

1. 서 론
2. Decision tree model 이론
2.1 Decision tree model의 정의
2.2 Decision tree model의 알고리즘
2.2.1 카이제곱 통계량(Chi-Square statistic)의 p-값
2.2.2 지니 지수(Gini index)
2.2.3 엔트로피 지수(Entropy Index)
3. 산사태 발생가능성 예측 모델 및 프로그램
3.1 산사태 예측 모델
3.2 산사태 예측 프로그램
4. 대상 연구지역 선정
4.1 현장개요
4.2 시료채취 및 토질특성
4.2 시료채취 및 토질특성
5. 연구지역 산사태 발생가능성 예측
6. 결 론
1. 서 론
우리나라의 연평균 강우량은 1,100mm-1,400mm에 해당하며, 이 가운데 70%가 6월부터 9월 사이의 우기철에 발생되고 있다. 최근에는 기후변화로 인하여 우기철의 강수량이 지속적으로 증가하고 있는 실정이며, 국지성 집중호우가 자주 발생되고 있다. 이러한 국지성 집중호우의 증가로 인하여 전국적으로 산사태가 빈번하게 발생되고 있으며, 이로 인한 피해도 증가하고 있는 실정이다. 산림청에서 제시한 자료에 의하면 최근 10년(2007-2016)간 산사태로 인한 피해면적은 총 2,382ha, 인명피해는 총 53명이며, 피해복구비가 총 4,533억원에 달하는 것으로 나타났다.
Olivier et al.(1994)는 24시간 동안의 강우량이 연평균 강우량의 20%를 초과할 경우 대형 급경사지재해가 일어날 수 있다고 보고한 바 있다. 그리고 Brand(1981)는 짧은 시간에 내리는 국지성 집중강우는 지질조건이나 수문지질 조건과 관계없이 대형 산사태를 일으킬 수 있다고 보고한 바 있다. 2011년 발생된 우면산 산사태의 경우 시간당 80mm가 넘는 집중호우가 발생되었을 때 산사태가 발생된 것으로 조사되었다(Korean Geotechnical Society, 2011).
그런데 동일한 강우가 발생된 지역의 경우 산사태가 발생되는 지역과 발생되지 않는 지역으로 구분된다. 이는 강우량이 산사태를 발생시키는 가장 큰 요인임에도 불구하고 지형, 지반 및 지질매체의 특성에 따라 산사태의 발생정도가 다름을 의미한다. 즉, 지형, 지반 및 지질매체의 공학적 특성에 따라 동일한 강우조건에서도 산사태가 발생되는 경우와 발생되지 않는 경우로 나눌 수 있다. 따라서 일정 강우조건하에서 대상지역의 어떤 지반조건 및 지질조건일 때 과연 산사태가 발생하며 정량적으로 산사태의 발생가능성을 예측하는 것은 매우 중요한 사항이다(Song et al., 2009).
Kim et al.(2003)은 광역적인 지역을 대상으로 산사태 발생가능성을 예측하기 위하여 로지스틱 회귀모델을 이용한 산사태 예측모델을 개발한 바 있다. Hong et al.(2004)은 지형, 지질 및 지반공학적 특성을 고려하여 인공신경망모델을 이용한 산사태 예측프로그램을 개발한 바 있다. 또한 Song et al.(2009)은 산사태 발생지역의 현장조사 및 토질시험자료를 토대로 Decision tree model을 이용하여 산사태 발생 예측기법을 개발한 바 있다. 이를 위하여 최근 10년 동안 결정질암 지역에서 발생된 산사태 자료수집 및 분석을 실시하였다. 이들 자료를 활용하여 통계적인 분석방법인 Decision tree model이론을 이용한 산사태 예측모델을 개발하고, 개발된 예측모델을 토대로 GIS기반의 산사태 예측프로그램인 SHAPP (Slope HAzards Prediction Program) ver 1.0을 개발하였다.
본 연구에서는 산사태 예측프로그램 SHAPP ver 1.0을 이용하여 전라남도 무안군 ◯◯지역의 호남선 철도 주변에 대한 산사태 발생예측을 실시하고자 한다. 이를 토대로 철도주변에 대한 산사태 발생가능성을 평가하고, 이에 대한 적용성을 검토하고자 한다.
2. Decision tree model 이론
2.1 Decision tree model의 정의
Decision tree model은 의사결정규칙(decision rule)을 나무구조로 도표화하여 관심대상이 되는 몇 개의 소집단으로 분류(classification)하거나 예측(prediction)을 수행하는 분석방법이다. 이 방법은 분류 또는 예측의 과정이 나무구조에 의한 추론규칙에 의해 표현되기 때문에 신경망, 판별분석 등에 비해 연구자가 그 과정을 쉽게 이해하고 설명할 수 있다는 장점을 가지고 있는 분석방법이다(Song et al., 2009).
데이터마이닝에서의 Decision tree model은 탐색(ex-ploration)과 모형화(modeling)라는 두 가지 특성을 모두 가지고 있다고 할 수 있다. 차원축소 및 변수선택, 교호작용 효과의 파악, 범주의 병합 또는 연속형 변수의 이산화는 탐색단계에 포함된다고 할 수 있고 세분화, 분류 및 예측은 모형화 단계에 포함된다고 할 수 있다.
Decision tree model은 마디(node)로 구성되며, 뿌리마디(root node)로부터 시작하여 분리기준(splitting criterion), 정지규칙(stopping rule), 가지치기(pruning) 등에 의해 각 가지(branch)가 끝마디(종단마디, terminal node)에 이를 때까지 자식마디(child node)를 계속 형성해 나감으로써 완성된다. 뿌리마디와 반대로 트리의 가장 끝에 위치하여 가지가 분리되지 않는 마디를 끝마디라고 하며, 뿌리마디부터 종단마디까지의 분리단계를 깊이(depth)라고 한다.
일반적으로 Decision tree model의 분석과정은 Decision tree 형성, 가지치기, 타당성 평가, 해석 및 예측의 과정을 거쳐 수행된다.
(1) Decision tree의 형성 : 분석의 목적과 자료구조에 따라서 적절한 분리기준과 정지규칙을 지정하여 Decision tree를 얻는다.
(2) 가지치기 : 분류오류(classification error)를 크게 할 위험(risk)이 높거나 부적절한 추론규칙(induction rule)을 가지고 있는 가지를 제거한다.
(3) 타당성 평가 : 이익도표(gains chart)나 위험도표(risk chart) 또는 검증용 자료(test data)에 의한 교차타당성(cross validation) 등을 이용하여 Decision tree를 평가한다.
(4) 해석 및 예측 : Decision tree를 해석하고 분류 및 예측모형을 설정한다.
2.2 Decision tree model의 알고리즘
Decision tree분석을 위해서 CHAID, CART, QUEST 등과 같은 다양한 알고리즘이 제안되어 있으며 최근에는 이들의 장점을 결합하여 보다 개선된 알고리즘들이 제안되고 상용화되고 있다(Song et al., 2009). Decision tree model의 대표적인 알고리즘은 CHAID(Chi-squared Auto-matic Interaction Detection) 알고리즘으로 명목형, 순서형, 연속형 등 모든 종류의 목표변수와 분류변수에 적용이 가능하며, Exhaustive CHAID 알고리즘으로 발전하였다. 그 밖에 CART(Classification and Regression Tree), QUEST (Quick, Unbiased, Efficient, Statistical), C5.0, C4.5 알고리즘 등이 있다.
순수도(purity) 또는 불순도(impurity)를 기준으로 자식마디를 형성해 나가는 순수도 지수(purity index)중 목표변수가 이산형인 경우에는 목표변수의 각 범주에 속하는 빈도(frequency)에 기초하여 분리가 일어난다. 이때 사용되는 주요 분리기준(partitioning criterion)으로는 카이제곱 통계량(chi-square statistic)의 p-값, 지니 지수(gini index), 엔트로피 지수(entropy index) 등이 있다.
2.2.1 카이제곱 통계량(Chi-Square statistic)의 p-값
Pearson의 카이제곱 통계량은 다음과 같이 정의된다.
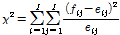 (1)
(1)
여기서, 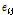 :
: 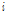 번째 그룹의
번째 그룹의 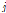 번째 결과에 대한 기대도수
번째 결과에 대한 기대도수
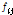 :
: 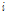 번째 그룹의
번째 그룹의 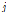 번째 결과에 대한 기대도수
번째 결과에 대한 기대도수
이것은 자유도(I-1)(J-1)을 가지는 카이제곱분포를 따르므로 유의수준을 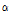 로 할 때
로 할 때 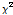 의 값이
의 값이 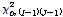 에 비해서는 매우 작다는 것은 예측변수의 각 범주에 따른 목표변수의 분포가 서로 동일하다는 것을 의미한다. 자유도에 대한 카이제곱 통계량 값의 크고 작음은 p-값(유의확률)으로 표현될 수 있는데
에 비해서는 매우 작다는 것은 예측변수의 각 범주에 따른 목표변수의 분포가 서로 동일하다는 것을 의미한다. 자유도에 대한 카이제곱 통계량 값의 크고 작음은 p-값(유의확률)으로 표현될 수 있는데 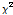 의 값이
의 값이 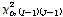 에 비해서 작으면 p-값은 커지게 된다. 결국 p-값이 가장 작은 예측변수와 그때의 최적분리에 의해서 자식마디를 형성한다.
에 비해서 작으면 p-값은 커지게 된다. 결국 p-값이 가장 작은 예측변수와 그때의 최적분리에 의해서 자식마디를 형성한다.
2.2.2 지니 지수(Gini index)
지니 지수는 각 마디에서의 불순도(impurity) 또는 다양도(diversity)를 재는 측정중의 하나로써 다음과 같이 표현될 수 있다.
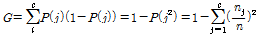 (2)
(2)
여기서, 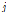 : 1, 2, …,
: 1, 2, …, 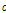 로서,
로서, 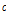 는 목표변수의 범주수
는 목표변수의 범주수
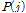 : 해당마디에서의
: 해당마디에서의 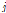 번째 그룹에 속하는 자료의 비율을 추정치로 사용
번째 그룹에 속하는 자료의 비율을 추정치로 사용
지니 지수는 n개의 원소 중에서 임의로 2개를 추출하였을 때 추출된 2개가 서로 다른 그룹에 속해 있을 확률을 의미하며 Simpson의 다양도 지수(diversity index)로도 알려져 있다. 2개의 자식마디로 분리된다고 할 때 지니계수의 감소량은 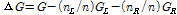 과 같이 계산되는데 여기서 n은 부모마디의 관측치 수를 말하고,
과 같이 계산되는데 여기서 n은 부모마디의 관측치 수를 말하고, 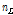 과
과 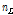 은 각각 자식마디의 관측치 수를,
은 각각 자식마디의 관측치 수를, 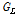 과
과 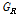 은 각각 자식마디에서의 지니지수를 의미한다. 즉, 자식마디로 분리되었을 때의 불순도가 가장 작도록 (순수도가 가장 크도록) 자식마디를 형성하는 것이며 지니 지수를 가장 많이 감소시켜주는 예측변수와 그때의 최적분리에 의해서 자식마디를 형성한다.
은 각각 자식마디에서의 지니지수를 의미한다. 즉, 자식마디로 분리되었을 때의 불순도가 가장 작도록 (순수도가 가장 크도록) 자식마디를 형성하는 것이며 지니 지수를 가장 많이 감소시켜주는 예측변수와 그때의 최적분리에 의해서 자식마디를 형성한다.
2.2.3 엔트로피 지수(Entropy Index)
엔트로피지수는 다음과 같이 표현된다.
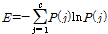 (3)
(3)
여기서, 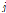 : 1, 2, …,
: 1, 2, …, 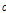 로서,
로서, 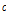 는 목표변수의 범주수
는 목표변수의 범주수
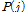 : 해당마디에서의
: 해당마디에서의 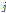 번째 그룹에 속하는 자료의 비율을 추정치로 사용
번째 그룹에 속하는 자료의 비율을 추정치로 사용
다항분포에서의 우도비 검정통계량을 사용하는 것과 같은 것으로 알려져 있고 최근에 널리 알려진 알고리즘인 C4.5는 엔트로피 지수를 분리기준으로 사용한다.
3. 산사태 발생가능성 예측 모델 및 프로그램
3.1 산사태 예측 모델
화강암, 편마암 등과 같은 결정질암 지역인 경기북부지역, 상주지역 및 속초지역에서 발생된 산사태 발생자료를 이용하여 Decision tree model을 이용한 산사태 예측모델을 개발하였다(Song et al., 2009). 산사태 예측모델개발을 위해 사용된 자료의 수는 각 지역별 총자료에서 결측치 등을 제외한 것으로 총 108개이다. 그리고 통계분석에 적용된 산사태 자료는 2일 강우량 200mm이상의 자료만을 활용한 것이다.
위의 자료를 이용한 Decision tree model 분석방법으로 카이제곱 통계량 방법, 지니지수 방법 및 엔트로피지수 방법을 사용하였다. 이들 분석결과를 토대로 하여 산사태 발생예측에 가장 적합한 예측모델을 개발하였다. 분석결과 카이제곱 통계량 방법과 지니지수 방법에 의한 Decision tree model은 동일하며, 이와 같이 구축된 Decision tree model의 정분류율(classification rate)은 95.37%이므로 개발된 예측모델은 비교적 정확함을 알 수 있다.
Fig. 1은 통계분석 방법 가운데 카이제곱 통계량 방법과 지니지수 방법을 이용하여 Decision tree model 예측모델을 구축한 결과이다(Song et al., 2009). 그림에서 보는 바와 같이 예측모델의 최상위 분리기준변수로는 사면경사가 선택되었으며, 하위 분리기준변수로는 각각 투수계수와 간극비가 선택되었다. 산사태 발생을 일으키는 사면경사의 기준은 27.5°인 것으로 나타났으며, 사면경사가 27.5°이상인 경우 산사태 발생을 일으키는 토층의 투수계수 는 0.00998cm/sec이상인 것으로 나타났다. 그리고 사면경사가 27.5°이하인 경우 산사태 발생을 일으키는 토층의 투수계수는 0.0395cm/sec이상이며, 간극비는 0.95이상인 것으로 나타났다.
본 연구에서는 앞서 설명한 Decision tree model을 이용한 예측모델을 적용하여 개발된 SHAPP ver 1.0 프로그램을 사용하였다. 본 프로그램에서는 각종 토질조사자료 및 수치지도로부터 얻어진 자료를 GIS기법을 활용하여 도면으로 작성할 수 있으며, Decision tree model을 이용한 예측모델을 적용하여 산사태 발생여부를 판단할 수 있다. 본 프로그램은 다음과 같은 네가지 모듈로 구성되어 있다; 1) 데이터 입력 및 출력구조 설계 모듈, 2) 산사태 DB모듈, 3) 통계분석 모듈, 4) 예측결과 가시화 모듈.
본 프로그램은 통계적인 분석방법 가운데 Decision tree model을 적용하였으며, 본 프로그램에는 한계평형해석방법은 고려되지 않았다.
3.2 산사태 예측 프로그램
본 프로그램은 전술한 Decision tree model의 산사태 예측모델을 토대로 GIS기법을 적용하여 국가 주요시설물 주변에 분포하고 있는 급경사지 재해를 예측하기 위하여 개발되었다. 본 프로그램은 Slope Hazards Prediction Program의 약자를 따서 SHAPP ver 1.0으로 명명하였다.
Fig. 2는 GIS기반 산사태 예측프로그램인 SHAPP ver 1.0의 흐름도를 나타낸 것이다. 그림에서 보는 바와 같이 개발된 프로그램은 먼저 수치지형도로부터 얻은 지형자료를 선택 및 분석하여 사면경사를 추출하고, 시험결과로부터 얻은 토질자료(투수계수, 간극비)를 입력하여 각각의 주제도를 작성한다. 그리고 산사태 예측지도 작성범위를 설정한 후 Decision tree model을 이용한 예측을 실시한다. 이러한 예측결과를 토대로 산사태 예측지도를 작성한다.
4. 대상 연구지역 선정
4.1 현장개요
철도구간 대상지역은 전라남도 무안군 ◯◯지역 일대로서 무안과 목포사이의 호남선 철로 상에 위치한 철도절개사면이다. Fig. 3은 대상지역의 위성이미지를 나타낸 것이다. 그리고 그림내 사각형은 대상지역이 위치하고 있는 구간을 표시한 것으로서 산사태 예측을 수행할 구간이다.
대상지역의 지형적 특징은 노년기 구릉성 지형을 나타내고 있어 낮은 산지와 완만한 경사지가 넓게 분포하고 있으며, 대상지역의 동쪽에는 넓은 평야가 발달하고 있다. 대상지역의 산계의 주능선 방향은 북동-남서방향으로 발달하고 있어 이에 따른 계곡 역시 본 방향으로 발달하고 있다. 그러나 주능선에서 발달하는 2차 능선의 경우 북서-남동방향으로 발달하고 있는데, 급경사지 재해 발생가능성을 평가할 대상지역 역시 북서-남동방향으로 능선이 발달하고 있다.
대상지역 주변의 지질은 선캠브리아기 화강편마암으로 구성되어 있다. 이 암석은 담회색을 띠는 저반형 조립 내지 중립질의 화강암질암으로 부분적으로 연장성이 불량한 엽리를 나타낸다. 본 지역의 지질도에서 연구대상지역 남쪽에 분포하는 유문암질 응회암은 유천층군중 유문암질 분출과 관련되는 화산쇄설암에 해당한다. 본 응회암층은 본 연구지역 남쪽에 넓게 분포하면서 고흥반도 일대 및 보성군 득량면 일대까지 넓게 분포한다.
4.2 시료채취 및 토질특성
연구지역 토질의 물리적 특성을 파악하고 산사태 예측을 위한 입력자료로 활용하기 위하여 연구지역인 무안군 ◯◯지역 일대 8개소에서 토층시료를 채취하였다. 시료는 연구지역에 분포하고 있는 지형조건 및 토층분포 등을 반영하고 가급적 단위면적당의 밀도비를 고려함으로써 토층의 특성이 균등하게 반영될 수 있도록 하였다. 원지반의 토층시료는 표토를 제거한 후 40∼60cm정도의 깊이에서 채취하였는데, 불교란 시료는 스테인레스로 제작된 원통형 샘플러를 이용하여 채취하였으며, 교란시료는 비닐팩을 사용하였다. 모든 시료는 현장조건이 최대한 유지되도록 밀봉한 상태의 시료를 실험실로 운반하였다. 그리고 채취한 토층시료를 이용하여 비중, 함수비, 입도분석, 액성한계 및 소성한계 등의 물성시험을 실시하고, 실내 밀도시험을 통해 간극비, 간극율 및 포화도를 산정하였으며, 연구지역 토층에 적합한 변수위법에 의해 투수계수를 구하였다.
Fig. 4는 연구지역인 무안군 ◯◯지역 일대에 대한 지형도와 토층시료의 채취위치를 나타낸 것이다. 대상지역은 무안과 목포사이의 호남선 상에 위치하고 있으며, 대규모 절개사면에 사면관리를 위한 각종 계측이 수행되고 있다. 대상지역의 총 8개소에서 토층시료를 채취하였으며, 채취한 시료에 대한 제반 시험방법은 KS의 관련기준에 준하여 실시하였다.
Table 1은 대상지역에서의 토층시료에 대한 토질시험 결과를 정리한 것이다.
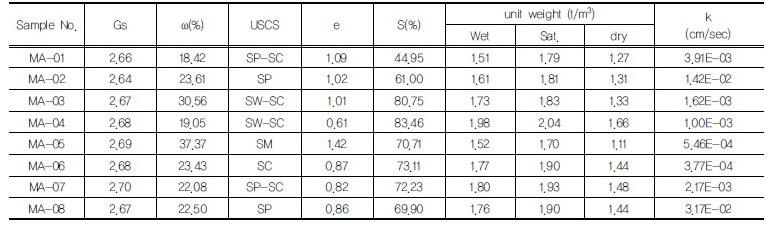
연구지역의 토층시료에 대한 시험결과 토질은 편마암 풍화토로 분류되며, 입도가 양호 혹은 불량한 모래로 이루어져 있다. 그리고 일부 시료에서는 실트 및 점토질이 포함되어 있는 것으로 나타났다. 대상지역 토층의 비중은 2.64∼2.70의 범위에 있으며, 평균 2.67인 것으로 나타났다.
연구지역 토층시료의 공극률은 37.92∼58.66% 범위에 평균 48.42%의 값을 갖고, 간극비는 0.61∼1.42의 범위에 평균 0.96인 것으로 나타났다. 포화도는 44.95∼83.46% 범위에 평균 69.51%의 값을 갖는 것으로 나타났다. 대상지역 토층시료의 건조단위중량은 1.11∼1.66t/m3의 범위에 평균 1.38t/m3의 값을 갖으며, 포화단위중량은 1.70∼2.04t/m3의 범위에 평균 1.86t/m3의 값을 갖는다.
한편, 입도분석결과에 의하면 대상지역 토층의 모래 함량비는 76.33∼95.76%의 범위에 있으며, 평균 89.70%로서 토층시료의 대부분이 모래로 구성되어 있음을 알 수 있다. 그리고 자갈의 함량비는 평균 0.60%로서 매우 낮은 편이며, 실트 및 점토의 함량은 평균 9.71%인 것으로 나타났다. 그리고 입도분포곡선을 조사한 결과 대상지역은 양입도(well grading)의 조건을 충족하는 경우와 빈입도(poor grading)의 조건을 충족하는 경우가 함께 존재하는 것으로 나타났다. 그리고 대부분의 토층에서 점토질 모래(SC)와 실트질 모래(SM)가 혼재하고 있는 것으로 나타났다.
대상지역 토층시료의 투수계수는 3.77×10-4∼3.71×10-2 cm/sec 범위에 평균 6.94×10-3cm/sec의 값을 갖는다. 대상지역의 투수계수 평균값은 Das(1990)에 의해 제안된 실트와 가는 모래의 투수계수에 해당 한다.
5. 연구지역 산사태 발생가능성 예측
연구지역인 철도에 인접한 자연사면을 대상으로 SHAPP ver 1.0을 이용하여 대상지역에 대한 산사태 발생예측 및 예측지도를 작성하였다. 이를 위하여 대상지역에 대한 현장조사결과와 수치지형도를 이용하여 지형의 경사분석을 실시하였으며, 토질시험결과를 토대로 예측프로그램의 입력변수인 투수계수와 간극비에 대한 분석을 실시하였다. 그리고 이들 사면경사, 투수계수 및 간극비를 이용하여 산사태 예측을 수행하였다.
Fig. 5는 산사태 예측프로그램 상에서 연구지역의 CAD형식의 수치지형도를 불러서 지형자료를 입력한 것이다. 그리고 Fig. 6은 입력된 지형자료를 토대로 TIN(Trian-gulated Irregular Network)을 생성하여 대상지역의 고도와 사면경사를 분석한 결과이다.
Fig. 7은 대상지역에 대한 토질시료 채취위치와 각 위치에 대한 토질시험결과를 입력한 것이다. 토질시험결과 가운데 투수계수와 간극비가 입력되며, 보간법의 일종인 IDW (Inverse Distance Weighting)기법을 이용하여 인자별 주제도를 작성하였다. Fig. 8은 연구지역의 간극비에 대한 주제도를 나타낸 것이며, Fig. 9는 연구지역의 투수계수에 대한 주제도를 나타낸 것이다. 그림에서 간극비 및 투수계수가 높은 구간이 밝은 부분으로 표현되며, 간극비 및 투수계수가 낮은 구간이 어두운 부분으로 표현하였다.
Fig. 10은 연구지역의 음영기복도를 나타낸 것이며, Fig. 11은 연구지역에 대한 산사태 발생 예측결과를 나타낸 것이다. 그리고 Fig. 12는 연구지역에 대한 산사태 예측지도를 작성한 결과이다. 그림에서 보는 바와 같이 밝은 색으로 표시된 부분이 산사태가 발생할 가능성이 높은 구간이다. 산사태 발생 예측결과 및 예측지도를 살펴보면 총 15,552개의 해석셀 가운데 435개의 셀에서 산사태가 발생될 것으로 예측되었다. 이때 해석셀의 크기는 10m×10m로 하였으며, 산사태 발생예상 면적은 43,500m2으로 나타났다.
6. 결 론
본 연구에서는 GIS기법과 Decision tree model을 적용하여 개발된 산사태 예측프로그램 SHAPP ver 1.0을 이용하여 전라남도 무안군 ◯◯지역 일대의 무안과 목포사이 호남선 철도 주변에 대한 산사태 발생 예측을 실시하였다. 본 프로그램에서는 각종 토질조사자료 및 수치지도로부터 얻어진 자료를 GIS기법을 활용하여 도면으로 작성할 수 있는 기법과 Decision tree model을 이용한 예측모델을 적용하여 산사태 발생여부를 판단할 수 있는 기법이 가능하다. 산사태 예측프로그램 SHAPP ver 1.0을 이용하여 철도주변의 연구지역에 대한 산사태 예측을 수행하였다. 이를 위하여 먼저 대상지역의 총 8개소에서 토층시료를 채취하고, 이에 대한 토질시험을 실시하였다. 대상지역에 대한 토질시험결과를 토대로 투수계수와 간극비에 대한 주제도를 작성하고 수치지형도를 이용하여 지형의 경사분석을 실시하였다. 이를 이용하여 산사태 예측을 실시한 결과 총 15,552개의 해석셀 가운데 435개의 셀에서 산사태가 발생될 것으로 예측되었다. 이때 해석셀의 크기는 10m×10m로 하였으며, 산사태 발생예상 면적은 43,500m2으로 나타났다. 산사태 위험지역을 산정하기 위해서는 산사태 예측결과를 토대로 산사태가 발생할 가능성이 있는 구간의 수계를 지정하고 하부 피해위험 예상지역을 선정하여야 한다.
