

1. 서 론
2. 활용 데이터와 평가기준
2.1 활용 데이터
2.2 성능 평가기준
3. 분류모델
3.1 K-최근접 이웃(K-nearest neighbor, KNN)
3.2 랜덤 포레스트(random forest, RF)
3.3 심층인공신경망(deep neural network, DNN)
3.4 모델 학습 결과
4. 요약 및 결론
1. 서 론
최근 지구온난화 및 이상기후의 증가로 인해 국내에서도 산사태 피해가 증가하고 있다. 산사태는 인간의 자산부터 생명까지 심각한 피해를 입히는 자연재해로 국내외적으로 산사태의 원인분석 및 취약지역 예측이 이루어지고 있다(Choi et al., 2017). Kim et al.(2022)은 강우량, 단위중량, 점착력 등의 물리 역학적 특성과 토층 두께, 경사도, 곡률 등의 지형 및 지질학적 특성을 이용해 산사태 발생 원인을 분석했다. Choi et al.(2013)은 경사도, 방위 곡률, 습윤지수 등의 지형적 특성들을 이용해 백두산 지역의 재해 위험도에 대한 분석을 했다.
유효토심은 산사태 재해도 분석 및 예측 연구에 사용되고 있다(Ho et al., 2012; Kim et al., 2016; Kim and Shin, 2016). 일반적으로 지하수위가 상승하면서 사면이 포화되고 안전율이 감소한다. 이 때 지반이 포화되는 시점은 토층의 두께와 밀접한 관련이 있다. Lee et al.(2012)은 유효토심에 따른 산사태 발생분포를 확인했다. 유효토심은 전기비저항탐사와 같은 지구물리학적 방법으로 추정이 가능하지만 전문가의 지식과 해석에 의존하는 방법이기 때문에 비용과 시간면에서 대규모 해석에의 적용은 힘들다(Karlsson et al., 2014). 또한 사면 붕괴 위험성 예측에 필수적인 값이지만 광범위한 지역을 획일적으로 가정하여 사용하기 때문에 신뢰성이 확보된 유효토심이 필요하다(Min and Yoon, 2018). 토심과 관련된 지형정보를 알기 위한 다양한 연구가 진행되었으며, 이런 토심과 밀접한 관련이 있는 다양한 지형적 특성들을 이용해 토심을 예측해내는 연구가 진행되고 있다.
토심의 예측에 일반적으로 지구통계학적 크리깅 기법이 많이 사용되었지만(Penížek and Borůvka, 2006; Bourennane et al., 2000; Kuriakose et al., 2009), 최근 머신러닝에 대한 관심이 증가하면서 기존의 방법과 비교하는 연구가 진행되었다. Chun et al.(2019)은 x, y, z 좌표와 지하수위를 이용해 지표면에서 풍화암까지의 토층심도를 정규 크리깅 방법과 심층인공신경망을 이용해 예측하고 그 결과를 비교했다. 인공신경망의 결과가 정규 크리깅 기법에 비해 객관적으로 좋은 성능은 보이고 있지 않다고 했으며 추가적인 정보들을 활용하여 예측성능의 향상을 기대했다. 대다수의 연구는 회귀모델을 사용하여 평균 제곱근 오차(root mean square error, RMSE)를 통해 성능을 평가하였다. Chan et al.(2019)와 같이 분류를 통한 유효토심의 예측을 시도한 연구도 있다. 경사도, 방위, 고도, 곡률 등을 고려하였으며, 유효토심을 매우 깊음(90cm 초과), 깊음(50-90cm), 얕음(20-50cm), 매우 얕음(20cm 미만)의 4개로 분류했다. Multinomial logistic regression, ordinary kriging, regression kriging, topographic wetness index with k-means clustering 방법을 비교하여 multinomial logistic regression 모델의 성능이 kriging방법에 비해 우수한 것으로 판단되었다.
본 연구에서는 고도, 경사도, 방위, 상부사면기여면적, 윤곽구배곡률, 중력이상, 지진지체구조, 지체구조의 8개 지형정보를 이용해 유효토심의 분류를 통한 예측성능을 알아보았다. 유효토심은 3개 분류기준(얕음, 보통, 깊음)과 5개 분류기준(매우 얕음, 얕음, 보통, 깊음, 매우 깊음)으로 분류했다. 3개 분류기준은 0-50cm 얕음, 50-100cm 보통, 100cm 초과를 깊음으로 분류했으며 5개 분류기준은 0-20cm 매우 얕음, 20-50cm 얕음, 50-100cm 보통, 100-150cm 깊음, 150cm 초과를 매우 깊음으로 분류하였다. 분류모델은 K-최근접 이웃, 랜덤 포레스트, 심층인공신경망의 3가지를 이용했다. 거리기반의 가장 단순한 K-최근접 이웃과 특성의 중요성을 알 수 있는 랜덤 포레스트와 딥러닝인 심층인공신경망의 분류 성능을 정확도, 정밀도, 재현율, F1-점수를 이용해 비교하고 분류모델의 적용성을 확인해보았다.
2. 활용 데이터와 평가기준
2.1 활용 데이터
본 연구에서 사용한 지형정보는 고도, 경사도, 방위, 상부사면기여면적, 윤곽구배곡률, 중력이상, 지진지체구조, 지체구조의 8개의 항을 이용했다. UTM(Universal Transverse Mercator) 좌표계를 토대로 연구지역을 100m×100m의 격자로 나누어 각 좌표마다 값을 부여하는 방법으로 정리하였다. 본 연구에서는 분류를 통한 유효토심의 예측 정확도와 그 적용성의 확인이 목적으로 다소 격자의 범위를 크게 지정하였으며, 전국에 걸쳐 넓은 분포의 데이터를 수집하였다. 데이터는 Table 1에 표기된 방법으로 수집했다.
Table 1.
Data collecting
| Feature | |
|
Effective (Effective soil depth) |
One of the detailed information of the soil map provided by the National Institute of Agricultural Science Collected in the state of being classified according to the thickness of the soil |
|
Elevation (Elevation) |
Kriging spatial interpolation is applied based on the elevation extracted from the digital topographic map of the NGII (National Geographic Information Institute). |
|
Slope (Slope) |
Calculated using the finite difference method using the digital elevation model |
|
Aspect (Aspect) |
Using a digital elevation model, applying a clockwise direction based on north |
|
Lna (Upslope contributing area) |
DEMON (Digital Elevation Model Network) algorithm proposed by Costa-Cabral and Burges (1994) is applied to measure the amount of potential flow that can be received from the upper area. |
|
Kp (Profile curvature) |
The main criterion for evaluating the potential gradient ratio in relation to the degree of acceleration of the flow |
|
Gravity (Gravity anomaly) |
Analyzing the gravitational anomaly caused by the difference in the density of rocks existing underground to reveal the underground structure Gravity data measured by the KIGAM (Korea Institute of Geoscience and Mineral Resources to create a global geophysical ideal map. Absolute and relative gravity measurement data measured by the NGII. |
|
Quake (Earthquake tectonic structure) |
An area where seismic characteristics such as frequency of occurrence and maximum earthquake are estimated to be the same Divided into 6 zones by KIGAM in 2019 |
|
Tecto (Tectonic structure) |
Using a map created by classifying rocks according to the type and time of formation Divided into 3 masses and 11 tectonic zones |
지형정보의 차원을 축소시켜서 모델에 학습시키기 위해 수집된 데이터의 등급화를 수행하였다(Table 2, Table 3). 이를 통해 모든 데이터의 형식을 categorical data로 통일했으며 각 항에 _g를 붙임으로써 등급화 되었음을 표시하였다.
Table 2.
Grading topographic information
Table 3.
Grading effective soil depth
|
Effective soil depth | 3 classes | |
| ⓪ | Shallow, 0-50cm | |
| ① | Normal, 50-100cm | |
| ② | Deep, >100cm | |
| 5 classes | ||
| ⓪ | Very shallow, 0-20cm | |
| ① | Shallow, 20-50cm | |
| ② | Normal, 50-100cm | |
| ③ | Deep, 100-150cm | |
| ④ | Very Deep, >150cm | |
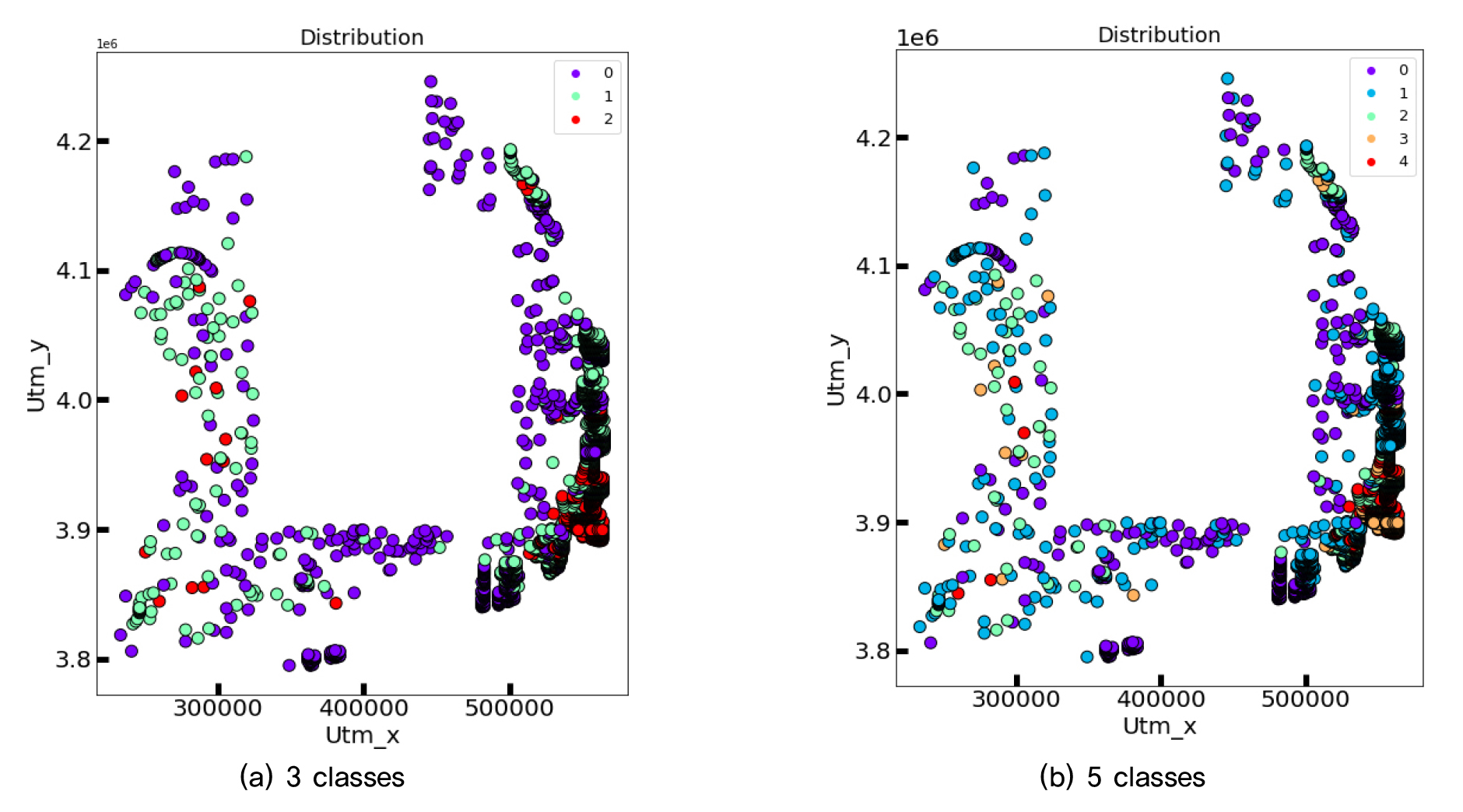
모든 null값은 drop시켰으며 데이터 등급화 처리 후 2634개의 데이터가 남았다. 학습시키기에 앞서 train_test_split을 통해 학습데이터와 시험데이터를 9:1로 분리했다. 후에 각 모델에 맞는 방법을 이용해 학습데이터의 20%를 분리하여 검증데이터로 사용했다. 전체 데이터의 유효토심 분포는 Fig. 1과 같다.
2.2 성능 평가기준
본 연구에서 모든 예측모델을 대상으로 사용될 평가지표는 정확도(accuracy), 정밀도(precision), 재현율(recall), 그리고 F1-점수(F1-score)이다. 4가지의 평가지표는 오차행렬(confusion matrix)을 통해 도출된 예측값과 실제값이 비교된 표를 통해 계산된다. Table 4와 같이 출력된다.
- TP(True, Positive): Positive 예측, Positive 실제(정답)
- FP(False, Positive): Positive 예측, Negative 실제(오답)
- TN(True, Negative): Negative 예측, Negative 실제(정답)
- FN(False, Negative): Negative 예측, Positive 실제(오답)
정확도는 분류모델에서 주로 사용되는 평가지표로 타겟 대비 정확히 예측한 비율을 의미한다. 분류하고자 하는 대상이 균등할 때 사용되는 지표이다.
정밀도는 positive로 분류한 값 중 실제 값이 positive인 비율을 의미한다.
재현율은 실제값이 positive인 것 중 positive로 분류한 비율을 의미한다.
F1-점수는 분류하고자 하는 대상이 균등하지 않을 때 사용되는 지표로, 정밀도와 재현율의 조화평균으로 계산된다. 조화평균을 이용하게 되면 산술평균을 사용할 때보다 편향(bias)가 줄어드는 효과가 있다. 본래 f-점수는 다음 식과 같지만 그 중 β가 1일 때를 F1-점수라 한다.
4개의 평가기준 모두 classification report를 통해 도출될 수 있다. Classification report는 F1-점수의 단순평균값인 macro average(macro avg)와 클래스에 속하는 표본의 개수로 가중평균한 weighted average(weighted avg)가 함께 출력된다.
3. 분류모델
3.1 K-최근접 이웃(K-nearest neighbor, KNN)
K-최근접 이웃 모델은 지도학습의 한 종류로 거리기반의 분류모델이다. 단순하기 때문에 구현이 쉽고 훈련이 매우 빠르다는 장점이 있지만, 모델의 생성을 통해 결과해석을 하는 것이 아니기 때문에 특성과 클래스 간의 관계를 이해하는데 제한적이다. 또한 데이터가 많을 때 분류 속도가 느려지는 특징이 있다.
비슷한 특성을 가진 데이터는 비슷한 범주에 속한다는 가정을 기본으로 주변의 가장 가까운 K개의 데이터의 데이터 레이블을 참고하여 데이터가 속할 그룹을 판단한다. 이 때 데이터 사이의 거리를 측정하는 방법으로 Euclidean distance가 사용된다.
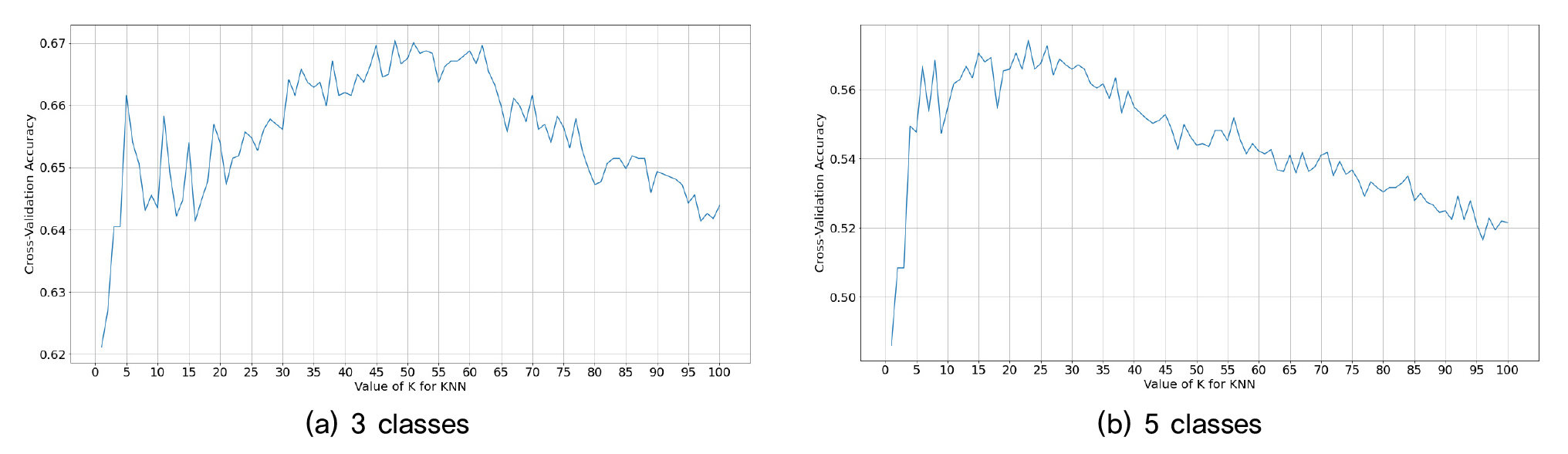
K의 값에 따라 정확도가 달라지기 때문에 데이터 판별을 위한 적절한 K의 선택이 중요하다. K의 값이 커질수록 노이즈의 영향이 줄면서 정확도가 상승하지만, 항목 간의 경계가 불분명해진다(Everitt et al., 2011). 본 연구에서는 K가 1에서 100까지의 값을 가졌을 때의 정확도 변화 추이를 확인하고 최고의 정확도를 가진 K를 선택했다. 모델성능의 향상을 위해 cvfold 모듈을 사용했다. 이는 K겹 교차 검증을 진행해주는 모듈로, 데이터를 K개의 fold로 나누어 차례대로 검증데이터로 사용한다. K를 5로 설정하여 학습데이터의 20%를 검증데이터로 사용했다. 각 fold의 정확도 평균으로 성능을 평가하며, 그 결과는 Fig. 2과 같다.
3개 분류기준에서 K=48일 때 최고 평균정확도 67.05%가 나왔으며 5개 분류기준에서 K=23일 때 최고 평균정확도 57.43%가 나왔다.
3.2 랜덤 포레스트(random forest, RF)
3.2.1 의사결정나무
랜덤 포레스트는 여러 개의 의사결정나무(decision tree)를 형성하고 각 트리에서 나온 결과에서 투표를 실시하여 가장 많이 득표한 결과를 최종 분류결과로 선택하는 앙상블(ensemble) 방식의 알고리즘이다. 의사결정나무는 if ~ else와 같이 특정 조건을 기준으로 나누어 분류 또는 회귀를 진행하는 tree구조의 모델이다. 이해도가 매우 높고 직관적인 장점이 있지만, 변동성이 높고 샘플에 민감하다는 단점이 있다.
구성요소로는 크게 노드(node), 엣지(edge) 그리고 깊이(depth)가 있으며, 트리를 나누는 기준으로는 불순도를 수치화한 엔트로피(entropy)와 지니계수(gini index)가 있다. 분리가 확실할수록 불순도 수치가 낮아진다. 의사결정나무는 이 불순도 수치를 낮추는 방향으로 분류작업을 수행하게 된다. 본 연구에서는 엔트로피를 이용했으며 다음 식과 같다.
엔트로피를 낮추는 방향으로 의사결정나무가 형성될 때 각 변수들의 information gain이 계산된다. 이는 의사결정나무에서 변수 중요도를 선택하는 지표로 사용되며, information gain이 클수록 노드가 분기했을 때 불순도가 많이 감소한다.
3.2.2 랜덤 포레스트
지도학습에서 과적합된 모델은 학습한 데이터에 대한 예측은 잘 해내지만 새로운 데이터에 대한 예측은 성능이 떨어지는 모습을 보인다. 이런 과적합 문제를 해결하기 위해 의사결정나무에 앙상블 방식 중 배깅을 적용한 것이 랜덤 포레스트이다(Breiman, 2001). Boot strap aggregation에서 나온 말로, 데이터에서 일부를 샘플링하는 boot strap을 통해 전체 데이터셋에서 여러 개의 샘플을 만들어 모델을 여러 번 학습시킬 수 있게 된다. 유의미한 특성들이 항상 포함되었을 때 나무들의 상관관계가 높아져 또 다른 과적합 문제를 야기할 수 있으므로 각각의 나무는 일반적인 무작위로 선택된 특성을 이용한다. 이를 통해 약한 설명력을 가지지만 상관관계는 낮은 나무들을 생성시켜 추합하는 것이다. 교차검증을 위해 GridSearchCV를 이용했다. GridSearchCV는 모델의 성능향상을 위해 하이퍼 파라미터의 값을 리스트로 입력하고 값에 대한 경우의 수마다 성능을 평가, 비교하면서 최적의 하이퍼 파라미터를 찾는 모듈이다. K-최근접 이웃과 마찬가지로 fold를 5개로 학습데이터의 20%를 검증데이터로 사용했다. Table 5는 GridSearchCV에 사용한 파라미터에 대한 설명과 조합이다.
Table 5.
Random forest GridSearchCV parameter
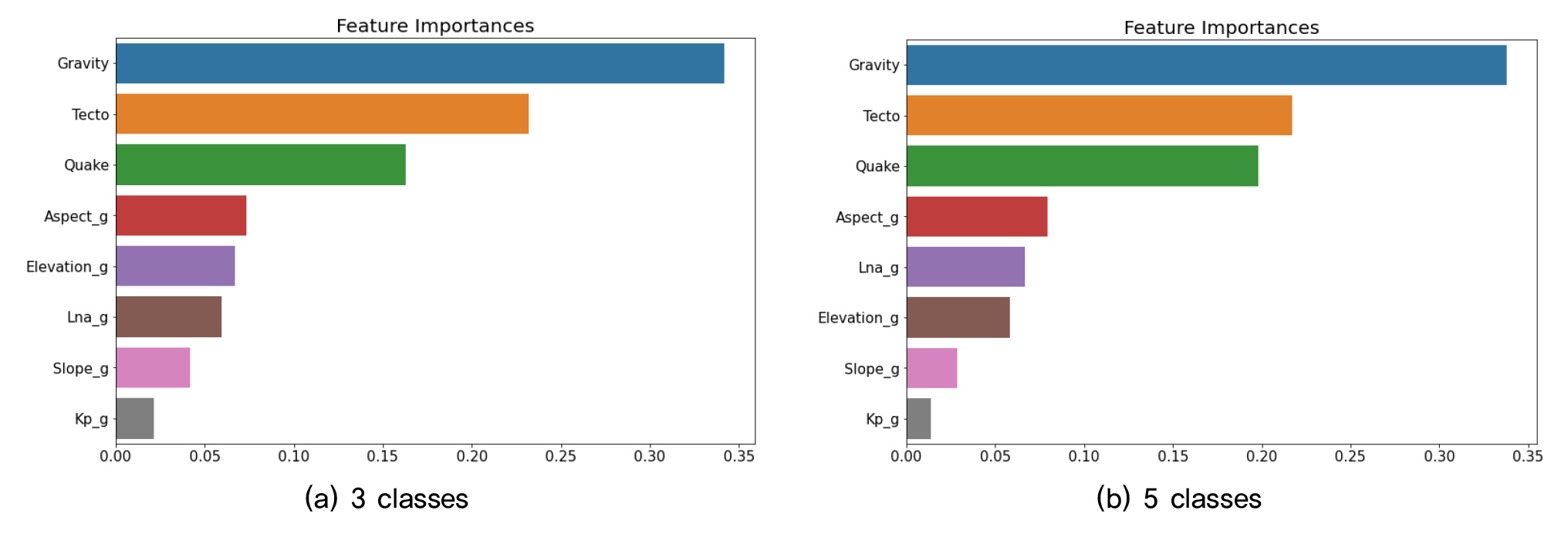
3개 분류기준에서 max_depth=10, min_samples_leaf= 4, min_samples_slpit=4, n_estimator=100일 때 최고 평균정확도 68.86%가 나왔고, 5개 분류기준에서 max_depth= 10, min_samples_leaf=4, min_samples_slpit=20, n_estimator= 100일 때 최고 평균정확도 58.23%가 나왔다. Fig. 3은 랜덤 포레스트를 통해 도출된 특성 중요도다. 두 경우 모두 중력이상의 특성 중요도가 가장 높았고 곡률의 특성 중요도가 가장 낮았다.
3.3 심층인공신경망(deep neural network, DNN)
심층인공신경망은 일반적인 인공신경망과 마찬가지로 복잡한 비선형 관계들을 모델링할 수 있다. 입력층과 출력층 사이에 여러 개의 은닉층들로 구성되어 있다. 입력값과 출력값의 상관관계를 신경망을 이용하여 구축하며 반복계산에 의해 개선되면서 결과값의 정확도가 올라간다. 각 층에서 입력값을 활성함수(activation function)를 통해 출력값으로 보낸다. 은닉층은 입력층의 출력값을 합성함수(combination function)를 이용해 합산하고 이에 가중치를 부여하여 하나의 입력정보로 내보낸다.
본 연구에서는 입력층과 출력층 사이에 3개의 은닉층이 있는 심층인공신경망으로 모델링하였다. 입력층의 노드(node) 수는 특성의 개수와 같은 8개, 활성함수는 ReLU(Rectified Linear Unit; Hahnloser et al., 2000)을 이용했다. 모든 은닉층의 노드 수는 입력층의 5배로 고정했고, 활성함수는 ReLU를 이용했다. 출력층의 노드는 분류해야 할 클래스(class)의 개수만큼 하였으며, 분류가 목적이기 때문에 활성함수로 Softmax를 이용했다. 손실함수(loss)는 categorical crossentropy, 최적화함수(optimizer)는 Adam(Adaptive moment estimation; Kingma and Ba, 2015)으로, 평가지표(metrics)는 모든 모델에 적용한 accuracy로 compile했다.
본 연구에서 출력층에 사용한 softmax 활성함수와 categorical crossentropy 손실함수는 분류해야 할 클래스가 3개 이상인 경우에 사용한다. 두 함수는 분류 클래스가 원-핫 형태로 제공되어야 하므로 OneHotEncoder를 통해 변환시켜주었다. 원-핫 표현을 통해 매핑된 벡터는 i번째 인덱스의 원소만 1이고 나머지는 모두 0으로 채운 N의 크기를 가진 벡터다. 즉, 유효토심의 클래스가 0번인 경우 3개의 분류기준에서는 [1, 0, 0], 5개 분류기준에서는 [1, 0, 0, 0, 0]이 된다.
인공신경망도 모델이 노이즈를 너무 많이 학습하게 되면 검증오류(validation loss)가 증가할 수 있다. 즉 에포크(epoch)가 너무 많아지면 과적합 문제를 일으킬 수 있다. 이를 방지하기 위해 loss의 감소, metrics의 증가 등의 개선이 없는 경우 미리 학습을 중단시킬 수 있다. 매 에포크마다 검증오류를 측정하여 검증오류가 증가하는 시점에서 종료할 수 있도록 earlystopping 방법을 사용했다. Table 6은 earlystopping 방법에 사용된 파라미터이다.
Table 6.
Deep neural network earlystopping parameter
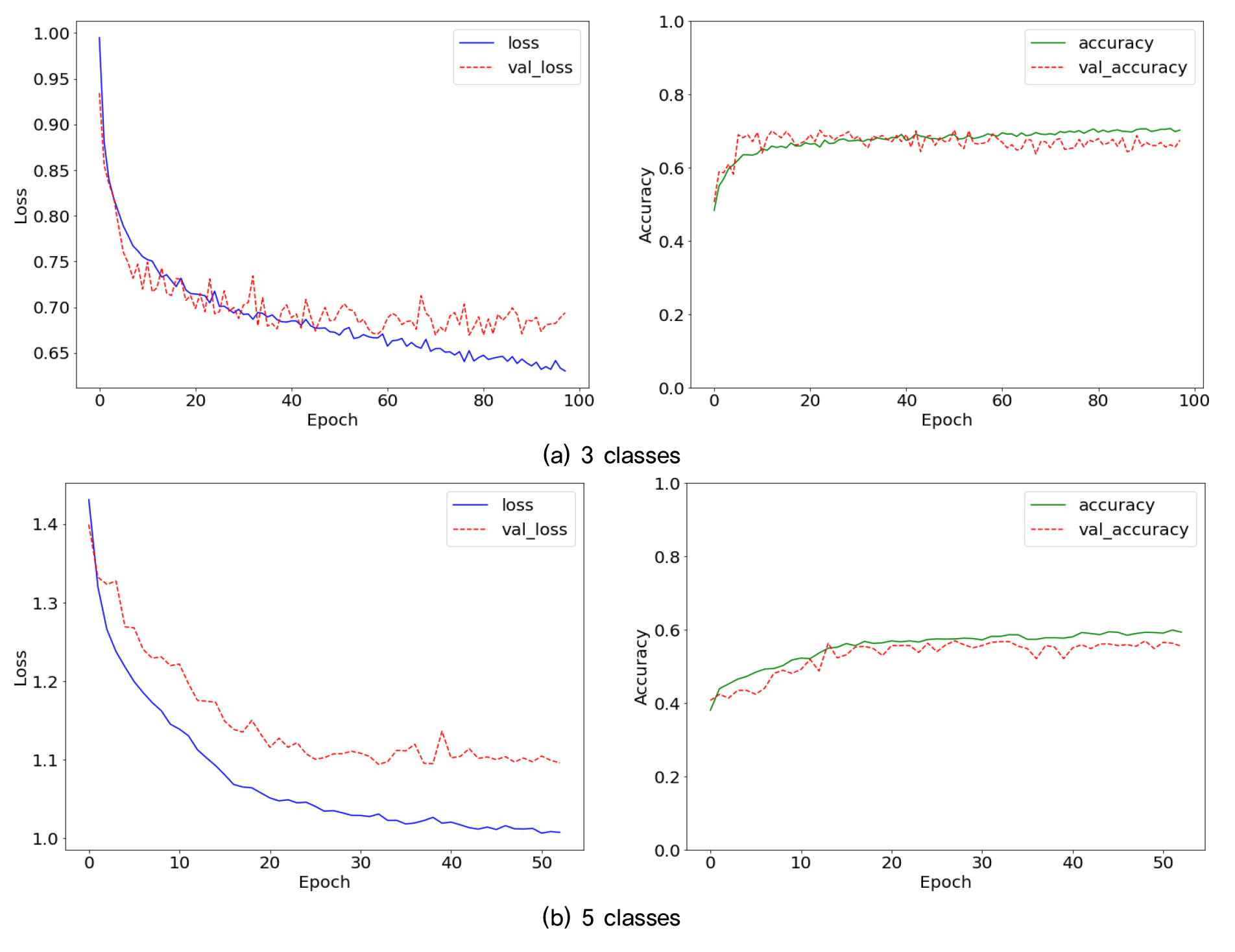
먼저 earlystopping 방법을 사용하지 않고 batch_size= 16으로, validation_split을 0.2로 두어 앞선 두 모델과 마찬가지로 학습데이터의 20%를 검증데이터로 사용했다. 300회의 에포크동안 학습시켰을 때, 3개 분류기준에서 60 에포크가 넘어가면서 validation loss가 0.7에 수렴했고 validation accuracy가 0.6과 0.7 사이로 수렴하는 모습을 보였다. 5개 분류기준에서는 validation loss가 50 에포크가 넘어가면서 다시 상승하는 모습을 보였고 validation accuracy 또한 50 에포크 이후로 수렴하면서 점점 하락하는 모습을 보였다. Earlystopping 방법을 사용하기 위해 loss가 20회의 에포크동안 개선되지 않을 때 훈련을 중지하게 설정하였다(Fig. 4). 예측 결과값은 원-핫 형태로 표현되며 이를 argmax를 통해 디코딩하여 예측결과를 얻어냈다.
3.4 모델 학습 결과
Table 7과 Table 8은 시험데이터를 이용해 예측한 결과다. 5개의 분류기준은 정확도와 F1-점수의 평균들의 차이가 3개의 분류기준에 비해 크다. 이는 5개의 분류기준은 값들의 분포가 불균형하다는 것을 의미하며 5개의 분류기준에서는 F1-점수를 통한 성능의 판단이 필요한 것으로 판단된다.
Table 7.
classes test data result
Table 8.
classes test data result
3개의 분류기준을 통해 예측했을 때 K-최근접 이웃과 랜덤 포레스트는 같은 정확도 수치를 보여줬지만 가중평균으로 봤을 때 랜덤 포레스트가 소폭 좋은 모습을 보였다. 심층인공신경망이 70%에 근접하면서 가장 좋은 성능을 보였다(Table 7, Fig. 5).
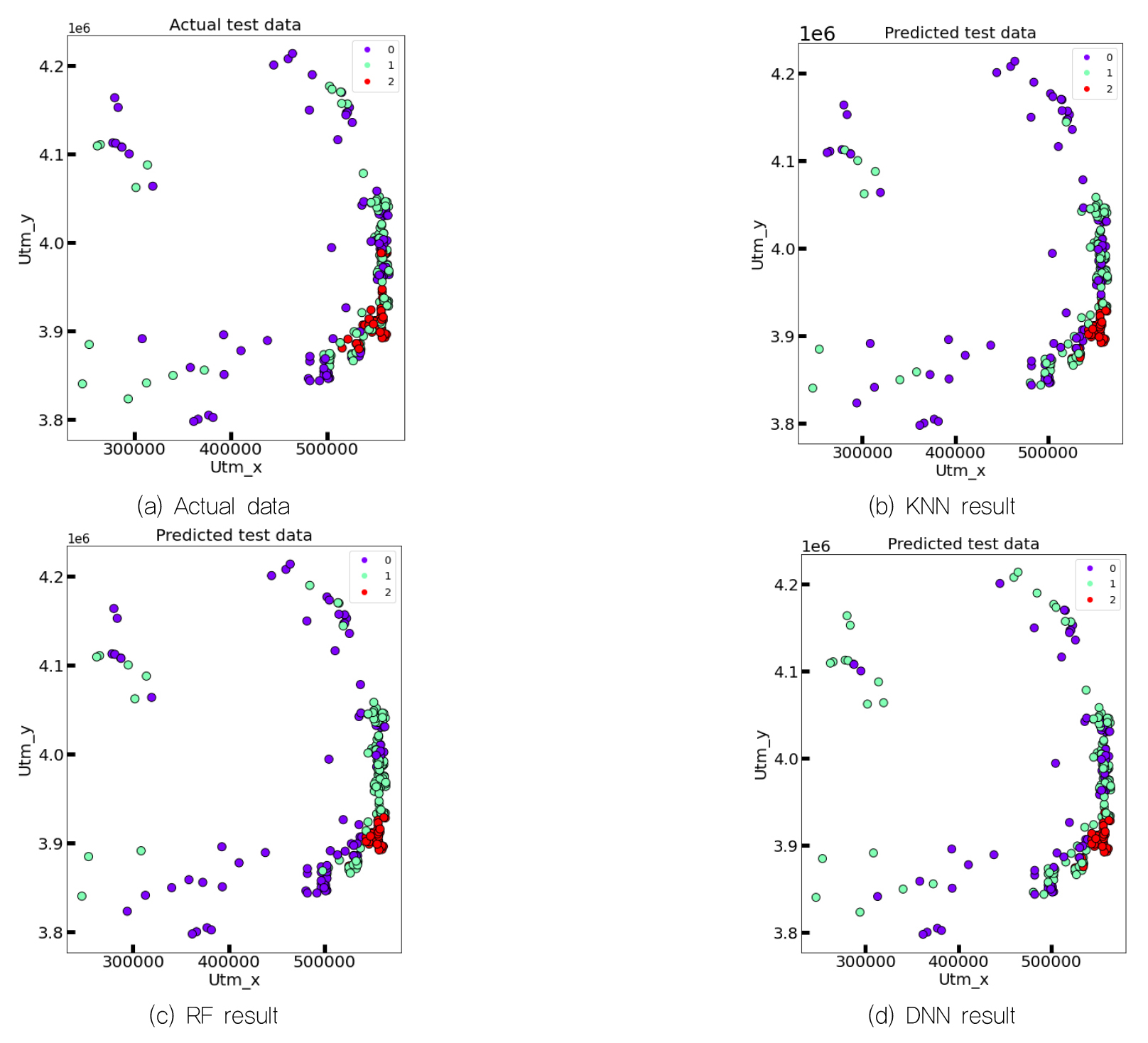
5개 분류기준은 3개의 분류기준보다 복잡한 모델이므로 정확도가 떨어질 것으로 예상했지만, 하락폭이 5% 정도로 크지 않다고 판단된다. F1-점수 가중평균을 통해 성능을 평가했을 때 랜덤 포레스트 모델이 가장 성능이 좋았다(Table 8, Fig. 6).
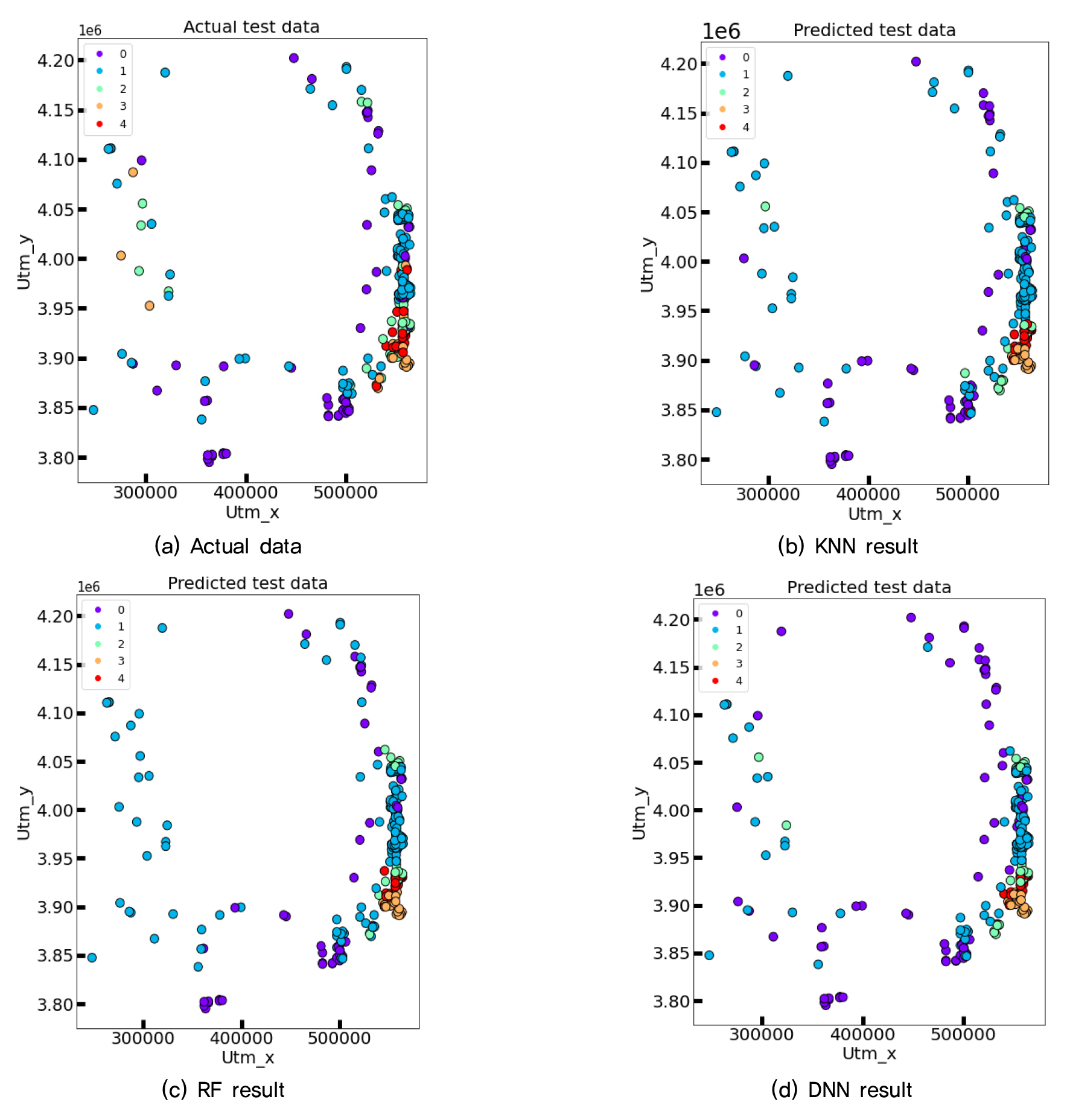
4. 요약 및 결론
유효토심의 깊이는 산사태의 재해위험도 분석에 필수적인 요소로 사용되기 때문에 신뢰성 높은 값을 사용하는 것이 필요하다. 회귀예측 선행연구는 국내외적으로 많이 존재했지만, 분류를 통한 예측에 대한 연구는 부족하다. 따라서 본 연구에서는 8개의 지형정보를 이용해 유효토심의 깊이를 3개와 5개의 분류기준으로 예측하고자 했다. 모델의 예측성능은 예측값과 실제값의 비교를 통해 계산되는 평가지표인 정확도, 정밀도, 재현율, F1-점수를 사용했다. 연구 결과 다음과 같은 결론을 도출하였다.
1) 3개 분류기준 K-최근접 이웃 K=48로 정확도=66.29%, F1-점수 가중평균=66.38%. 랜덤 포레스트 max_depth=10, min_samples_leaf=4, min_samples_slpit=4, n_estimator=100에서 정확도=66.29%, F1-점수 가중평균= 66.40%. 심층인공신경망 정확도=68.94%, F1-점수 가중평균=68.97%.
2) 5개 분류기준 K-최근접 이웃 K=23으로 정확도=62.88%, F1-점수 가중평균=61.36%. 랜덤 포레스트 max_depth=10, min_samples_leaf=4, min_samples_slpit=20, n_estimator=100에서 정확도=64.77%, F1-점수 가중평균=63.05%. 심층인공신경망 정확도 63.64%, F1-점수 가중평균 62.18%.
3) 3개 분류기준으로의 성능이 약 5%정도 더 정확하게 예측해냈지만, 이는 분류 클래스가 적어져서 데이터의 불균형이 5개 분류기준보다 완화되었기 때문으로 생각된다. 5개 분류기준은 F1-점수 가중평균과 정확도의 차이가 3개 분류기준보다 큰데 이는 데이터 분포의 불균형 때문으로 판단된다. 3개 분류기준에서는 3개 클래스 모두 60% 중반 이상의 정확도를 보였지만 5개 분류기준에서는 얕음과 보통 심도를 사이에서 그 결과가 극명하게 갈리는 모습을 보였다.
4) 각 모델들이 잘 예측해내는 클래스는 달랐지만 3개 분류기준에서는 심층인공신경망이 가장 성능이 좋다. 5개 분류기준에서는 랜덤 포레스트가 가장 성능이 좋지만 심층인공신경망과 차이가 크지 않다.
5) 각 클래스의 데이터 양의 불균형을 고려해 F1-점수에 더욱 초점을 맞출 필요가 있다. 각 클래스의 성능이 정확도(accuracy)에 비해 고르게 나오게 되었지만, 5개 분류기준에서 여전히 적은 클래스와 많은 클래스의 성능은 최대 2배까지 차이가 난다. 깊은 심도에서의 정확한 데이터가 부족하기 때문에 null 값으로 drop된 데이터가 많은 것 때문으로 보이며, 이는 표본의 수를 늘리면 해결될 것으로 생각된다.
6) 깊은 심도의 데이터가 동남쪽에 집중되어 있는 것도 예측 성능에 영향을 주었을 것으로 생각된다. 5개 분류기준에서 깊음 클래스는 전체 데이터의 약 10%밖에 차지하지 않지만 이를 예측하는 성능은 44 - 55%로 준수하다고 판단할 수 있다. 본 연구에서는 해안선을 따라서 예측의 가능성을 확인했지만, 수집범위를 확장해 보통 이상의 깊은 심도에서의 표본을 늘릴 필요가 있다.
7) 60% 중반정도의 성능은 현재 고려한 특성들과 등급화 기준이 최선이라고 할 수 없다. 하지만 이는 큰 지역을 획일적으로 가정하고 있는 현재보다 신뢰성 있는 값으로 분석/예측을 하는데 도움을 줄 것으로 생각된다. 또한 새로운 지형특성을 추가적으로 고려한다면 성능의 상승뿐 아니라 클래스 개수의 증가가 가능할 것으로 생각된다.
