

1. 서 론
2. 데이터
3. 예측 모델
3.1 다중선형회귀(Multi Linear Regression)
3.2 심층인공신경망(Deep Neural Network, DNN)
4. 결 론
1. 서 론
암반 비탈면의 안정성 평가에서 중요한 요소는 불연속면의 상태를 반영한 적합한 전단강도의 산정이다. 설계단계에서 고려한 전단강도 산정은 기존 문헌자료, 시추코아에 대한 절리면 전단시험 및 암석시험, 지표지질조사(암반의 불연속면 특성), 역해석 등의 결과를 비교 검토하여 산정한다(Hoek and Bray, 1974; Barton, 1973, 1974; You, 2002; Hoek, 1990; Hoek and Brown, 1997). 이와 같은 방법으로 산정된 전단강도를 설계에 적용하고 있지만 설계 시 현장 지질조건을 명확하게 판정할 수 없었기 때문에 그리고 설계 시 이루어지는 지반조사의 기술적인 한계(Prist, 1992) 때문에 예상 밖의 암사면 파괴가 발생하고 있는 실정이다. 한 예로 틈새가 미세한 불연속면은 시추조사를 이용한 지반조사 시 그 존재 여부를 확인하는 것이 여건상 매우 힘들다. 또한 설계 시 참조한 불연속면 전단강도가 현장이 위치한 퇴적암의 특성을 제대로 반영하지 못하는 경우도 있다.
불연속면이 잘 발달된 양산단층대의 건설된 고속도로 사면을 살펴보자. 이 지역 암사면에 대한 적정한 전단강도 산정에 대한 연구가 많이 진행되었다(Kim et al., 2018). 이 지역의 경우 크고 작은 암반비탈면 파괴가 많이 발생된 곳으로 우리나라에서 암질이 가장 불량하고 활성단층이 존재하는 경상분지 퇴적암 지역으로 비탈면 전구간에 걸쳐서 절리가 매우 발달되어 있다. 그리고 암반의 차별 풍화로 판단되는 원인에 의하여 비탈면 전구간에 걸쳐 풍화잔류토 혹은 풍화암층이 수평적인 변화를 보이는 곳이다. 양산단층대 퇴적암은 백악기에 구성된 쇄설성퇴적암으로 특이한 특성을 보이는 것으로도 알려져 있다(Kim et al., 2002; Choi et al, 2012; Kim et al., 2017, 2018). Kim et al.(2018)과 Lee et al.(2019)은 양산단층대 고속도로 암사면에서 발생된 파괴사면 128개소에 대한 자료를 분석하고(Korea Expressway Corporation, 2001, 2008; Kim et al., 2018) 불연속의 상태를 고려하여 전단강도를 재 산정하는 연구를 수행하였다. 그들의 연구에서 전단강도 산정은 불연속면 유형별 그리고 불연속면에 대한 면밀히 조사된 자료(불연속면의 각도, 상태, 지하수 유출 유무, 충진물의 유무 및 종류 등) 등을 반영하였다.
암반공학에 기계학습을 사용한 연구는 1990년대 초반까지는 보다 객관적이고 효율적인 암반분류와 지보설계를 위하여 사용되었다. 그 이후 딥러닝 알고리즘인 인공신경망(ANN)이 국내외적으로 암반분류에 적용되기 시작했다(Sklavounos and Sakellariou, 1995; Lee and Moon, 1994; Yang and Kim, 1999). 본 연구에서는 Kim et al.(2018)과 Lee et al.(2019) 연구의 연장으로 그들이 산정한 전단강도에 대하여 딥러닝 연구를 수행하였다. 현재는 기존 참고문헌, 역해석, 실험 등을 이용해 암사면의 전단강도를 추정하고 있으나, 전단강도 산정에 관련된 여러 복합적인 요인을 고려한 딥러닝 모델이 암사면 전단강도 산정에 적합하다고 판단되어 그 가능성을 모색하기 위함이다. 연구를 위하여 구글의 딥러닝 오픈소스 라이브러리인 텐서플로우를 활용하여 심층인공신경망(Deep Neural Network) 모델을 구축하였다. 또한 비교를 위해 예측 회귀모델로서 다중선형회귀(Multiple Linear Regression) 모델을 이용했다.
2. 데이터
본 연구에서는 예측을 위해 종속변수로 전단강도(Shear strength항)을 설정하였다. 기존 전단강도 산정에 들어가는 점착력(Cohesion항), 내부마찰각(Friction angle항)과 암반사면에서 퇴적암의 특성을 고려하기 위해 불연속면의 경사(Plane angle항), 불연속면의 종류(Target항) 그리고 충진물의 종류(State항)를 독립변수로 설정하였다. 총 사용한 데이터는 103개이며, 이것은 Lee et al.(2019)의 연구로부터 가져왔으며 그중 일부를 표로 나타내면 다음과 같다(Table 1).
Table 1.
Dataset sample
본 연구에 활용한 데이터의 절대적인 수가 적은 것이 가장 큰 제약사항이다. 이로 인해 랜덤하게 데이터 세트를 뽑아주는 train test split 모듈을 이용했을 때 결과의 변화폭이 생기고 안정적인 정확도를 뽑아내기가 어렵다. 따라서 본 연구에서 나온 결과를 현재 실제 설계에 반영하기는 어렵다.
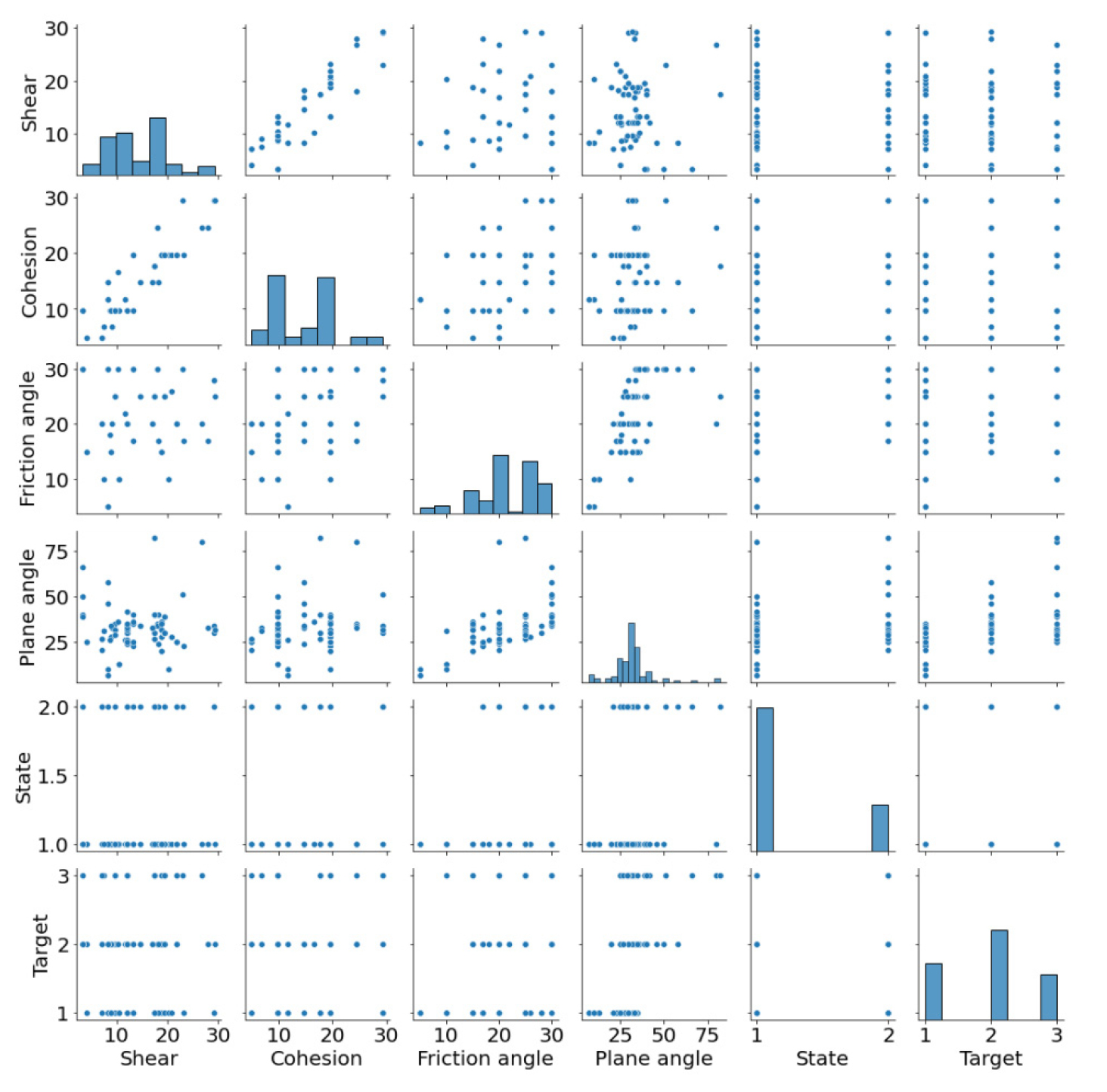
모든 변수를 고차원의 그래프에 시각화하는 것은 불가능하므로 Fig. 1과 같이 사용한 데이터의 분포를 시각화하여 나타냈다. 충진물의 종류(State)는 1이 점토잔존물(Filled by clay) 2가 풍화잔존물(Filled by shattered materials)로 채워진 것을 의미하며, 불연속면의 종류(Target)는 1이 층리(Bedding plane), 2가 절리(Joint plane) 그리고 3이 단층(Fault plane)을 의미한다.
단순 분포의 시각화를 통한 연관성 분석이 어렵다고 생각되어 상관분석(Correlation analysis)을 Fig. 2와 같이 히트맵으로 시각화했다. 상관분석은 확률론과 통계학에서 두 변수가 어떤 선형적 또는 비선형적 관계를 가졌는지 분석하는 방법이다. 히트맵은 데이터 값을 컬러로 변환시켜 열 분포 형태로 보여주어 시각적인 분석을 가능하게 해주는 시각화 기법으로 칸 안의 숫자들은 변수들의 상관계수를 나타낸다. Baek et al.(2013)은 공간 데이터를 기반으로 한 도시의 다양한 통계 정보를 시각화된 데이터를 지도와 사상(Mapping)하여 분석하는 연구를 수행하였는데 2차원 지도 데이터에서 특징데이터 값에 대해 색을 이용하여 표현하는 기법인 히트 맵 분석(Heat Map Analysis)기법을 사용하였다.
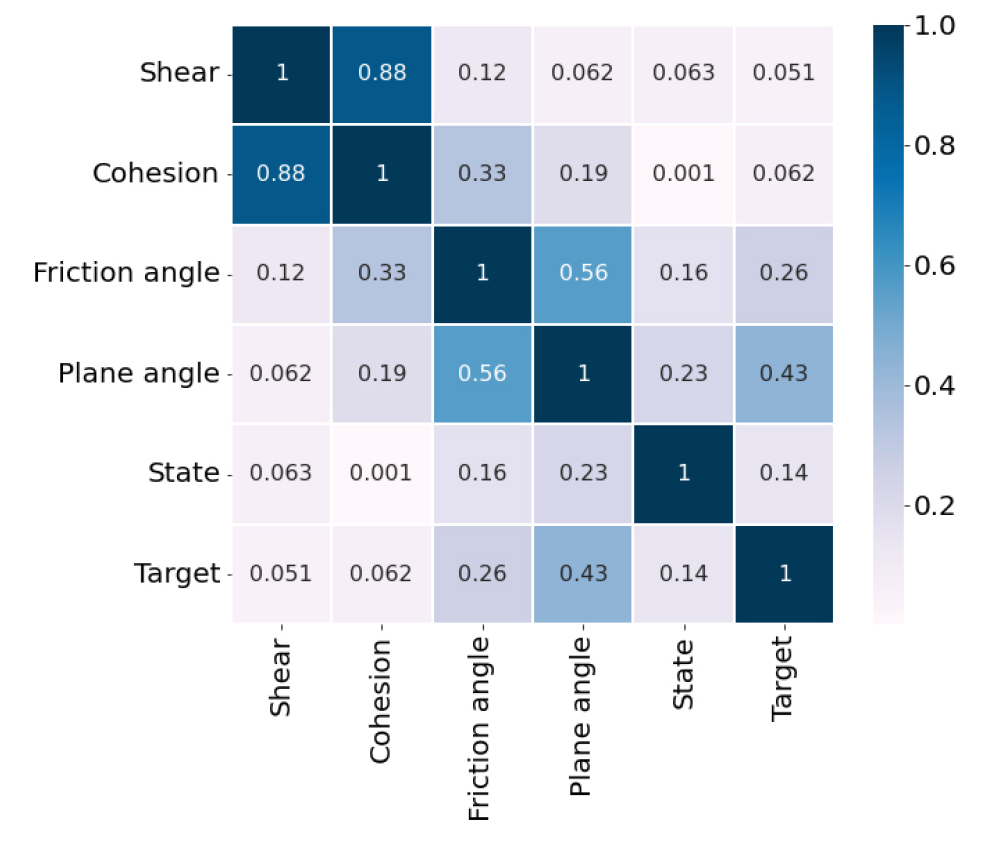
상관계수는 두 변수 사이의 상관관계의 정도를 나타내는 수치로 데이터의 종류에 따라 상관계수의 종류가 달라진다. 연속형-연속형의 상관계수는 –1과 1 사이에서 나타낼 수 있으며 Pearson correlation, Kendall correlation, Spearman correlation의 방법이 있다. 범주형-범주형의 상관계수는 0과 1 사이로 나타낼 수 있으며 Phi correlation, Cramer V계수가 있다. 연속형-범주형의 경우 Point biserial correlation, Biserial correlation, Polyserial correlation이 있다.
불연속면의 종류와 충진물의 종류가 범주형 값이기 때문에 –1과 1이 아닌 0과 1에서 값이 나오게 되었다. 0에 가까울수록 독립적인 변수임을 나타내고 1에 가까울수록 상관관계가 강하다는 것을 의미한다. 이를 통해서 전단과 가장 상관관계가 강한 변수는 점착력이고, 불연속면과 충진물의 종류는 큰 상관관계를 기대하기 어렵다고 예상할 수 있다.
Table 2의 OLS는 Ordinary Least Square의 약자로 최소제곱법으로 회귀모델을 구하는 방법이다. 두 모델을 통해 예측한 값을 실제 값과 비교할 때 사용할 방법으로, 각 항이 의미하는 바는 Table 3와 같다.
Table 2.
OLS regression result form
Table 3.
OLS regression result
위 값들 중에서 결정계수 R2값과 회귀계수 그리고 P값이 변수 사이의 설명력을 분석하는 데 주로 사용된다. 회귀분석은 각각의 데이터의 잔차의 제곱의 합이 최소화되는 공식을 도출하는 방법이다. 결정계수는 0과 1 사이의 값으로 표현되는데 설명력이 좋은 경우는 데이터가 회귀직선에 밀접하게 분포된다. 즉, 회귀직선이 동일하더라도 잔차의 크기가 다를 수 있으므로 예측되는 값의 정밀도는 설명력이 높을수록 좋아진다.
3. 예측 모델
Zarei et al.(2021)은 Linear Regression, Gaussian Process Regression, Adaptive Neuro-Fuzzy Inference System, Support Vector Machine, Deep Neural Network 5가지의 기계학습 모델을 통한 결과를 분석하였다. 총 72개의 데이터 중 50개를 모델학습에 사용하였고 22개를 검증데이터로 사용했다. 예측된 값과 실제 값의 비교 산포도를 제시하였고, 모델 적합도 평가를 위해 Coefficient of Correlation, Root Mean Square Error, Mean Absolute Error, Mean Absolute Error 그리고 Scatter Index의 5가지 파라메터를 이용하였다. 본 연구에서는 Kim et al.(2021)와 같이 R2값을 이용해 예측된 데이터와 측정된 데이터의 일치함을 분석했다.
모델에의 성능평가를 진행하기 위해 전체 데이터를 훈련(Train)세트와 평가(Test)세트로 나누었다. Train test split 모듈을 사용하여 훈련세트와 평가세트를 각각 80%와 20%로 랜덤하게 나누었다. 다중선형회귀 모델에서는 훈련세트를 다시 훈련세트 75%와 검증세트 25%로 나누어 교차검증을 통해 평가세트에만 과적합되는 점을 주의했다. 또한 심층인공신경망 모델에서는 Earlystopping 방법을 이용해 과적합을 방지했다. 모델의 최적화 후 평가세트로 최종평가를 했다. 모델을 통해 예측해낸 pred data와 평가세트 값의 비교분석을 통해 모델이 잘 예측해내었는지 설명력을 산출해냈다.
본 연구에서 사용될 모델은 다중선형회귀 모델과 심층인공신경망 모델이다. 총 5개의 독립변수가 고려되는 만큼 선형회귀 모델로서 가장 적합한 모델은 다중선형회귀 모델이다. 데이터 분포를 보았을 때 점착력과 같이 종속변수와 선형의 관계를 가지는 것이 한눈에 확인되는 변수도 있고, 비선형의 관계 그리고 수치형 데이터도 있기 때문에 이들 모두를 고려할 수 있는 모델은 딥러닝 모델이라고 판단되었다. 적은 양의 데이터가 딥러닝 모델에 적용하는 데 있어 제약사항이라고 하나, 적용성에 있어서 그 의미는 충분하다 판단되었다.
3.1 다중선형회귀(Multi Linear Regression)
지도학습(Supervised training)의 하나인 선형회귀(Linear regression)는 종속변수와 한 개 이상의 독립변수의 상관관계를 분석하는 기법이다. 본 연구에서는 복수의 독립변수를 고려하였기 때문에 다중선형회귀(Multi linear regression) 모델을 적용시켰다. 다중선형회귀 식은 식 (1)과 같이 나타낼 수 있으며, 회귀계수를 통하여 주어진 독립변수가 종속변수에 미치는 영향력을 유추해낼 수 있다.
회귀계수 추정기법은 최소제곱법(Least-square method), 최대우도법(Maximum-likelihood estimation)과 오차항 가정 직접법 등이 있으며 본 연구에서는 최소제곱법을 적용하였다. 최소제곱법은 실제 y값과 모델에서 얻은 추정값 사이의 차이인 오차항 ε를 이용한다(식 (2)).
오차항에 대한 아무런 가정도 하지 않고 이 오차항의 제곱의 합이 최소가 되도록 계수를 구한다. 본 연구에서 사용한 각 항의 도출된 계수값은 Table 4과 같다.
Table 4.
Coefficients of each term
| Independent variable | Cohesion | Filling type | Discontinuity type | Discontinuity slope | Friction angle |
| Coefficient | 0.913 | 1.607 | 0.410 | -0.018 | -0.281 |
학습세트를 이용해 단순히 결정계수 값을 냈을 때 0.8378의 값을 산출해냈다. 교차검증을 위해 k-겹 교차검증 방법을 사용했다. 본 연구에서는 k=4 즉, 학습세트를 4개의 폴드로 나누어 그 중 n번째 폴드를 검증세트로 활용했다. 총 4개의 교차 검증정확도가 나오고 평균 검증정확도가 학습모델의 성능이라고 본다. 각각 0.8464, 0.8006, 0.7016, 0.6939의 정확도가 나왔고 평균은 0.7606이 나왔다. 교차검증을 통한 정확도가 더 낮게 나온 것을 알 수 있다.
Fig. 3은 다중선형회귀 모델을 통해 산출된 계수를 이용해 test_data 내 종속변수를 통해 예측해낸 pred data와 test data의 독립변수 값을 비교해 산점도를 찍어낸 것이다. 또한 OLS(Ordinary Least Squares)를 통해 test data가 pred data에 대해 얼마나 잘 설명해내는지 분석했다. test data의 R2이 0.681로 68.1%의 설명력을 가지고 있고, P-value가 0.05보다 작으므로 통계적으로 유의하다(Table 5). 산점도의 추세는 y=0.6817x+4.3081로 기울기가 1에는 그다지 가깝지 않은 모습을 보였다. 평가세트를 이용한 정확도는 교차검증을 한 결과보다 더 낮은 값이 나온다는 것을 확인할 수 있다.
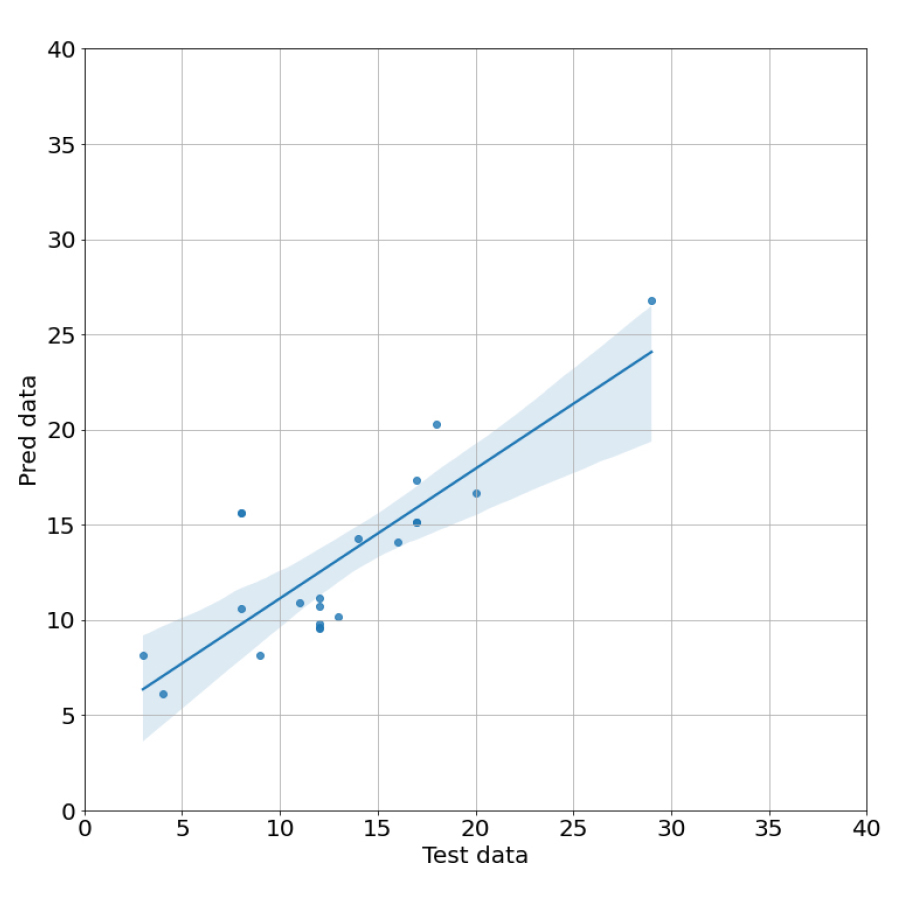
Table 5.
OLS result of MLR model
3.2 심층인공신경망(Deep Neural Network, DNN)
인공지능은 과적합의 문제해결과 더불어 하드웨어의 발전 그리고 빅 데이터 덕분에 인문사회 분야뿐만 아니라 공학 분야에서도 다시 관심을 받고 있다(Ahn, 2016). 인공신경망(ANN, Artificial Neural Network)은 딥러닝 기법으로 심층신경망(Deep Neural Network, DNN), 합성곱신경망(Convolutional Neural Network, CNN), 순환신경망(Recurrent Neural Network, RNN) 등의 대표적인 구조들이 있다(Kim, 2021).
본 연구에서는 심층신경망을 다루고 있다. 일반적인 인공신경망과 마찬가지로 복잡한 비선형 관계들을 모델링 할 수 있다. 입력층(Input layer)과 출력층(Output layer) 사이에 여러 개의 은닉층(Hidden layer)들로 이루어졌으며 입력값과 출력값의 상관관계를 신경망을 이용하여 구축하게 되며, 신경망을 이루는 행렬이 반복계산에 의해 개선되면서 결과값의 정확도가 올라간다. 입력층의 결과를 은닉층에서 결합함수(Combination function)를 이용해 합산하고 이를 가중치(weight)를 부여하여 계산된 값을 활성함수(Activation function)를 이용하여 출력값으로 보낸다. 대표적인 활성함수로는 Sigmoid, Tanh, ReLU(Rectified Linear Unit), ELU(Expotential Linear Unit) 등이 있다. 본 연구에서는 2개의 은닉층에 ReLU 활성함수를 활용하였고 마지막 출력층에서 Linear 활성함수를 통해 회귀모형을 구축하였다. Optimizer로는 Adam(Adaptive Moment Estimation)을 사용했다.
Fig. 4는 학습곡선(Learning curve)로 반복횟수가 증가함에 따라 훈련/검증데이터의 loss(손실함수 MSE)와 훈련/검증데이터의 평가지표 MAE의 변화를 시각화한 것이다. 전체 데이터셋의 최대 반복횟수 epoch는 200으로 설정하였고, batch_size를 10으로 하여 파라미터 업데이트에 사용하는 데이터를 10개로 설정하였다. 손실함수는 정답에 가까울수록 작은 값이 나오게 되는데, 본 연구에서 사용한 MSE(Mean Squared Error)는 회귀용도의 딥러닝 모델을 훈련시킬 때 많이 사용된다. 평균제곱오차의 계산은 다음 식을 이용한다.
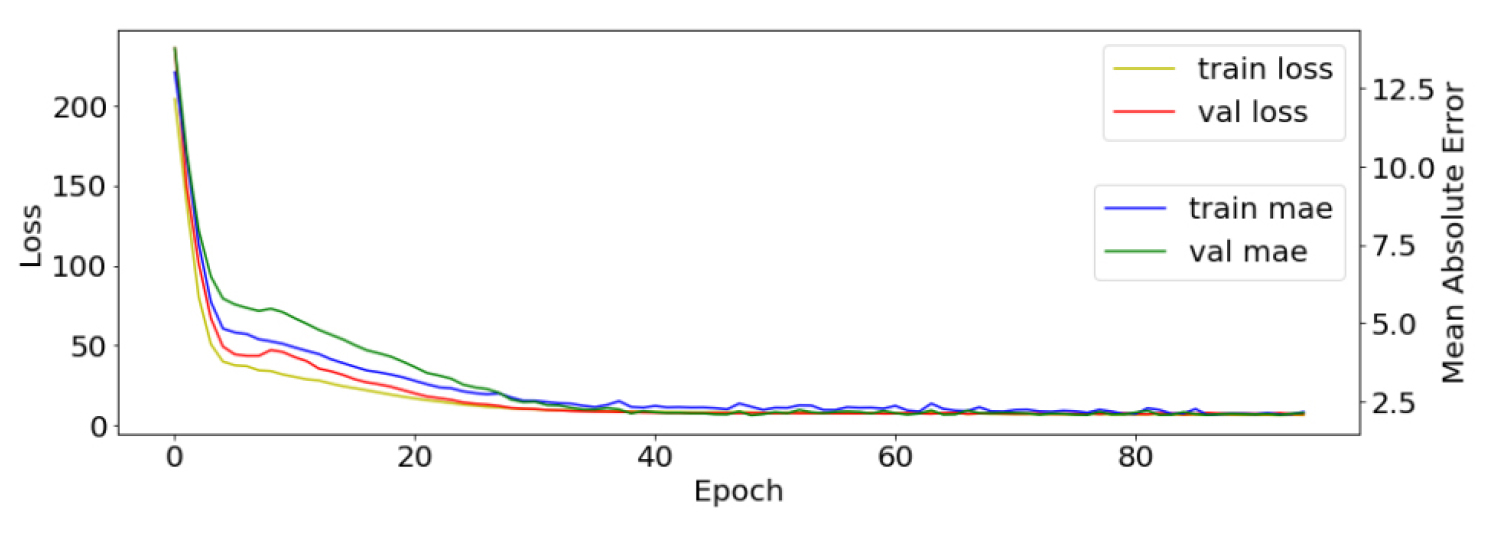
여기서 yi는 신경망의 출력값, ti는 정답 레이블(실제값)을 의미한다. 성능측정지표 metrics는 MAE(Mean Absolute Error)를 사용했다. 출력값과 실제값의 차이를 절대값으로 변환해 평균화한다. 예측 결과물의 양음에 관계없이 절대적인 크기 차가 더 중요하다고 생각되어 선택했다. 학습곡선을 통해 모델이 과소적합(underfit)되고 있는지 과적합(overfit)되고 있는지, 또는 그 외의 문제가 있는지 알 수 있다. 모델의 성능을 높이기 위해 데이터를 추가할지 또는 모델의 크기를 늘려야 할지 등의 방법을 생각할 수 있다. 과소적합 모델은 학습세트의 sample조차 제대로 모델링하지 못한 것을 의미하고 과적합 모델은 학습세트의 sample에 지나치게 적합되어 그 외의 데이터를 표현하지 못한다는 것을 의미한다. 반복횟수가 40까지 증가함에 따라 loss가 계속해서 떨어지는 추세를 보이는데 이럴 경우 모델이 아직 saturation이 되지 않았다고 한다. Train set loss와 validation set loss가 같이 떨어지다가 validation set loss가 상승하는 순간이 오는데 그 지점에서 훈련을 중단한다(early stopping 방식). 그 전에 훈련을 멈추면 과소적합, 훈련을 계속하면 과적합 상태로 본다.
해당 모델을 이용하여 예측해낸 결과는 Fig. 5에 나타내었으며, 다중선형회귀 모델과 달리 심층인공신경망 모델은 비선형적인 값들을 여러 개의 은닉층을 거쳐서 선형으로 만들어낸 것이므로 직접적으로 모델의 비교를 할 수 없다. 따라서 모델간의 정확도 비교를 위해서 DNN모델을 통해 예측해낸 결과값을 이용한 OLS분석 또한 실시하였다. test data의 R2이 0.821로 82.1%의 꽤나 높은 설명력을 가지고 있고, P-value가 0.05보다 작으므로 통계적으로 유의하다(Table 6). 산점도의 추세는 y=0.7634x+2.2863로 기울기가 다중선형회귀 모델에 비해 기울기가 1에 가까운 결과를 나타냈다.
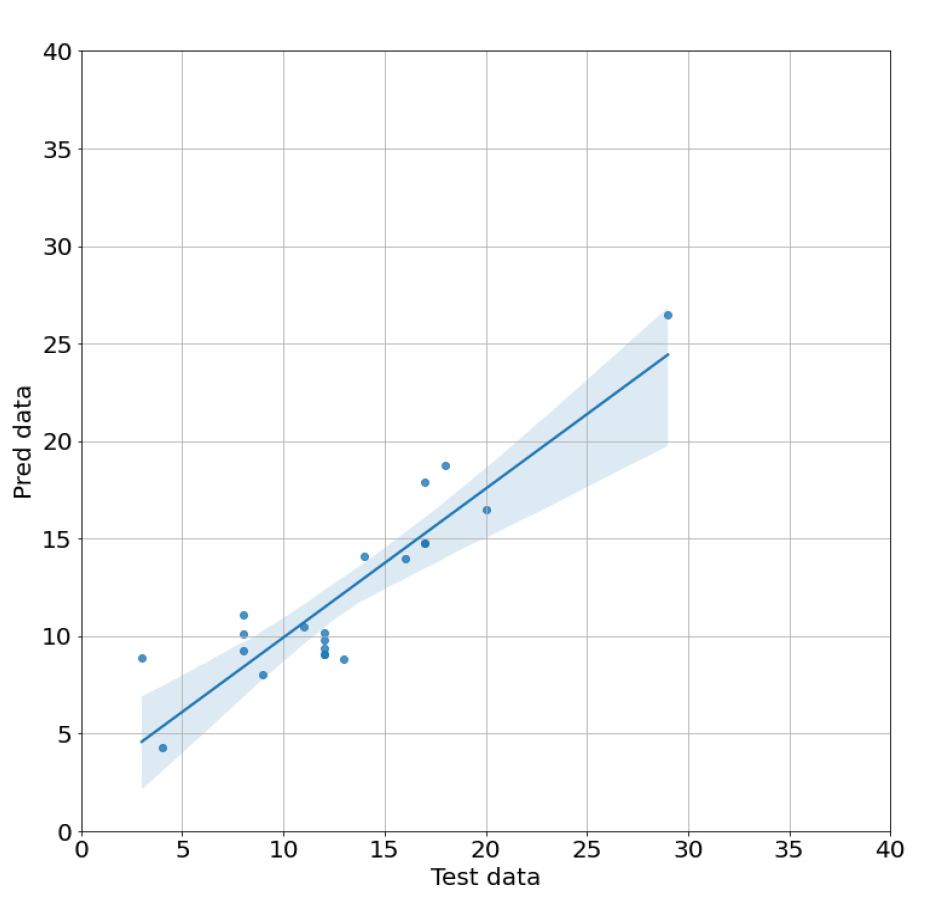
Table 6.
OLS result of DNN model
4. 결 론
본 연구는 전단강도 예측을 위한 딥러닝 모델의 적용성을 검토하였다. 불연속면의 종류, 점착력, 내부마찰각, 경사, 충진물의 종류 값을 이용해 해당 요인들의 복합적인 작용을 통한 전단강도를 예측하였다. 구글의 딥러닝 오픈소스 라이브러리인 텐서플로우를 활용하여 심층인공신경망(Deep Neural Network) 모델을 구축하였다. 또한 비교를 위해 예측 회귀모델로서 Multiple Linear Regression 모델을 이용했다. 이들 알고리즘의 전단강도 예측의 결과를 검토한 결과 다음을 알 수 있었다.
1) 딥러닝의 특성(블랙박스) 상 결과도출의 근거를 알 수 없기 때문에 각 모델의 변수에 대한 예측결과의 실제값과의 비교를 통해 정확도를 비교했다.
2) 다중선형회귀 모델의 예측값과 실제값을 비교했을 때, 기울기 0.6817, 절편 4.3081의 값을 가졌고, 설명력(R2)은 68.1%였다.
3) 심층인공신경망 모델의 예측값과 실제값을 비교했을 때, 기울기 0.7634, 절편 2.2863의 값을 가졌고, 설명력(R2)이 82.1%로 높은 값을 가졌다.
4) 전체적인 예측결과의 흐름은 비슷했지만 확실히 심층인공신경망이 더 높은 설명력을 가졌다. 이는 심층인공신경망 모델에서 선형의 관계가 아닌 변수의 설명을 은닉층에서 보완한 것으로 생각된다.
딥러닝을 하기에 제약이 있는 양의 데이터임에도 회귀분석보다 좋은 결과(정확도)가 나왔다는 점은 주목할 만하다. 비록 당장 실제 설계에 적용되는 것에는 어려움이 있지만, 후에 더 많은 데이터를 이용하여 모델의 정확도가 큰 폭의 변화 없이 안정적인 모델이 된다면 설계에 적용될 수 있는 좋은 전단강도 산정법이 될 것이다.
