

1. 서 론
2. 본 론
2.1 추계론적 해석
2.2 베이지안 업데이팅(Bayesian Updating)
2.3 구조 형상에 대한 위상 최적화(Topology Optimization)
3. 해석 예제
3.1 해석 모델 및 방법
3.2 해석 결과
4. 결 론
1. 서 론
지반구조물 해석은 일반적으로 결정론적 방법(deterministic method)과 확률론적 방법(probabilistic method)으로 구분된다. 지반구조계 내·외에 존재 가능한 여러 가지 인수들이 일정한 정량적인 값을 가진다는 가정하에 각 인수들은 하나의 상수들로 대표되고(여기서, 해석 인수들은 이후에 언급되는 확률론적 해석의 측면에서 보면 각 해석 인자들에 대한 평균치로 볼 수 있다(Choi and Noh, 1993), 어떤 특정한 입력이 들어오면 똑같은 과정을 거쳐서 언제나 동일한 결과를 내놓는 효율적인 방식으로 가장 오랫동안 연구되어온 단순하고 친숙한 방법이다. 하지만 실제 지반구조물의 경우, 해석인수들은 지반구조계 영역 내에서 일정한 정량적인 값을 가진다고 가정하는 것보다 위치벡터에 따라 다른 값을 가지고 있다고 가정하는 것이 합리적일 것이다. 확률론적 방법은 “데이터 집합에 대한 명확한 표현이 임의적이어서 미래 예측은 불가능하다.”라고 생각하고, 오직 통계적인 방법으로 확률적으로 모형화하여 이를 추정한다. 지반구조물 해석에서의 확률론적 방법은 재료적 인수, 경계조건, 작용하중, 부재의 기하학적 형상인수 등이 임의성을 가진다는 가정하에 어떤 통계적 특성을 가진 임의표본을 수치적으로 생성하고, 생성된 표본 샘플들에 대한 결정론적 유한요소해석을 반복적으로 수행하여, 지반구조물 거동의 특성을 얻는 방법이다. 이때의 대표적 통계처리 방법이 몬테카를로 방법(Monte-Carlo techniques)이다(Chakraborty and Bhattacharyya, 2002; Schuёuller, 2007).
지반구조계의 임의성은 수치적으로 고려할 때, 측정상의 임의성, 통계적 임의성 및 수학 모델의 임의성, 그리고 내재적 임의성 등으로 분류된다(JCSS, 2001). 실험으로 얻은 데이터를 통해 불확실인수를 확립하는 과정에서 발생할 수 있는 모든 경우를 측정상의 임의성이라 하며, 통계적 임의성은 얻어진 정보들이 시간적 및 공간적으로 제한되어 있음에 의하여 나타나는 자료부족에 의해 나타나는 임의성을 의미한다. 또한, 불확실 인수의 실제적 형태와 이를 모사하는 수학적 모델링 사이의 상이함에 나타나는 임의성을 수학 모델의 임의성이라 한다(Noh, 2004). 내재적 임의성은 지반구조물 재료, 지반구조물의 형상과 관련이 있는 기하인수, 그리고 작용하중 등에 나타나는 임의성을 의미하며, 지반구조물 인수의 자연적 특성 중의 하나라고 할 수 있다(Choi and Noh, 1996; Noh and Lee, 2006). 기술된 임의성은 실제 지반구조물 거동에서 모두 고려되어야 하지만, 거동에서 영향도가 가장 크다고 볼 수 있는 내재적 임의성을 추계론적 유한요소해석(stochastic FEM; SFEM)에서 주로 다루고 있다. 추계론적 유한요소해석은 추계론적 해석과 유한요소법을 조합한 해석법으로 지반구조시스템 내의 지반구조계 인수들에 나타나는 공간적, 시간적 임의성에 대한 지반구조물의 불확실 응답에서의 변화도 산정을 목적으로 한다(Thuan and Noh, 2018).
추계론적 유한요소해석은 해석 방법론의 관점에서 통계학적 방법과 비 통계학적 방법 두 가지로 대별되며, 현재의 통계학적 방법은 Fig. 1과 같다. 대상 확률 변수는 특정 정규분포를 만족하며, random process는 pseudo time process를 이용하여 얻게 된다. (이때, 확률변수는 을 만족한다) 생성된 상수장(constant field) 형태의 인수는 결정론적 방법의 입력값이 되며, 결정론적 해석을 반복수행하고, N개의 해석결과에 대한 통계처리 방식이 현재의 통계학적 방법이다. 그러나, Fig. 1과 같은 재료를 예로 들면, 실제 재료의 인수는 위치벡터에 따라 같은 값을 가진다고 보기 어렵다. 따라서 상수장(constant field)을 사용하는 현재의 방식은 실제 재료를 제대로 모사했다고 할 수 없다. 그러므로 통계적 방법의 임의표본은 Fig. 2와 같이 통계적 특성을 나타내는 확률밀도함수(Probability Density Function)와 공간적 분포상황을 표현하는 스펙트럼밀도함수(Power Spectral Density Function)를 만족시켜야 한다.
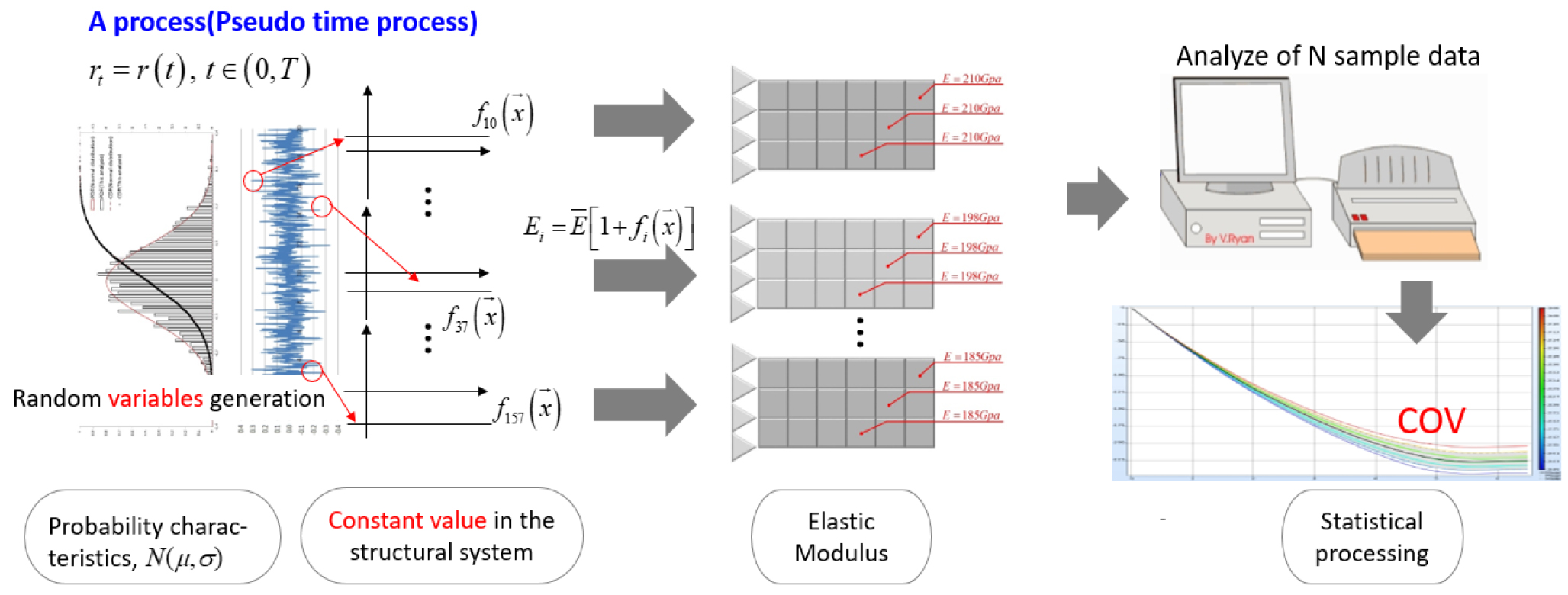
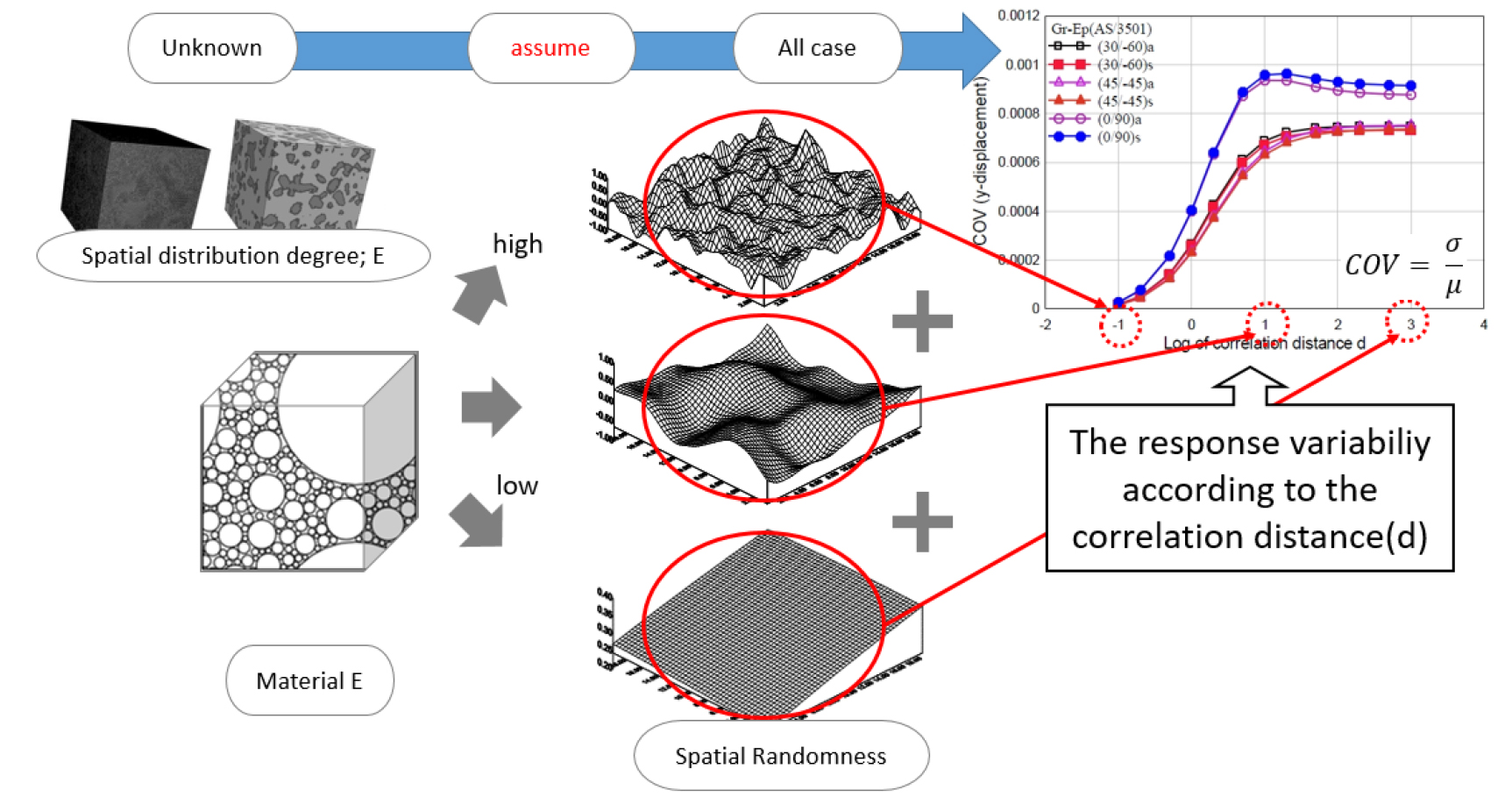
일반적으로 이 두 함수를 수치적으로 동시에 만족시키는 정확한 임의표본의 생성(모델링)에 어려움이 있다. 또한, 두 함수를 만족시키는 임의표본을 생성했다 하더라도 실제 지반구조물이 어느 정도의 임의성을 가지고 있는지를 수치적 계수로 나타내는 것은 어려움이 있다. 그래서 모든 경우(모든 스펙트럼)에 대한 해석이 요구되며 이에 해당하는 모든 스펙트럼의 응답변화도 산정(결과 값)은 매우 비효율적이다. 예를 들어 Fig. 2와 같이 스펙트럼의 공간적 분포 정도(불확실인수의 불확실 정도)를 표현해주는 상관거리(d)에 따른 변동계수(COV=표준편차/평균; 결과값)를 찾아낼 수는 있지만, 해당 지반구조물에서 사용되는 상관관계 거리(d)를 알 수 없으므로 임의성이 작은 d부터 임의성이 큰 d까지의 범위를 가지는 응답변화도 해석을 수행해야 한다. 또한, 대상 지반구조물 재료의 실제 d를 모르기 때문에 결과 역시 의미가 높다고 볼 수 없다.
앞서 언급했던 공간적 분포를 고려하지 않은 현재의 통계적 방법은 이 두 함수(스펙트럼 밀도함수, 확률밀도함수)를 고려한 해석에서 보았을 때, d=∞일 때라 볼 수 있다(상관거리 d가 무한대가 되면, 장(field)은 하나의 확률 변수 상태가 된다). 그리고 d=∞일 때의 응답변화도 변동계수(COV)가 현재의 통계학적 방법의 결과값이라 볼 수 있다. 하지만 만약 Fig. 2처럼 실제 지반구조물 재료의 상관거리가 무한대가 아니고, 거동의 최대 변동 값도 무한대가 아닌 지점에서 나타난다면 현재의 통계학적 방법은 실제보다 과소평가 된 것이다. 반대로 실제 지반구조물 재료의 상관관계 거리가 d=0이라면, 과대평가된 것이다. 따라서 현재의 통계학적 결과 또한 의미가 높다고 할 수 없다.
2. 본 론
본 연구의 경우 실제 샘플들의 특정 부분들을 계측하여 얻은 실험데이터 값을 이용하여 탄성계수의 공간적 임의성을 나타내는 계수를 찾는 것이 목적이다. 하지만, 실제 재료의 시험/계측을 통해 재료의 공간적 임의성을 정확히 판단하기는 쉽지 않다. 왜냐하면, 정밀한 기계로 계측시험을 하더라도 계측 센서 사이 간 거리가 발생하고, 그 사이의 재료 요소가 가지고 있는 임의성은 알기 어렵기 때문이다. 또한, 모든 재료영역()에서 계측은 시간, 혹은 비용 등의 이유로 불가능하다. 따라서, 실제 재료가 아닌 일반적으로 추계론적 해석에서 사용되는 추계장 생성 알고리즘을 만들어 재료 샘플이 가진 공간적 임의성을 모사하였다. (알고리즘을 적용해서 재료 샘플을 만드는 목적은, 알고리즘을 통해서 그 샘플들에 해당하는 정확한 d 값을 알고 있기 때문이다. 제시한 역 해석방법이 그 d를 제대로 추적해 낸다면, 실제 지반구조물 재료의 일부 데이터를 이용해서 그 지반구조물 재료에 해당하는 d를 얻을 수 있다는 가정에서 시작된다.)
2.1 추계론적 해석
추계론적 해석에서는 지반구조시스템 내의 해석 인수들이 시간과 공간적으로 임의성을 가지고 있다고 가정하고, 이들을 해석에 고려하여 결정론적인 가정으로부터 얻게 되는 지반구조물 응답의 평균치와 공분산을 얻는다. 여기서, 지반구조물 응답의 평균치는 해석인수의 대푯값을 사용한 결정론적 해석을 통하여 얻은 것과 같을 수 있다. 가정되는 확률장이 정규분포일 경우 확률장은 평균과 표준편차로 표현될 수 있다.
여기서, , : 직교하는 미소증분
, : 상호 직교 프로세스(real processes)
: 파수(wave numbers)
재료탄성계수의 공간적 임의성은 Shinozuka and Deodatis(1996)의 스펙트럼 모사법을 적용하여 2D-1V(2-dimensional uni-variate)의 추계장 를 생성하여 식 (1)와 같이 표현할 수 있다. 여기서, 추계장 는 평균 0과 표준편차 0.1을 가지는 것으로 가정하였고, 확률밀도는 정규분포로 가정한다. 는 평균탄성계수를 의미하며, 는 추계장의 순번을 나타낸다(Kim et al., 2020).
2.2 베이지안 업데이팅(Bayesian Updating)
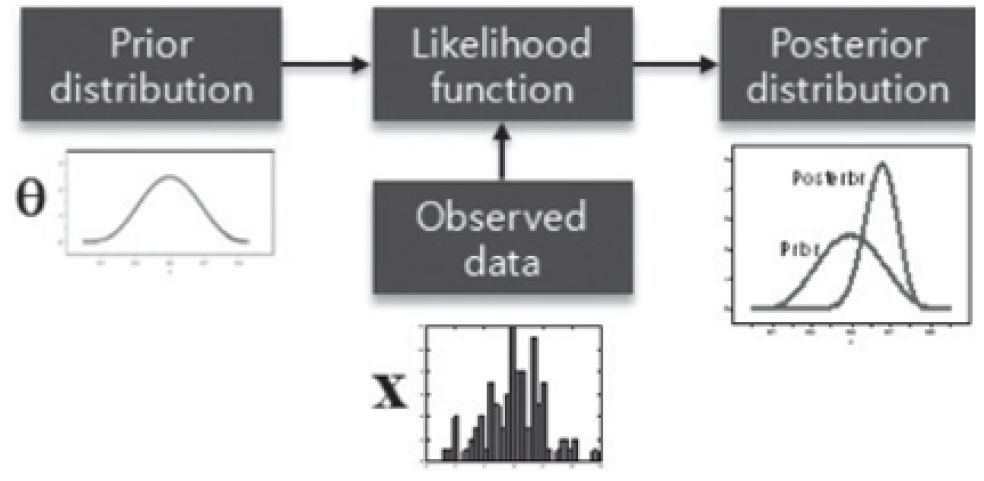
확률 · 통계이론은 크게 두 가지 빈도주의적 접근법와 베이지안 접근법으로 대별된다. 두 방식의 차이점은 빈도주의적 방법에서에서는 모집단을 변하지 않은 대상으로 규정한다. 하지만, 베이지안의 경우 모집단을 미리 확정짓지 않는다. 이전의 경험과 현재의 증거를 토대로 어떤 사건의 확률을 추론하는 과정을 보여준다.
베이지안 확률이론은 다음의 식 (5)와 같다. 사후확률은 우도함수와 사전확률의 곱으로 표현된다. 여기서 는 의 사전확률(prior distribution for the data)을 의미하며, 는 사건 가 주어졌을 때 데이터의 조건부확률(sampling density for the data), 즉 알려진 결과(관찰된 결과)에 기초한 어떤 가설에 대한 가능성을 의미한다. 마지막으로 는 사후확률이라 하며 Fig. 3과 같이 표현할 수 있다(Wei and Conlon, 2019).
2.3 구조 형상에 대한 위상 최적화(Topology Optimization)
본 논문에서는 Sigmund(2001)의 SIMP법을 이용하여 재료 물성치의 임의성을 고려한 구조 형상에 대한 위상 최적화를 수행하여 결정론적 위상 최적화 결과와 비교한다. 기존의 결정론적 위상 최적화에서는 Fig. 4(a)에서 보이는 바와 같이 전체 설계영역을 사각형 유한요소를 사용하여 모델링하고, 모든 유한요소에 동일한 값의 탄성계수를 적용하여 목적함수인 컴플라이언스(compliance)의 최소화를 통해 위상 최적화를 수행한다(Bendsøe and Sigmund, 2003). 반면, 본 논문에서는 Fig. 4(b)에서 보이는 바와 같이 각 유한요소별로 상이한 탄성계수를 적용하여, 탄성계수의 공간적 임의성을 고려하여 구조 형상에 대해 위상 최적화하는 방법이다.
여기서, : 요소 e의 재료밀도
: 탄성계수
: 빈 요소(void element)
p : penalization factor
: (전체) 강성행렬
: 전체 및 요소 변위벡터
: 분할된 총 요소(e)들의 수
: 부피율
: 재료체적 / 설계영역체적
: 국부체적비(local volume fraction)
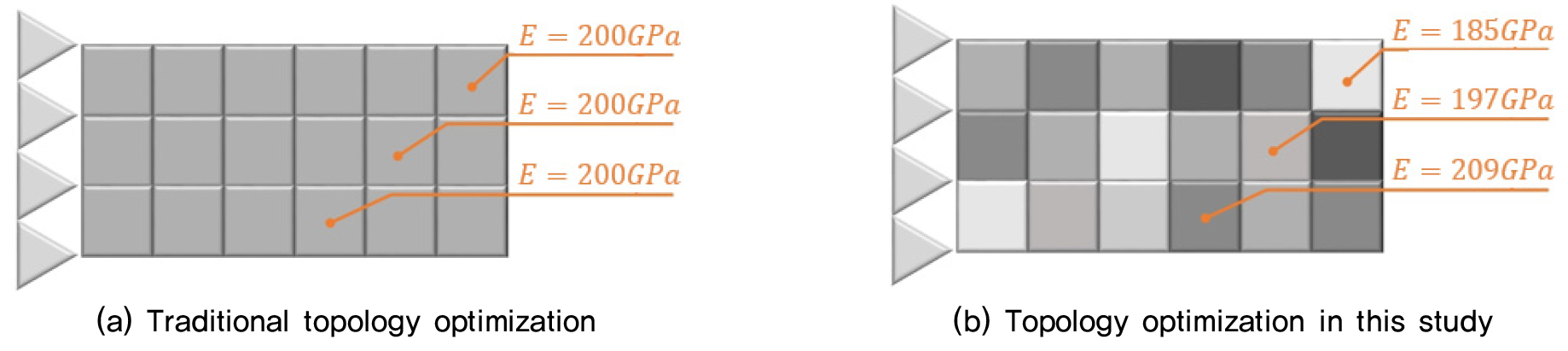
반복해석을 통해 목적함수인 컴플라이언스의 최소치를 찾는 과정에서 각 요소 e의 재료 밀도를 라 할 때, 요소별 재료탄성계수 와 최소화를 위한 목적함수인 최소 컴플라이언스는 다음과 같이 식 (6), (7)로 나타낼 수 있다. 앞서, 위상최적화는 주어진 재료량을 제한조건 내에 최적의 재료분포를 찾는 설계기법이라 하였다. Fig. 4과 같이 여기서 말하는 재료량이란 유일한 설계변수로서 재료의 밀도를 의미하며, 재료가 공간상에 배치되는 것을 표현하기 위한 가상의 값으로 재료가 배치되지 않아야 할 부분의 요소들은 밀도가 0, 혹은 0에 가까운 값을 가지고 반대로 재료를 배치해야 부분은 1의 값을 가지게 모든 요소에 대해서 재료 밀도가 0~1로 정해지면 전체적인 재료분포, 레이아웃이 결정된다. 또한, 는 해석 시 U=K-1F의 K-1값의 ‘0/0꼴’을 피하기 위하여 정의된 빈 요소 탄성계수 값이다. 설계인수 중 하나인 penalization factor는 사용자가 설계 시 재료 밀도(0~1)를 눈으로 충분히 구분할 수 있도록 설정하는 값이다. 보통 3.0정도 내외의 값을 사용하고, 만약 p값이 너무 크면 최적설계측면에서 볼 때 비경제적이므로 주의해야 한다. 는 (전체)강성행렬이며, 는 전체 및 요소 변위벡터, 은 분할된 총 요소(e)들의 수들을 의미한다. 또한, 설계제약인 부피율 는 식 (8)과 같이 재료체적인 와 설계영역체적인 의 비로 나타낸다. 국부체적비는 전체 요소 영역에 대한 합으로 처음 설계제약의 값으로 표현된다.
3. 해석 예제
3.1 해석 모델 및 방법
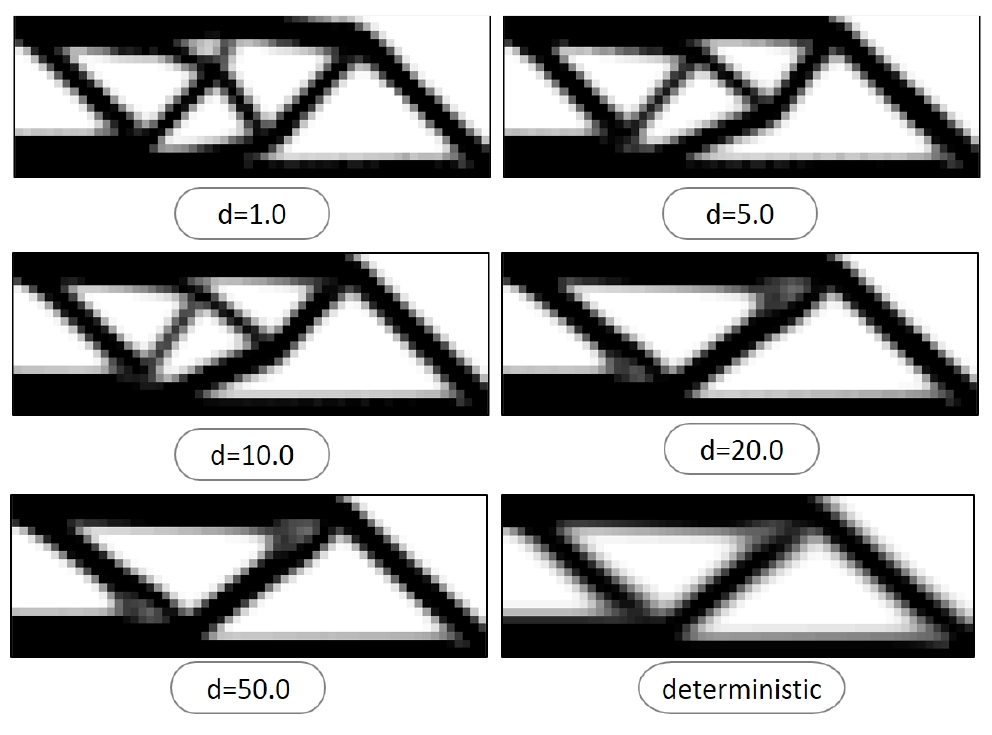
재료샘플을 모사한 탄성계수 추계장은 각 요소 당 0.5 단위길이()의 X-방향 60개, Y-방향 20개, 총 1,200개의 요소로 30×10 길이()를 가지며(여기서 길이는 무차원임) 불확실 정도에 따라 d=1, 5, 10, 20, 50의 총 5종류의 샘플의 각 3,000개씩을 생성(100개만 사용)하였다. 또한, 위상최적화를 위한 모델은 Fig. 5(a)와 같이 해석모델은 집중하중이 작용하는 단순보 모델을 해석하였다. 지반구조물의 성질은 탄성계수 1.0MPa, 하중 1.0, 부피율 50%로 가정하였으며, 해석 시간을 줄이기 위해 지반구조물 및 작용하중의 대칭성을 고려한 대칭 모델 MBB-Beam을 사용하였다. 본 연구는 설계인수의 공간적 임의성을 고려하는 확률적 해석으로서 지반구조물의 대칭성을 적용할 경우 재료의 대칭성을 동시에 전제하게 되나 이에 의한 결과의 오차는 크지 않은 것으로 가정하고자 하며, 이러한 대칭모델의 적용은 동일한 가정하에서 적합한 것으로 용인되어 적용되고 있다(Noh and Yoon, 2017).
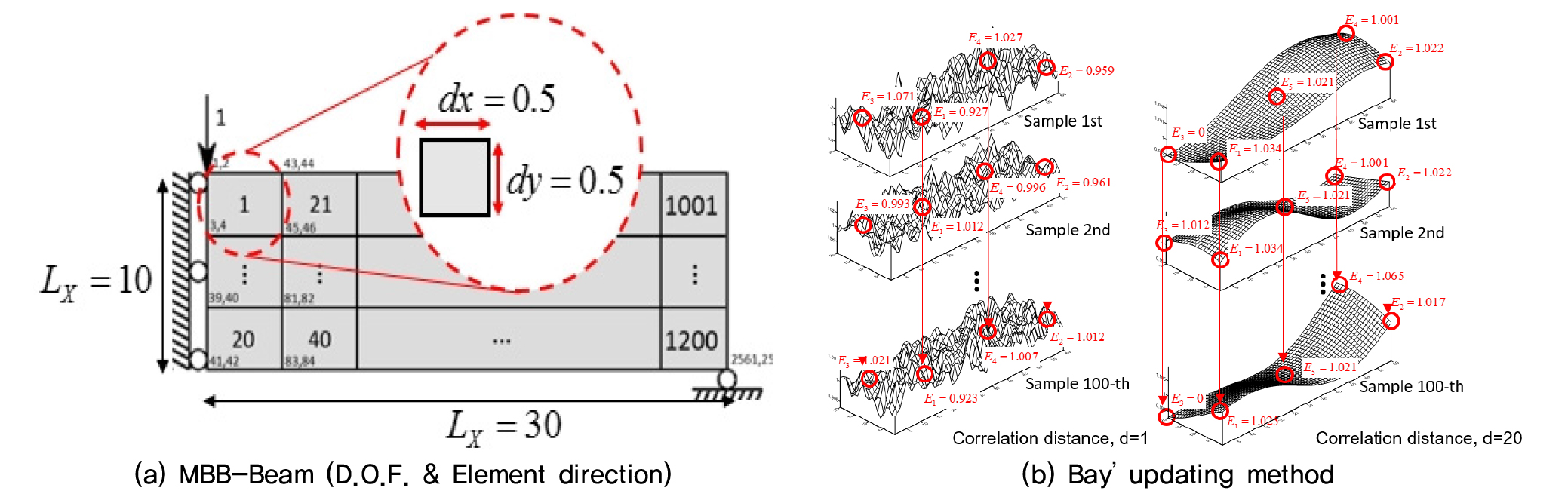
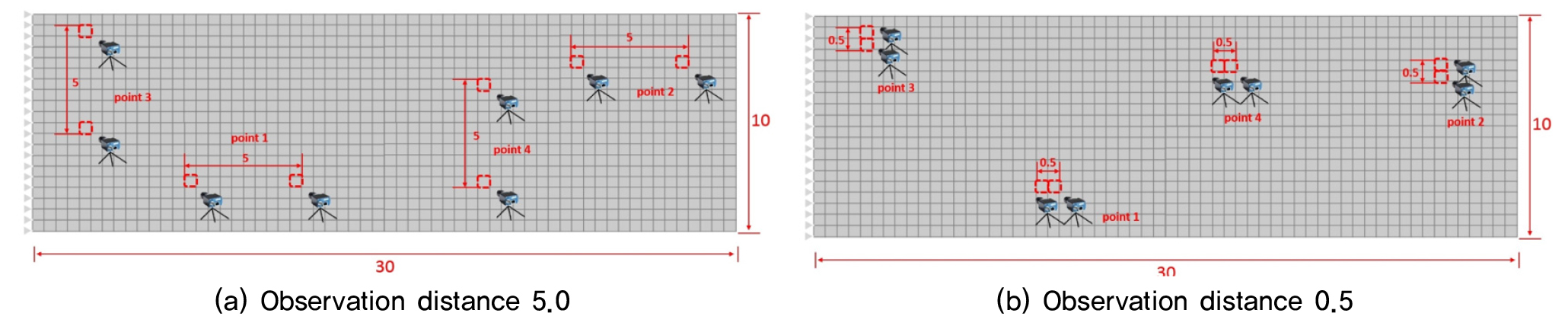
계측방법은 Fig. 6과 같이 위치와 방향(X, Y)에 상관없이 두 점의 거리만을 고려한다. 종류별 각 100개의 추계장에 X-방향의 두 지점과 Y-방향의 두 지점, 총 네 지점의 상관거리에 따라 거리별 두 위치 차의 최댓값을 찾는다. 계측 거리가 다른 계측방법을 Fig. 6에 나타내었다. 재료의 확률특성(평균, 표준편차)은 Fig. 5(b)와 같이 각 샘플의 관측 위치로부터 직교방향으로 종류별로 총 100번의 업데이팅을 수행하였다.
3.2 해석 결과
샘플데이터 추계장을 관측 거리별로 Table 1과 Table 2에 나타내었다. 여기서, X축은 탄성계수 추계장 상관거리가 다른 d=1부터 5, 10, 20, 50까지의 5종류별로 실험하였고, Y축은 각 Fig. 6과 같이 단위길이가 0.5인 추계장의 무작위 위치 Point 1~4의 값을 계측하였다. 상관거리별 각 샘플 3,000개의 Point 1~4의 위치의 값과 그 중 일부인 100개의 샘플을 이용하여 업데이팅을 수행하여 얻은 값의 차를 표로 나타내었다. 관측 거리가 클때보다 작을 때 그리고, 상관거리가 작을때보다 클 때 실제값과 업데이트된 값의 차가 작았다.
Table 1.
Maximum difference by sample data according to observation (distance=5.0)
| Name | 1 | 5 | 10 | 20 | 50 |
| Point 1 | 0.3125 | 0.3514 | 0.2589 | 0.1146 | 0.0414 |
| Point 2 | 0.3075 | 0.3356 | 0.1549 | 0.0915 | 0.0451 |
| Point 3 | 0.3570 | 0.3332 | 0.2414 | 0.1162 | 0.0548 |
| Point 4 | 0.3481 | 0.3406 | 0.1880 | 0.1333 | 0.0529 |
Table 2.
Maximum difference by sample data according to observation (distance=0.5)
| Name | 1 | 5 | 10 | 20 | 50 |
| Point 1 | 0.2211 | 0.0599 | 0.0282 | 0.0119 | 0.0046 |
| Point 2 | 0.1745 | 0.0640 | 0.0271 | 0.0117 | 0.0047 |
| Point 3 | 0.2241 | 0.0488 | 0.0282 | 0.0118 | 0.0055 |
| Point 4 | 0.1631 | 0.0442 | 0.0277 | 0.0116 | 0.0055 |
Fig. 7은 100개의 샘플을 이용하여 업데이트된 확률특성과 실제 3,000개의 확률특성을 비교한 그림이다. 이때, 초기가정은 혼란을 주기 위해 실제와는 차이가 나는 값(평균 0.8, 표준편차 0.2)을 가정해 주었다. 초기가정 0.8에서부터 업데이트된 특성이 실제 특성과 유사한 그래프를 보이는 것을 볼 수 있었다.
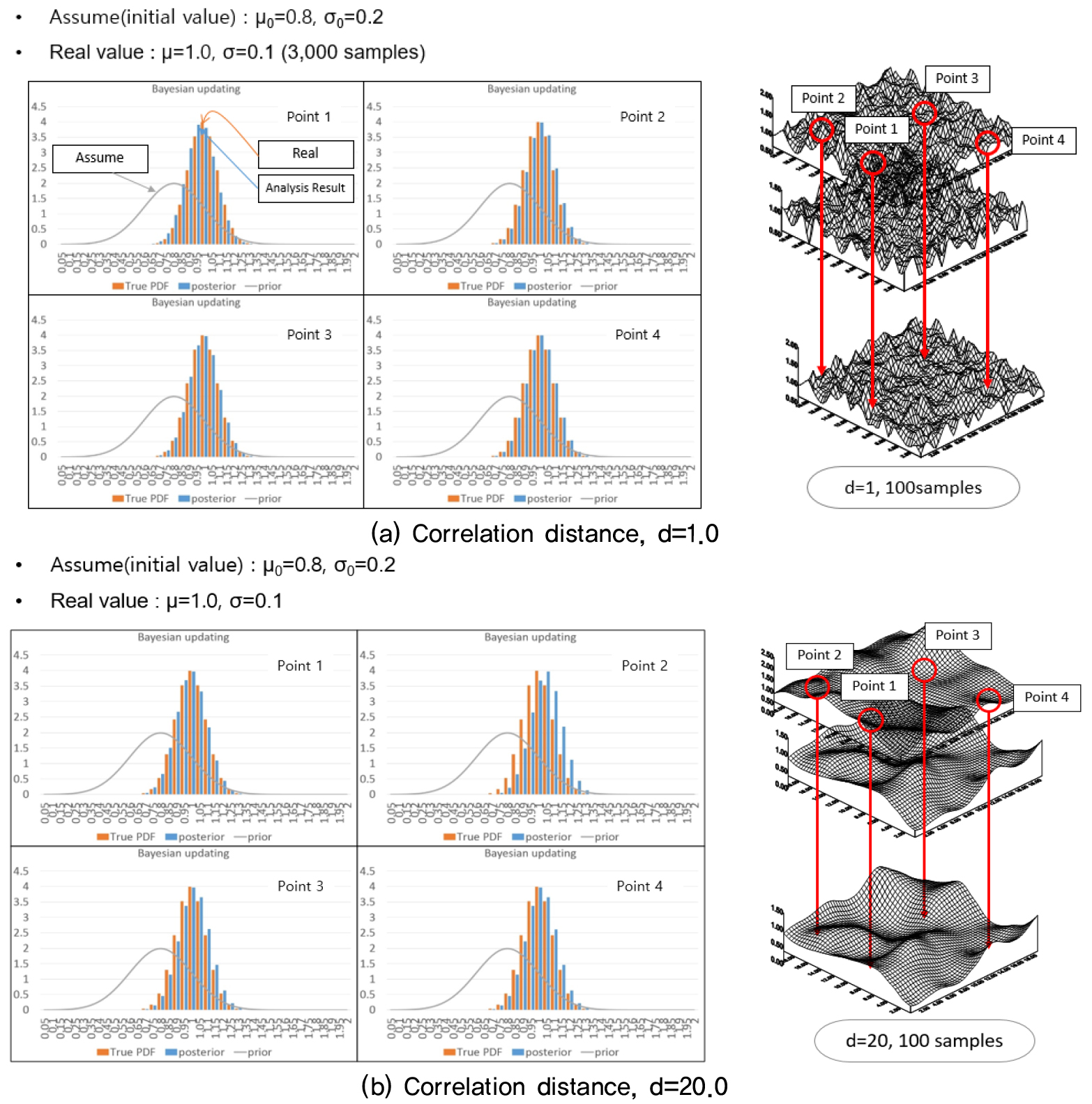
샘플들의 실험데이터 일부만을 이용하여 임의성을 가지는 지반구조재료의 상관거리를 추정할 수 있었으며, 베이지안 업데이팅을 이용하여 제한된 정보만을 가지고 전체를 추정할 수 있었다. 두 조건을 모두 만족하는 새로운 2D-1V의 추계장을 생성하여 Fig. 8과 같이 위상최적화에 적용하였다. 기존의 결정론적 위상최적화에 의한 총 2개의 물성 5.0MPa(Red), 3.0MPa(Blue)과 공극(Green)를 가지는 재료의 결과는 Fig. 9와 같이 반복횟수가 증가함에 따라 하나의 최적형상을 찾는다. 반면에 통계적 특성을 고려했지만, 공간적 임의성을 고려하지 않은 위상최적화 결과는 Fig. 10과 같다.
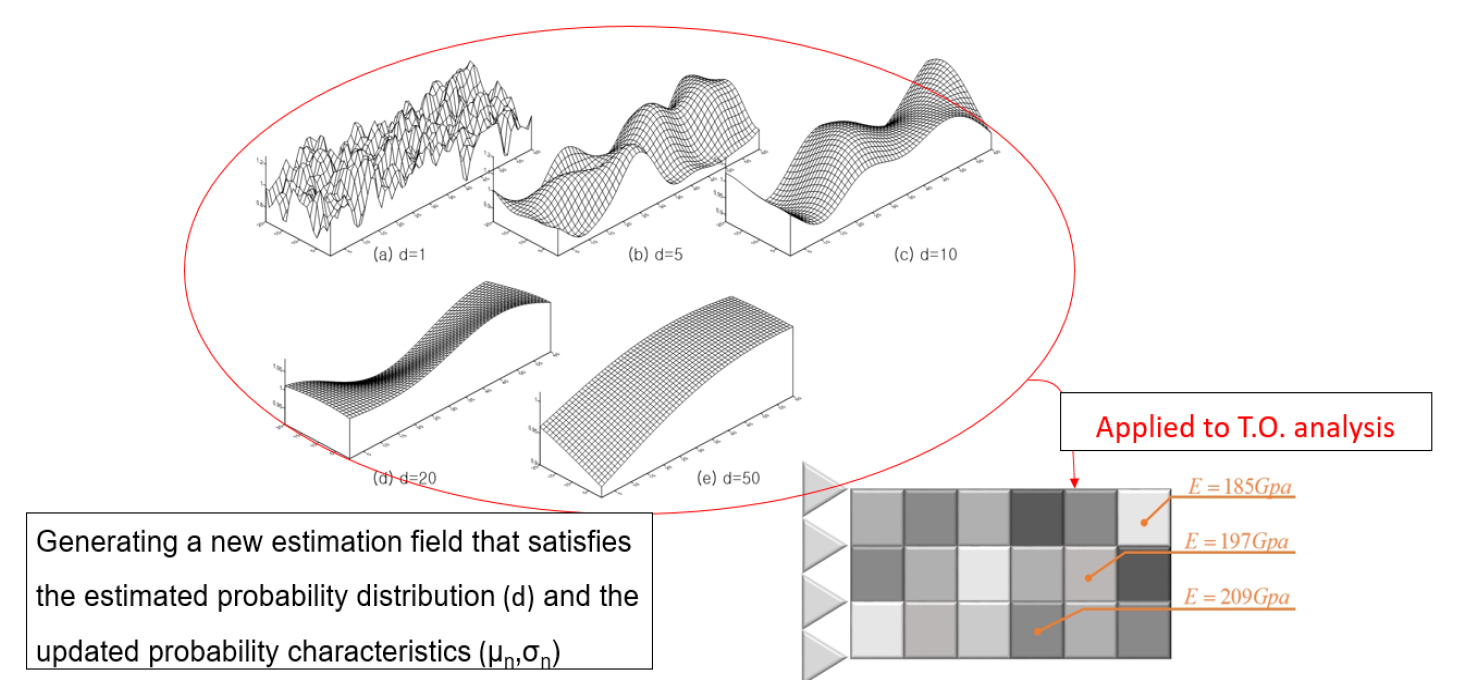
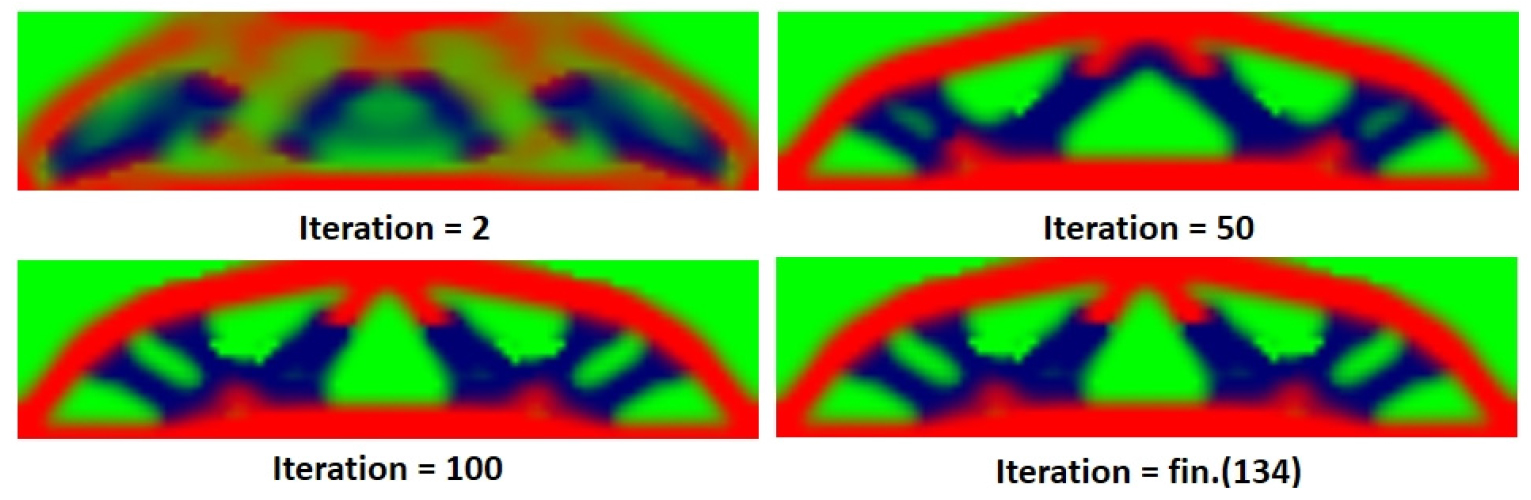
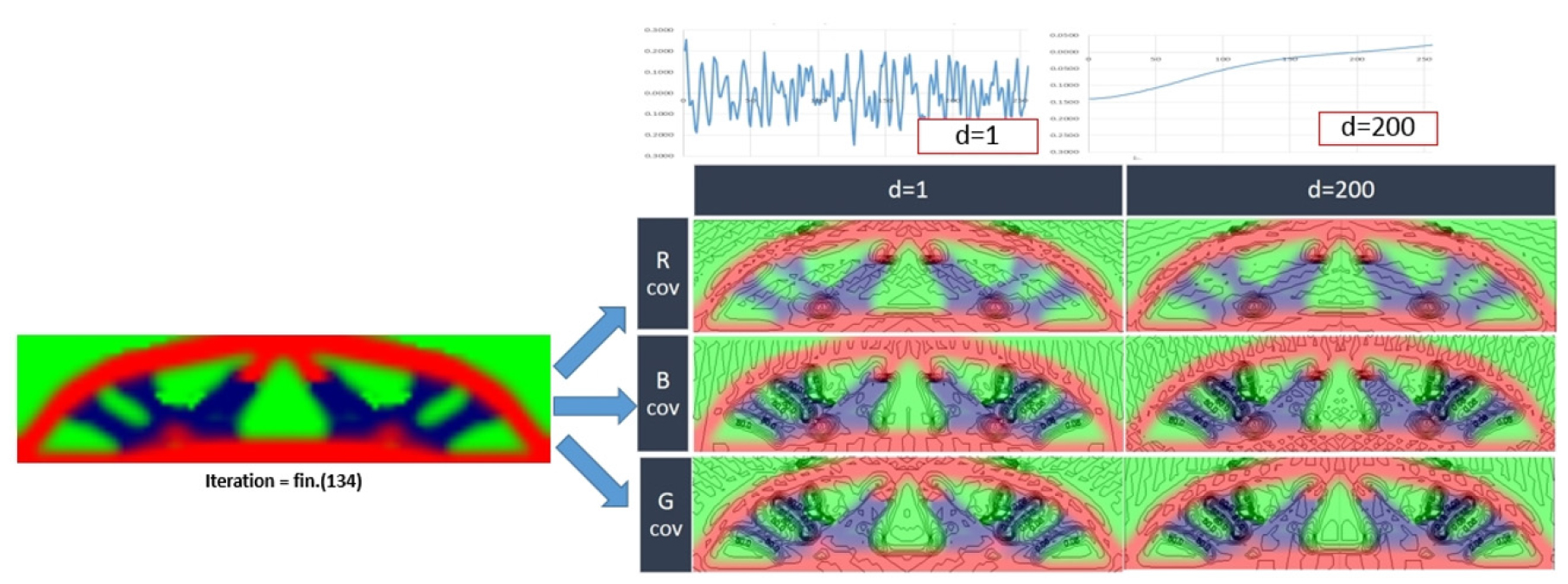
상수장 형태의 재료의 통계학적 위상최적화 해석결과는 기존의 결정론적 위상최적화와 유사한 형상이 나타났다. 또한, 각 재료 R, B, G의 변동계수역시 상관관계거리 크기에 상관없이 유사한 분산도를 나타내었다. 하지만 공간적 분포를 고려한 해석 시 Fig. 11과 같이 상관거리별로 다른 형상의 결과값이 나타났다. 특히, 상관거리가 d=20이상인 경우는 결정론적 결과와 거의 유사하고 d=10이하의 경우는 다른 결과를 보였다. 이는 상관관계거리가 무한대가 되면 확률변수상태가 되는 것과 의미가 같다.
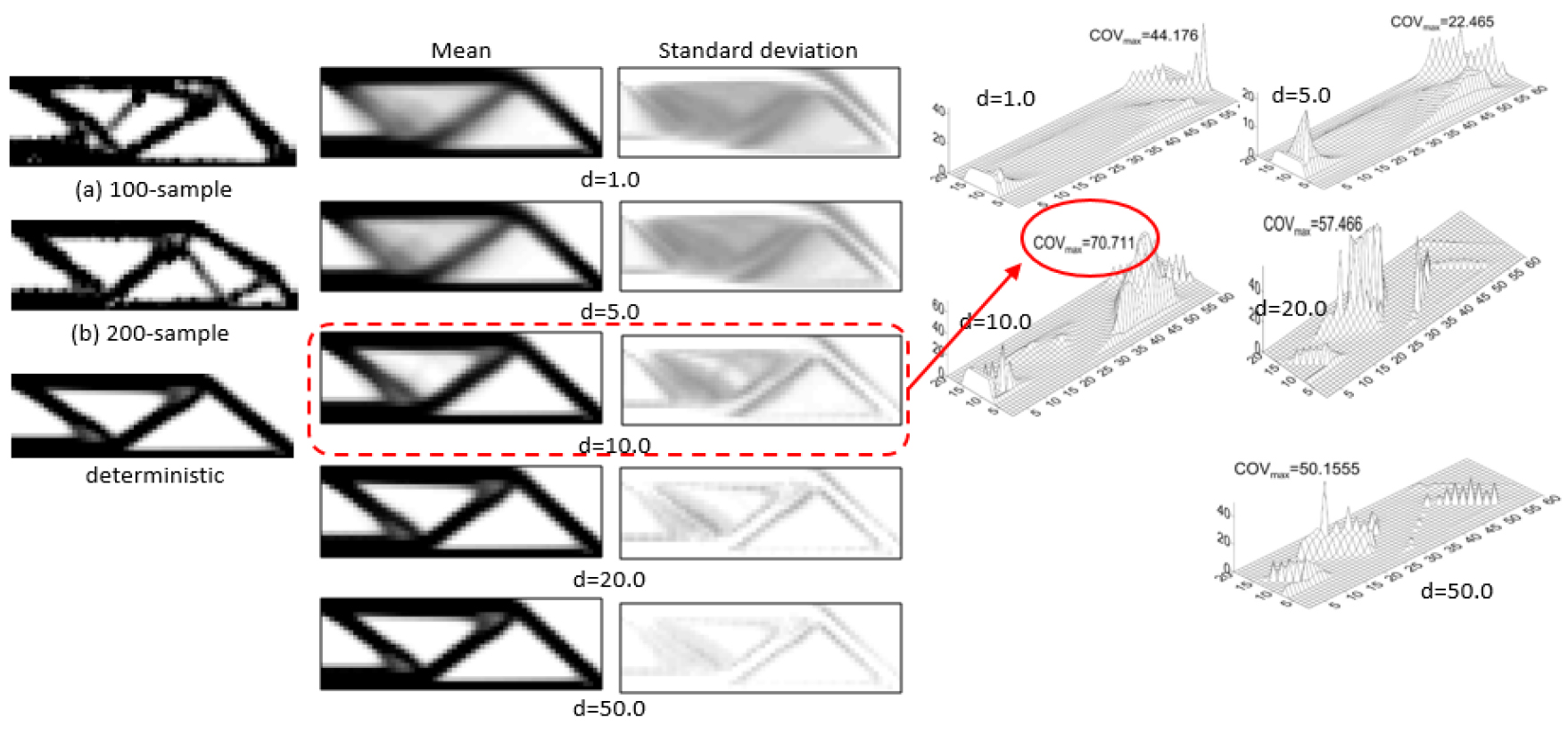
마찬가지로 공간적 임의성을 고려하여 N개의 샘플에 대한 통계처리 시 Fig. 12와 같이 종류별 형상을 보였다. 특히, 임의성은 기둥부에서 큰 것을 확인할 수 있다. 또한, 상관관계계수 d=1~50까지의 변동계수(COV)를 그래프로 나타내면 기존의 응답변화도이다. 하지만 본 해석에서는 상관관계계수를 이미 추정을 했고, 실제 재료의 상관거리(d)가 만약 10이라면, 이 지반구조물의 최대 COV는 70.711이 될 것이다. 하지만, Fig. 9와 같이 공간적 임의성을 고려하지 않았을 시 최대 COV는 50.155이하가 될 것이다. 이 경우 과소평가된 결과를 얻을 수 있음을 의미한다. 즉, 재료 물성치의 임의성을 재대로 알지 못하고 최적화 해석을 수행시 오류가 포함된 결과를 얻을 수 없음을 의미한다.
4. 결 론
기존의 설계·해석은 설계변수가 지반구조계 영역에 동일한 값을 가진다는 결정론적 가정에 근거하고 있다. 그러나 실제 지반구조계의 여러 인수들은 시간적, 공간적으로 임의성을 가지며, 본 연구의 경우와 마찬가지로 지반구조물 거동에 가장 영향력이 큰 재료탄성계수 또한 임의성을 가진다.
본 연구에서는 시험 샘플의 계측값과 계측지점 간 거리를 이용하여 재료의 임의성 정도를 나타내는 상관거리를 역으로 추정하고, 제한된 영역(샘플)에서 본 해석방법을 사용하여 실제 재료가 가진 확률특성과 확률분포를 추정할 수 있었으며, 다음과 같이 요약할 수 있다.
①재료샘플의 재료탄성계수로부터 상관거리를 역으로 추정할 수 있었다.
②추정된 재료탄성계수는 확률특성과 확률분포를 만족하였다.
③임의성을 가진 재료탄성계수를 가지는 지반구조물의 최적화는 임의성이 없는 재료탄성계수를 가지는 지반구조의 최적화 해석결과와 상이했다.
실제 재료는 임의성을 가지고 있고, 위상최적화 해석을 통해 중요성을 확인할 수 있었다. 기존의 확률론적 해석은 상관관계거리를 통해 임의성을 모사할 수는 있지만, 실제 재료가 가지고 있는 임의성을 알 수 없다. 따라서 현재의 결과는 가정에 불과하며, 그 의미도 높다고 볼 수 없다. 본 연구는 계측을 이용하여 상관거리를 역으로 추정하는 방식을 사용하여 위상최적화 해석에 적용하였다. 가정이 아닌 타겟 지반구조물의 관측값을 사용하여 실제 재료가 가진 확률특성을 이용하여 위상최적화 해석을 수행하였고, 기존의 방식과는 차별된 결과를 얻을 수 있었다. 추후에는 포아송비 혹은 기하인수(A,t) 등에 적용, 불확실성을 가진 인수들의 복합작용시에 대한 연구를 포함한 상관거리 추정과 실제값의 정확성을 높이기 위한 연구가 추가적으로 필요할 것으로 사료된다.
