뒤틀림의 경우 정상값 범위는 매우 좁게 나타난 반면에 이상치가 넓게 분포되어 수평과 고저틀림의 평면성 틀림의 편차가 크게 발생하고 있다는 것을 알 수 있다. 이러한 이상치 분석을 통해 궤도틀림 종류별로 구간별 선형 상태를 간접적으로 평가할 수 있으며, 양호한 구간과 불량한 구간을 서로 비교하여 관리할 수 있을 것으로 판단된다.
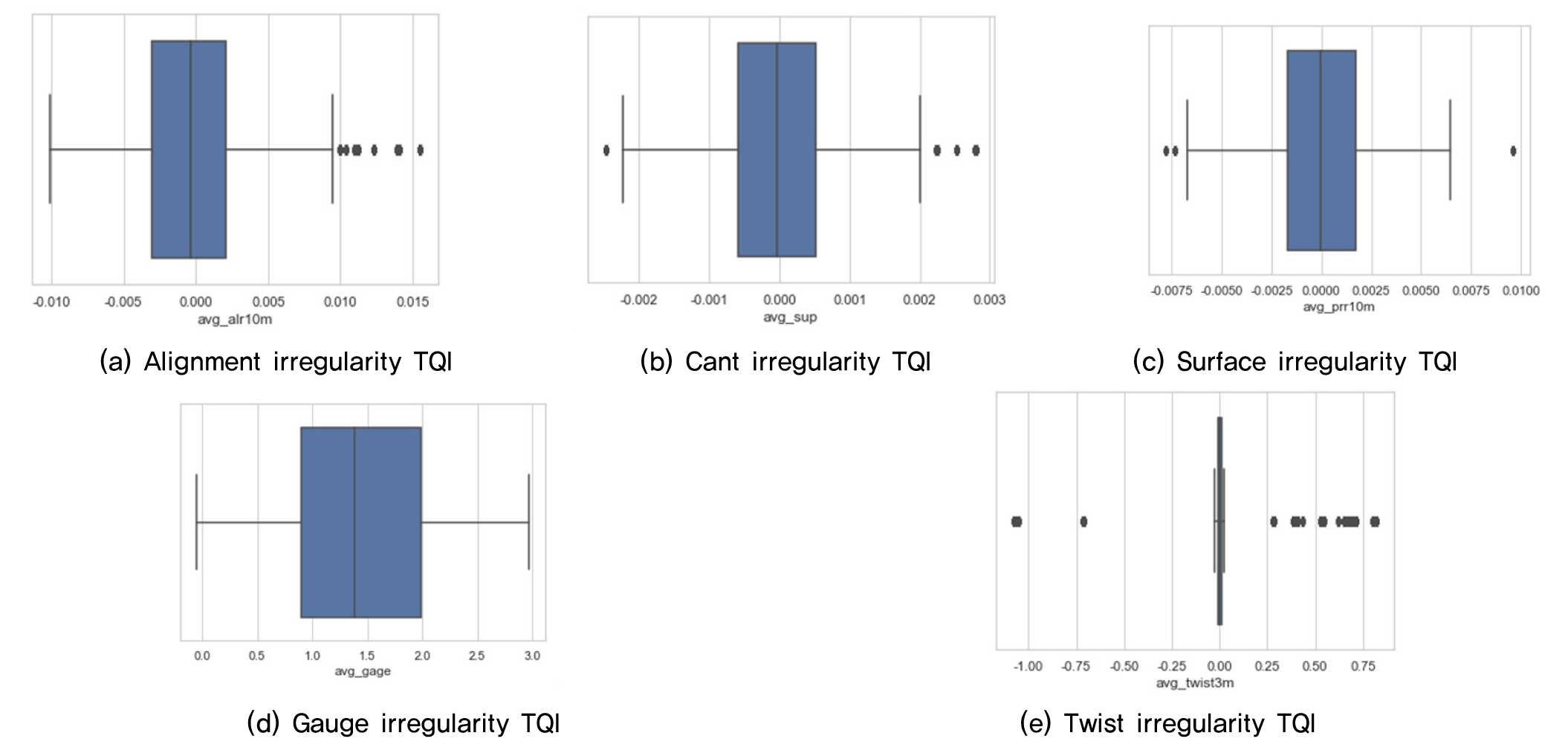
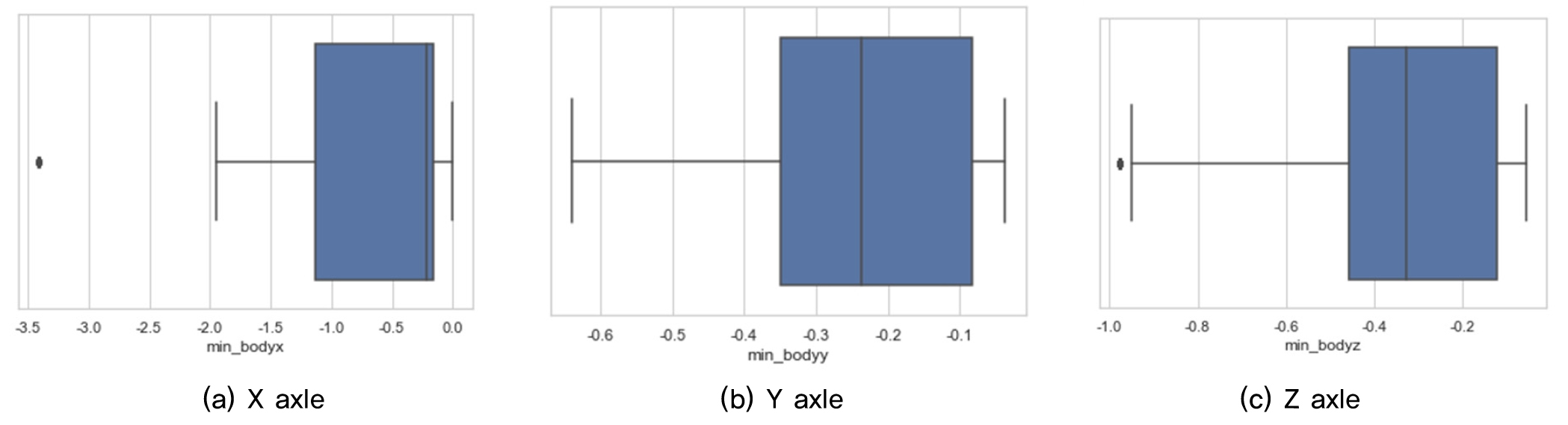
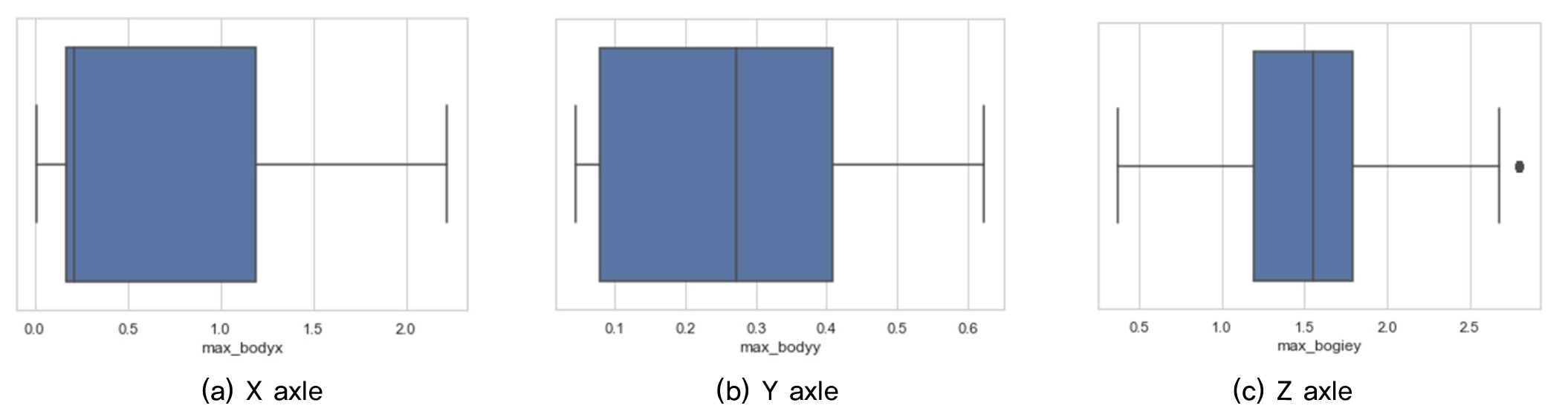
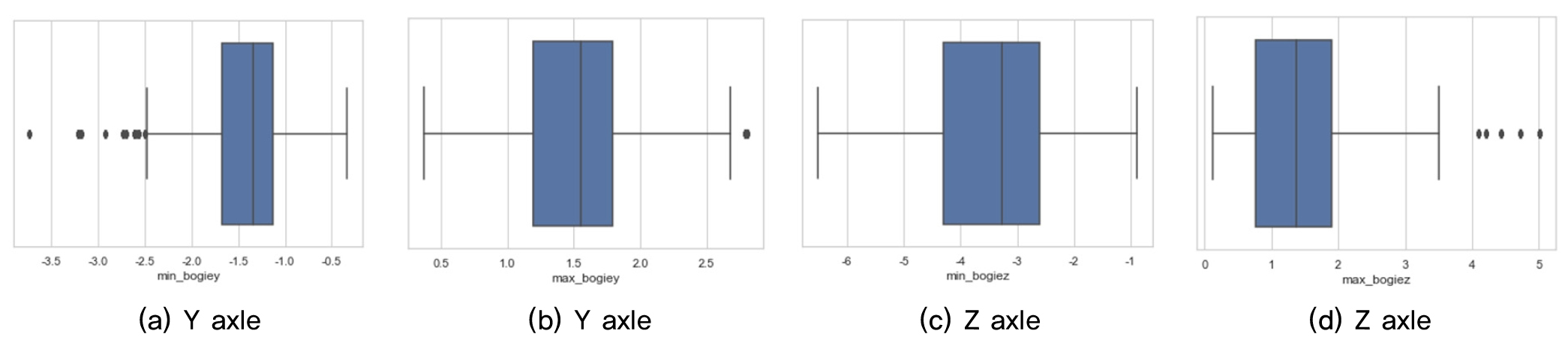
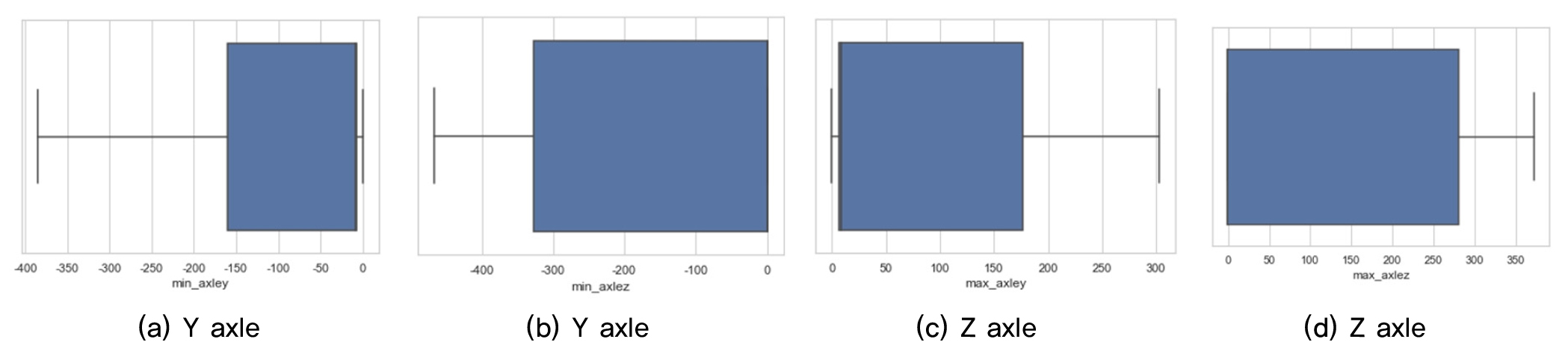
Fig. 5∼8는 차량진동가속도를 이용하여 박스플롯으로 이상치를 분석하였다. 총 14개의 변수 중에서 최소_윤축y, 최소_대차y, 최대_대차z의 3개의 데이터에서 이상치가 크게 나타났으며, 차체에 비해 윤축, 대차에서 크게 발생하였다. 특히 대차에서 가장 많이 발생하였다. 일반적으로 이상치가 많다는 것은 동일 데이터간의 편차가 크게 발생하는 것으로 해당 구간내에서는 윤축보다 대차가속도가 더 민감도가 높은 것으로 분석되었다. 차량의 대차는 두 개의 윤축으로 고정축거로 되어 있기 때문에 곡선부와 선형적으로 불리한 구간에서는 대차의 좌우 유동이 다르게 측정될 수 있다. 따라서 이상치 편차가 크게 발생한 것으로 판단된다. 향후 대차와 윤축의 가속도가 선형조건에 따라 어떻게 변화되는지를 종합적으로 면밀한 특성을 파악하여야 할 것으로 판단된다.
3.2 기계학습의 최적화 과정
차상에서 측정된 가속도데이터와 궤도틀림과의 상관도를 분석하여 각 변수 사이에 상호 관련성의 강도를 파악하였다. 분석하고자 하는 데이터가 수치형이므로 스케일링을 통한 정규화를 통하여 데이터 처리를 하였으며, 스케일링은 자료의 overflow나 underflow를 방지하고 독립 변수의 공분산 행렬의 condition number를 감소시켜 최적화 과정에서의 안정성 및 수렴속도를 향상시켰다. 스케일링의 경우 이상치 값에 영향을 많이 받을 경우 Robust Scale을 적용하는 것이 유리하기 때문에 해당 알고리즘을 적용하여 정규화하였다. 일반적으로 상관계수가 0.95 이상인 변수를 제거하지 않으면 분류에 주요한 영향을 미치는 변수가 분리 조건에 나타나지 않는 다중공선성(Multicollinearity) 문제가 발생할 수 있기 때문에 이를 고려하였다.
Fig. 9은 각 변수간의 상관관계 결과이다. 그림에서와 같이 차량진동가속도에서 측정된 값과 궤도틀림간의 상관도가 0.95를 넘는 변수는 윤축 z방향(min_axlez)의 최소값, 대차 x방향(max_bodyx)의 최대값, 윤축 y방향(max_axley)의 최대값, 윤축 z방향(max_axlez)의 최대값, 방향틀림(avg_alr10m)으로 분석되었다. 이러한 상관도를 통해 차량진동가속도 최소값과 최대값 사이에 상관관계가 높게 나타나는 것을 볼 수 있다. 또한 궤간틀림(avg_gage, max_gage, min_gage)은 다른 틀림에 비해 차량진동가속도와 상관관계가 높음을 알 수 있다.
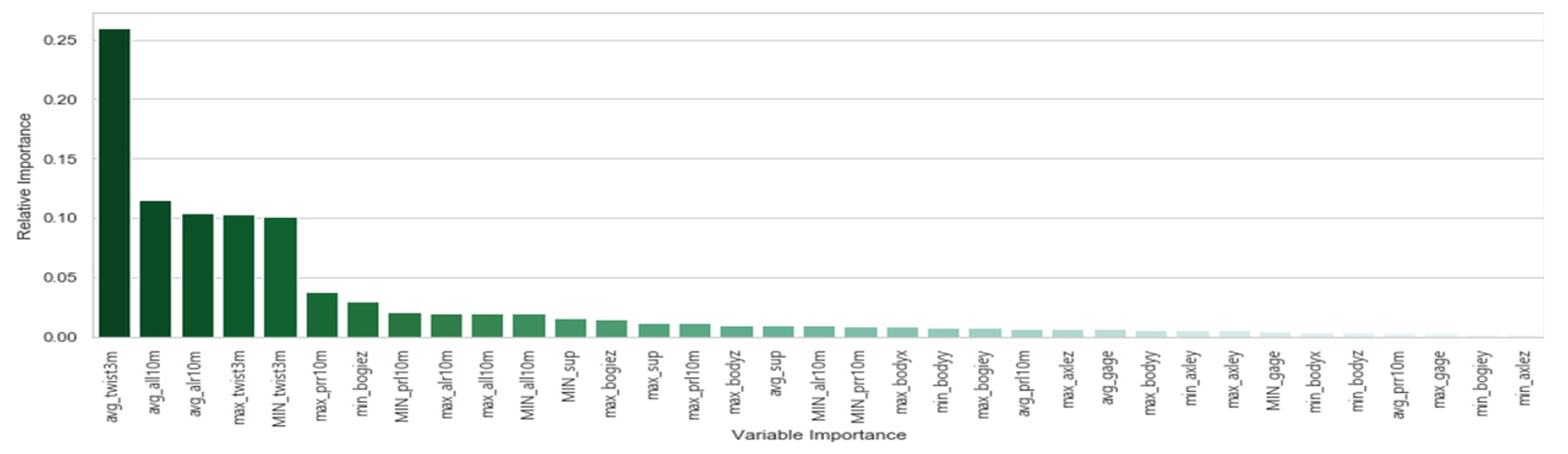
4. 가속도데이터를 이용한 TQI의 예측
4.1 적용모델
이 논문에서 차량진동가속도 데이터를 이용한 궤도품질지수를 예측하기 위해 기계학습 모델은 랜덤포레스, 서포트 벡터머신, XGboost 3개의 모델을 적용하였다. 랜덤포레스트는 앙상블 학습기법을 사용하는 대표적인 트리구조의 감독학습 모델로서 배깅 접근 방식을 사용하는 대표적인 머신러닝의 트리구조 알고리즘이다. 서포트 벡터머신은 패턴 인식, 자료 분석을 위한 지도학습 모델이며, 주로 분류와 회귀 분석을 위해 사용한다. 두 카테고리 중 어느 하나에 속한 데이터의 집합이 주어졌을 때, 서포트 벡터머신 알고리즘은 주어진 데이터 집합을 바탕으로 하여 새로운 데이터가 어느 카테고리에 속할지 판단하는 비확률적 이진 선형 분류 모델을 만든다. 만들어진 분류 모델은 데이터가 사상된 공간에서 경계로 표현되는데 서포트 벡터머신 알고리즘은 그 중 가장 큰 폭을 가진 경계를 찾는 알고리즘이다(Nakhaee and Hiemstra, 2019; Cortes and Vapnik, 1995; Vapnik, 2000). XGboost는 선형모델이나 Tree 기반 모델에서 과적합 문제를 해결하고 규모가 큰 데이터셋의 안정성과 훈련 속도를 향상시키기 위한 목적으로 boosting 알고리즘기반 모델이며, 회귀와 분류, 순위 및 사용자 정의 대상물을 지원하는 유연한 모델이라고 알려져 있다(Chen and Guestrin, 2016).
예측하기 위하여 먼저 일자와 키로정을 기준으로 차량진동가속도와 다양한 궤도틀림데이터를 합한 데이터셋 1과 궤도품질지수 데이터를 합한 데이터셋 2를 생성하였다. 각 데이터셋은 각각 5,778건이며, 일자, 키로정별로 생성한 통계치를 활용하였다. 예측 모델 학습 데이터는 일반적으로 많이 적용하고 있는 비율인 차량진동가속도 데이터를 7:3 비율로 분할하여 학습데이터는 4,333건, 테스트데이터는 1,445건으로 분할하였다. 학습을 위한 데이터는 할당된 데이터는 데이터 스케일링을 통한 정규화하였다.
4.2 예측결과
Table 4는 각 예측모델별로 예측값의 정확도를 나타내었다. 표에서와 같이 모든 데이터셋에서 대부분 85%이상으로 XGBoost가 가장 정확도가 높게 나타났으며, 랜덤포레스트도 서포트 벡터머신에 비해 정확도는 높은 편이나 XGBoost보다는 낮게 예측되었다. 이러한 이유로는 단일 알고리즘인 서포트 벡터머신와 달리 랜덤포레스트와 XGBoost는 앙상블 방식이기 때문에 예측 성능이 좋게 나타난 것으로 판단된다. 또한 궤간 궤도품질지수는 다른 궤도품질지수에 비해 낮은 정확도가 보이는 데 차량진동가속도가 궤간 궤도품질지수를 예측하기에 적절하지 않은 변수이거나 변수 변별력이 낮기 때문으로 판단된다.
차상진동가속도 데이터를 활용하여 궤도품질지수를 예측한 결과에서 각 예측값에 데이터의 기여도가 크게 기여한 측정값을 순서대로 정리하면 Table 5와 같다. 표에서와 같이 고저 궤도품질지수의 경우 윤축과 대차의 z축의 가속도에 영향이 큰 것으로 나타났으며, z축 가속도는 상하방향으로 진동하는 값으로 차량진동가속도를 통해 예측결과가 연관성이 매우 높은 것을 알 수 있다. 기존 연구(Choi et al. 2015)에서도 차체상하가속도(z)는 고저틀림의 영향을 준다는 기존 연구결과와도 잘 일치하는 결과로서 차량진동가속도를 기반으로 궤도품질지수를 예측할 수 있을 것으로 판단된다.
Table 4. Results of accuracy of each prediction value
| Model | Surface TQI | Track gage TQI | Twist TQI | Alignment TQI | Cant TQI |
| RF | 0.50 | 0.30 | 0.43 | 0.54 | 0.53 |
| SVM | 0.07 | 0.07 | 0.37 | 0.10 | 0.38 |
| XGB | 0.93 | 0.43 | 0.94 | 0.93 | 0.95 |
Table 5. Summarized of Feature importance
5. 결 론
본 논문에서는 차량진동가속도를 이용하여 궤도품질지수를 머신러닝 기법을 활용하여 예측하여 다음과 같은 결론을 도출하였다.
(1) 고저 궤도품질지수의 경우 상하방향의 궤도틀림으로 윤축과 대차의 z축 방향의 차량진동가속도와상관도가 높은 것으로 분석되었으며, 이러한 결과는 기존 연구결과와도 잘 일치하였다.
(2) 궤도품질지수 예측 정확도는 XGBoost 모델을 적용한 것이 가장 높게 나타났으며, 다음으로는 랜덤포레스트, 서포트 벡터머신 순으로 분석되었다. 차량진동가속도를 통해 궤도품질지수를 예측하기 위해서는 단일알고리즘 방식인 서포트 벡터머신보다는 앙상블 방식의 모델인 랜덤포레스트와 XGBoost를 적용하는 것이 적절한 것으로 판단된다. 따라서 차량진동가속도를 통해 충분히 궤도품질지수를 예측할 수 있을 것으로 판단되며, 향후 분석구간을 좀 더 세분화하여 예측 정확도를 높일 수 있는 방안이 필요할 것으로 판단된다.
