

1. 서 론
2. 기존 연구결과와 이론적 배경
2.1 딥러닝; 합성곱방법(CNN)과 LSTM
2.2 합성곱방법의 구조
3. 연구 방법 및 절차
3.1 전이학습
3.2 균열탐지 절차(합성곱방법)
4. 균열탐지 결과 및 분석
4.1 예측데이터의 수렴성
4.2 중요변수별 예측결과 비교
5. 결 론
1. 서 론
인공지능기술은 사람의 행동을 모방하는 기술로 발전되어 왔다. 머신러닝은 인공지능기술의 한 분야로 “환경과의 상호 작용에 기반한 경험적인 데이터로부터 스스로 성능을 향상시키는 시스템을 연구하는 과학과 기술”로 정의되며, 기계가 일일이 코드로 명시하지 않는 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야이다(Samuel, 1959).
지도, 딥러닝, 피드포워드, 다층 퍼셉트론을 위한 최초의 일반 작업 학습 알고리즘은 Ivakhnenko et al.(1967)에 의해 발표되었다. Ivakhnenko(1971)는 그룹 데이터 처리 방법으로 훈련된 8개의 레이어가 있는 딥러닝 네트워크에 대해 설명했다. 다른 딥러닝 작업 아키텍처, 특히 컴퓨터 비전용으로 구축된 아키텍처는 Fukushima(1980)가 소개한 Neocognitron으로 시작되었다.
딥러닝이라는 용어는 Dechter(1986)에 의해 기계 학습 커뮤니티에 소개되었고 Aizenberg et al.(2000)이 부울 임계값 뉴런의 맥락에서 인공신경망에 도입했다. 1995년 Brendan Frey는 Peter Dayan 및 Hinton과 공동 개발한 wake-sleep 알고리즘을 사용하여 6개의 완전히 연결된 레이어와 수백 개의 은닉 유닛을 포함하는 네트워크를(이틀 동안) 훈련하는 것이 가능하다는 것을 보여주었다(De Carvalho et al., 1994). Hochreiter(1991)가 분석한 기울기 소실 문제를 포함하여 많은 요인이 느린 속도에 기여하고(Hinton et al., 1995; Hochreiter, 1991) 계층이 깊어질수록 학습이 어려운 기울기 소실문제(Vanishing Gradient)는 딥러닝 믿음신경망의 등장으로 해결되었다.
인공신경망의 얕은 학습과 딥러닝 학습(예: 순환 네트워크)은 모두 수년 동안 탐구되었다(Bengio, 1991; Deng et al., 1994; Hinton, 2007). 이러한 방법은 차별적으로 훈련된 음성 생성 모델을 기반으로 하는 비균일 내부 수작업 가우시안 혼합 모델/히든 마르코프 모델(GMM-HMM: Gaussian Mixture Model-Hidden Markov Model) 기술을 능가한 적이 없다. 신경 예측 모델에서 기울기 감소 및 약한 시간 상관 구조를 포함하여 과적합과 높은 시간 복잡도가 흔히 발생하는 문제 등의 주요 어려움이 분석되었다(Hinton et al., 2006; Bengio, 2012).
대상 구조물인 하수관거의 결함진단을 위한 인공 지능을 기반으로 하는 여러 시스템이 개발되었다(Xu et al., 1998; McKim and Sinha, 1999; Moselhi and Shehab-Eldeen, 1999; Yang and Su, 2008; Yang et al., 2011; Son and Lee, 2017). McKim and Sinha(1999)은 기본적인 이미지프로세싱 기법들을 이용하여 하수관 내 균열(crack)의 정보를 추출하였고, Moselhi and Shehab-Eldeen(1999)은 여기에 더하여 인공신경망 방법을 적용하였다. Yang and Su(2008)는 머신러닝을 적용한 발전된 영상처리 방법을 연구하였고, Yang et al.(2011)은 하수관로 촬영 영상의 품질평가 방법을 제안하였으나 하수관로와 같이 어둡고 장해물이 많은 환경에서 이동하면서 촬영하는 영상의 품질은 매우 낮을 수밖에 없기 때문에 주관적 판단에 의한 에러가 발생하였다(Son and Lee, 2017).
Wang et al.(2021)은 Kalman필터를 사용하여 손상의 종류별 손상검출을 연구하였다. Jiang et al.(2021)은 하수관거내의 BOD(Biochemical Oxygen Demand), COD(Chemical Oxygen Demand)등 다양한 소스의 데이터를 사용한 수질예측에 RNN(Recurrent Neural Network), GRU(Gated Recurrent Unit)와 LSTM(Long Short-Term Memory) 등의 딥러닝기법을 적용하였다. Dang et al.(2021)은 딥러닝모델에서 블록구조의 미세조정과 불균형 데이터의 앙상블해석을 통하여 하수관거내부의 손상검출의 정확도를 높였다. Fig. 1은 인공지능기술의 역사를 보인 것이다.
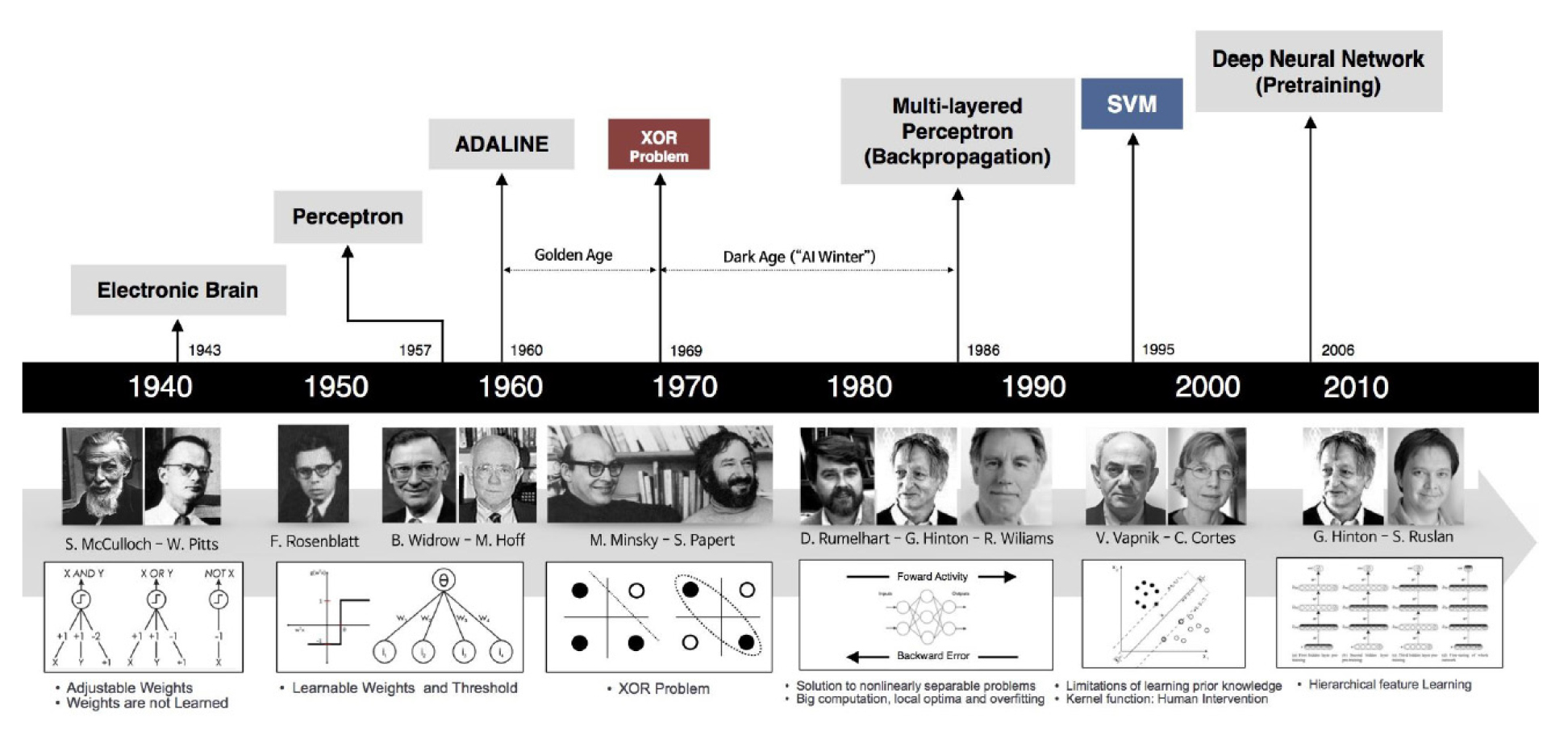
본 연구에서는 실제 하수관거구조물에서 균열검출을 평가하기 위하여 합성곱방법(CNN)에 의한 균열/비균열을 분류하고, 분류된 데이터를 덧붙여 업데이트된 Google.net의 데이터베이스를 이용하여 장단기 기억손실프로그램에 의한 균열예측을 하기 위한 목적으로 주어진 영상데이터를 분류하고 평가하였다.
균열검출 데이터에서 시계열 예측 성능을 향상시키기 위해 딥러닝 방법인 합성곱방법(Convolutional Neural Network, CNN)과 LSTM을 결합하는 방법을 제시하는 것을 목표로 한다. 이를 위해 우선, 균열검출을 제외한 측정 데이터를 합성곱방법에 입력하여 현재 환경상황을 분류하고, 과거 동일 환경상황에서 추출한 균열검출 추세정보와 직전의 균열검출 데이터를 활용하여 LSTM에 입력한 다음, 최종적으로 미래의 균열검출 값을 예측하는 방법을 제안한다.
제안 방법의 효과를 검증하기 위해 균열검출 실험데이터를 활용하여, 기존 LSTM과 제안 방법인 CNN-LSTM 결합 모델의 예측 정확도를 비교하는 실험과 함께, 균열검출을 나타내는 값이 급격히 변화하는 시점을 예측하는 분류 정확도 시험을 수행하여 예측 모델이 급격히 변화하는 시계열 데이터에 얼마나 효과적으로 대응하는지를 실험하였다.
2. 기존 연구결과와 이론적 배경
2.1 딥러닝; 합성곱방법(CNN)과 LSTM
딥러닝은 머신러닝의 한 분야로써 대부분 딥러닝 뉴럴네트워크 구조로 이루어진다. 이는 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화를 시도하는 기계학습 알고리즘의 집합으로 학습 단계(Training Phase)와 테스트 단계(Test Phase)로 구성되어, 데이터의 양이 증가할수록 효율적인 역량을 보여준다. 딥러닝은 아래와 같은 세 가지 기술적 요소로 인해 높은 정확성을 갖추게 된다.
1) 레이블이 지정된 대량의 데이터 집합(ImageNet 및 PASCAL VoC: PASCAL Visual Object Classes 등)에 간편하게 액세스
2) 향상된 연산 능력; 고성능 GPU(Graphics Processing Unit)를 사용하여 딥러닝에 필요한 대량의 데이터를 빠르게 학습할 수 있으므로 학습 시간이 몇 주에서 몇 시간으로 단축된다.
3) 전문가가 구축한 사전 학습된 모델, 전이학습이라는 기술을 사용하여 새로운 인식 작업을 수행하도록 AlexNet 등의 모델을 재학습할 수 있다. AlexNet은 1000개의 서로 다른 객체를 인식하기 위해 130 만 개의 고해상도 이미지를 학습해야 했지만, 그보다 훨씬 더 작은 데이터 세트로 정확한 전이학습을 달성할 수 있다.
최근 빅데이터, 인공지능 관련 기술의 발전으로 인해 SOC(Social Overhead Capital) 구조물의 균열진전에 대한 시계열 예측 관련 연구가 진행되고 있다. 하지만 균열진전을 나타내는 데이터가 다양하게 변하는 특성을 가지고 있어서 기존의 시계열 예측방법으로는 현장에서 사용할 수 있는 수준의 정확도를 내지 못하고 있다.
기존 기계학습과 달리 합성곱방법은 컨벌루션층(convolution layer)를 적용하여 특징의 자동 추출이 가능하고, 대규모 병렬 처리가 가능하다. 과거, 균열진전과 같은 구조물 손상영역의 시계열 예측은 지수 평할, ARIMA(Auto-Regressive Integrated Moving Average)와 같은 통계적 모델을 주로 활용하였지만 최근에는 LSTM과 같은 딥러닝 기술을 활용한 예측이 더 높은 예측 성능을 제공하는 것으로 알려져 있다. 특히 LSTM은 정밀센서와 같이 IoT 기반의 정밀 데이터 영역에서 더욱 효과적이다(Hwang et al., 2018; Nguyen et al., 2018).
한편, LSTM은 합성곱방법과 달리 대규모 병렬처리가 가능하지 않지만, RNN과는 다르게 원하는 시기에 진행 및 제어 할 수 있는 입력, 출력, 망각 게이트가 있다. LSTM의 게이트는 메모리 블록을 은닉노드에 배치할 수 있는 장점이 있는데, 메모리 블록이 모든 데이터를 기억할 수는 없지만, 합성곱방법의 장기의존성 문제를 해결할 수 있다. 또한 LSTM은 균열을 예측할 때, 동일하게 sequence 벡터를 모델링할 수 있기때문에 정확도를 향상시킬수 있다.
2.2 합성곱방법의 구조
2.2.1 기본 합성곱방법(Basic CNN)
합성곱방법은 이미지 및 비디오를 사용한 딥러닝에 가장 많이 사용하는 알고리즘 중 하나이다. 합성곱방법은 다른 신경망과 마찬가지로 입력 계층, 출력 계층 및 두 계층 사이의 여러 은닉 계층으로 구성된다(Fig. 2). 특징 검출 계층은 데이터에 대해 세 가지 유형의 작업, 즉 컨벌루션, 풀링 또는 ReLu(Rectified Linear Unit) 중 하나를 수행하다. 컨벌루션은 입력 이미지를 컨볼루션 필터 집합에 통과시키고, 각 필터는 이미지에서 특정 특징을 활성화시킨다.
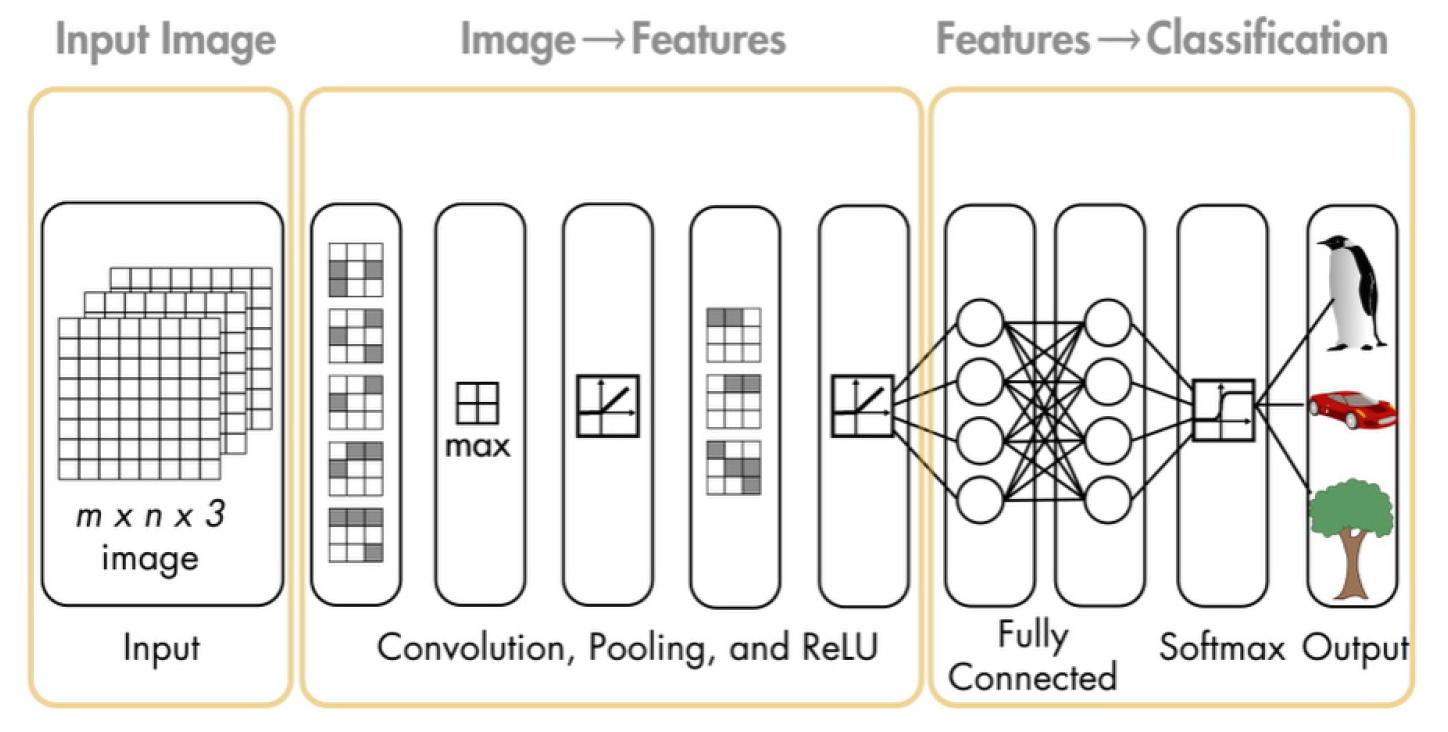
풀링은 비선형 다운샘플링을 수행함으로써 출력을 간소화하여, 네트워크가 학습해야하는 파라미터의 수를 줄이다. ReLu(Rectified Linear Unit)는 음수 값을 0에 매핑하고 양수 값을 유지하여 더 빠르고 효과적인 학습을 가능하게 하다. 이러한 세 가지 작업이 수십 개 또는 수백 개의 계층에서 반복되어 각 계층은 서로 다른 특징들을 검출하도록 학습된다(Fig. 3).
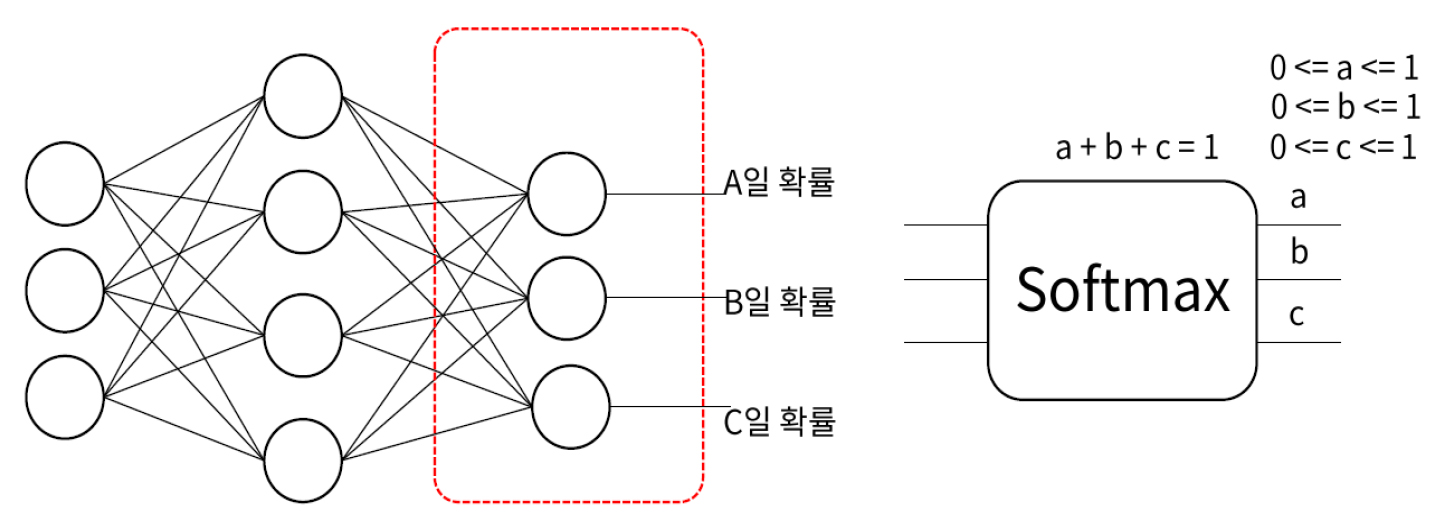
합성곱 계층에서는 영상의 크기는 그대로이며, 영상의 채널수가 달라진다. 합성곱 계층에 의해서 추출된 결과는 공간적 특징이 있으며 특징 맵(feature Map)이라고 한다. 특징 검출 후 합성곱방법의 아키텍처가 분류로 이동한다. 끝에서 두 번째 계층은 K 차원의 벡터를 출력하는 완전 연결 계층이다. 이 벡터에는 분류되는 이미지의 각 클래스에 대한 확률이 포함된다. 합성곱방법 아키텍처의 마지막 계층에서는 Softmax 함수를 사용하여 분류 출력을 제공한다. 다중 클래스 분류 문제를 해결하기 위해서 마지막 계층에는 Fig. 4와 같이 Softmax활성 함수를 사용한다.
2.2.2 기존의 훈련된 데이터
딥러닝을 처음 사용하는 경우 쉽고 빠르게 시작하는 방법은 100만 개 이상의 이미지에 대해 사전 학습된 합성곱방법인 AlexNet과 같은 기존 네트워크를 사용하는 것이다. AlexNet은 이미지 분류에 가장 일반적으로 사용된다. AlexNet은 다양한 품종의 개, 고양이, 말 및 기타 동물과 키보드, 컴퓨터 마우스, 연필 및 기타 사무용품을 포함한 1000개의 다양한 범주로 이미지를 분류할 수 있다.
이전 예제에서는 분류하려고 했던 이미지와 유사한 이미지를 기반으로 GoogleNet이 학습되었으므로 네트워크를 수정하지 않고 그대로 사용했다. 전이학습은 한 가지 유형의 문제에 대한 지식을 연관성이 있는 또다른 문제에 적용하는 접근 방식이다. 이 경우 네트워크의 마지막 3개 계층을 간단히 잘라내고 자체 이미지로 재학습한다.
2.2.3 RNN과 LSTM
기본적인 RNN의 구조는 이전의 state를 함께 input으로 주어 이전 input과의 연관성을 함께 학습해 나간다. 하지만 이러한 구조는, input의 길이가 길어질수록, 네트워크의 뒷부분으로 갈수록 앞부분의 정보를 잊어버리는 문제점이 있다. LSTM은 이러한 문제점을 극복하기 위해 제시되었다. Fig. 5는 LSTM의 구조이다. 각 기호의 의미는 Fig. 6과 같다.
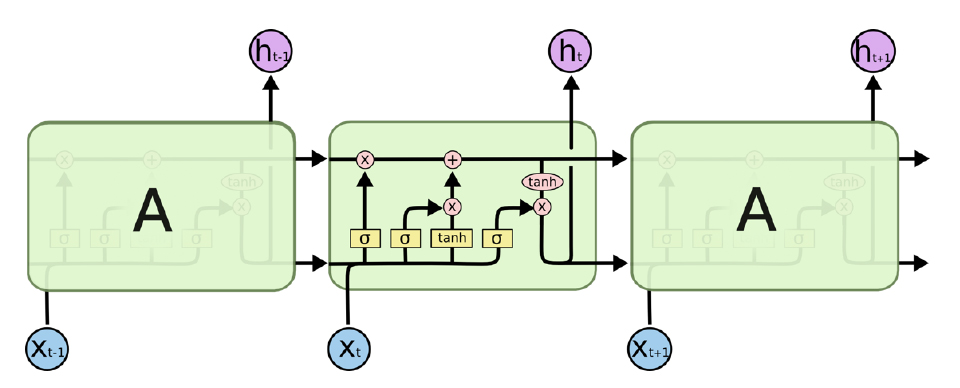

LSTM 알고리즘의 핵심이 되는 아이디어는 Cell state(Ct)이다. LSTM에서 Cell state의 흐름만 보면, 간단한 선형 연산만이 가해지면서 다음 state로 정보가 전달된다. LSTM은 gate라고 불리는 구조를 통해 다음 cell로 흐를 정보의 양을 제어한다. Sigmoid layer를 거친 값이 곱해지는 구조로 되어 있다. Sigmoid는 0부터 1 사이의 값을 출력하므로, 이는 '얼마만큼의 정보를 cell state에 전달할지'를 결정하는 역할을 한다. 예를 들어 sigmoid를 거친 값이 0이 된다면 '다음 cell로 정보를 전달하지 않음'을 의미하고, sigmoid를 거친 값이 1이 된다면 '모든 정보를 그대로 전달함'을 의미하게 된다. LSTM은 3개의 gate를 포함하고 있고, 각각의 의미는 Fig. 7과 같다.
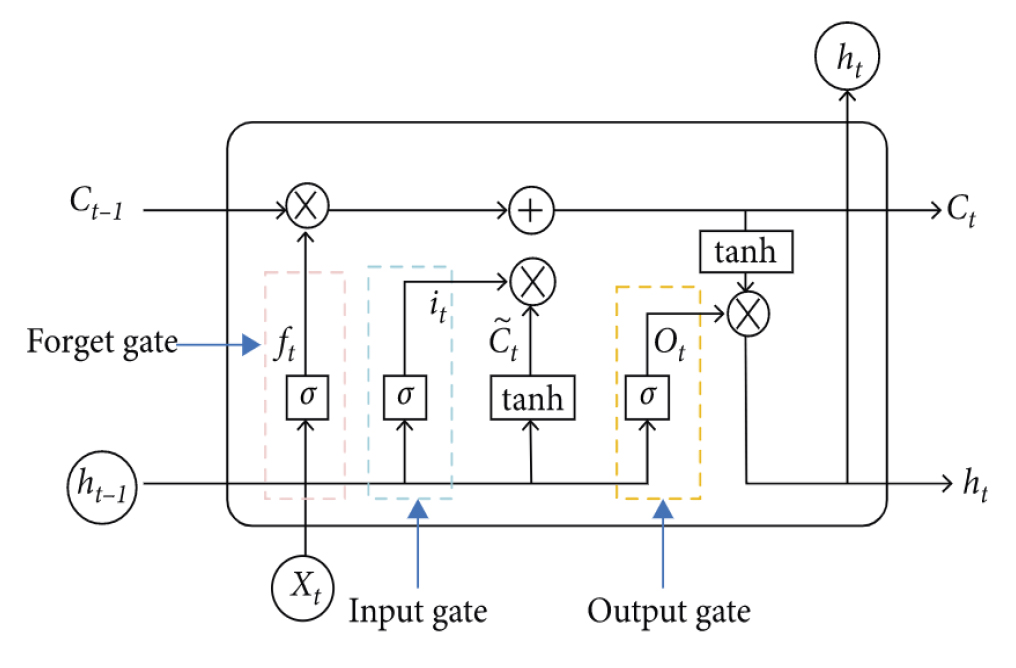
첫 번째 gate는 이전 cell state에서 다음 cell state로 전달할 정보의 양을 결정하는 역할을 한다. 이전 cell의 hidden state(ht)와 이번 cell의 input 값을 이용해 0부터 1 사이 값을 출력하고, 이를 이전 cell state에 곱해준다. 두 번째 gate는 다음 cell state에 추가할 정보를 결정하는 역할을 한다. Tanh layer을 통해 cell state의 후보(candidate value)가 되는 값을 결정하고, sigmoid layer를 통해 이 후보 값 중 어떤 값을 얼마만큼 추가할 것인지를 결정한다. 두 값을 곱해 cell state에 더해준다.
마지막으로 hidden state 값을 결정한다. Cell state가 다음 cell로 계속 흘러가는 값이라면, hidden state는 일반적인 합성곱방법에서와 같이 중간 layer의 output 값이다. Hidden state는 cell의 output으로 출력되기도 하고, 다음 cell로 전달되기도 한다. 두 번째 layer와 반대 과정을 거친다.
Cell state의 값을 tanh layer에 통과시켜 값을 추출하고, sigmoid layer을 통해 어떤 값을 얼마만큼 사용할 것인지를 결정한다. 두 값을 곱해 다음 hidden state의 값을 결정한다. 결론적으로 gate에서 tanh layer은 정보를 추출하는 역할을 하고, sigmoid layer는 사용할 정보의 양을 결정하는 역할을 한다.
3. 연구 방법 및 절차
3.1 전이학습
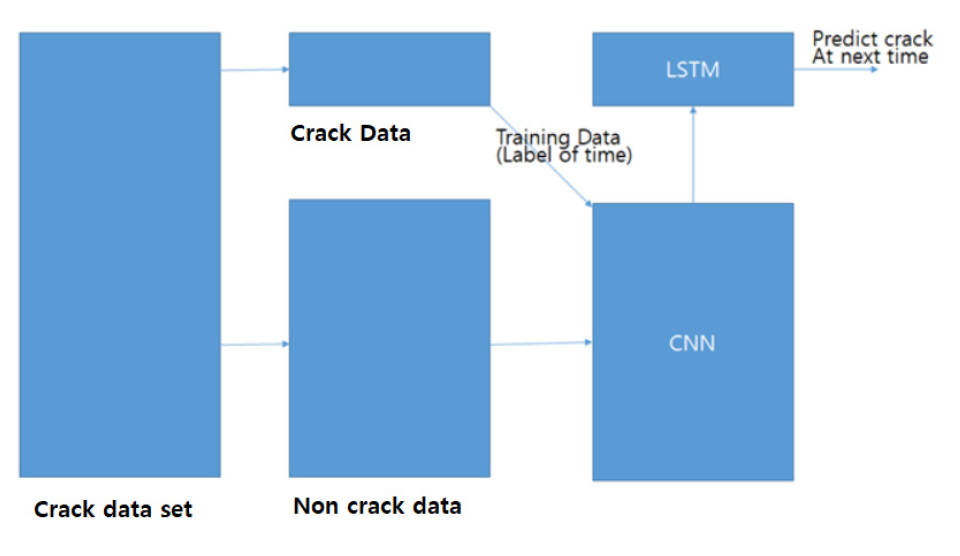
Fig. 8에 보이는 바와 같이 본 연구에서는 CNN-LSTM의 합성모델을 사용하며, 그 결과를 합성곱방법과 비교하였다. 또한 부족한 균열 데이터의 분류를 위하여 GoogleNet의 전이학습을 이용하였다. 전이학습(Transfer Learning)이란 딥러닝을 적용할 때, 충분한 데이터를 가지고 있지 않거나 특정 목적(균열 검출 등)을 위한 딥러닝 네트워크를 설계하는데 익숙하지 않을 때 기존의 딥러닝 네트워크를 활용할 수 있는 매우 유용한 방법이다.

일반적으로 VGG(Very Deep Convolutional Networks), ResNet(Deep Residual Network), GoogleNet등 이미 이러한 사전에 학습이 완료된 모델(Pre-Training Model)을 가지고 우리가 원하는 학습에 미세 조정 즉, 작은 변화를 이용하여 학습시키는 방법으로 이미 학습된 weight들을 전송하여 자신의 모델에 맞게 세부 조정(fine-tuning) 학습을 시키는 방법이다.
3.2 균열탐지 절차(합성곱방법)
Fig. 9는 CNN-LSTM합성모델의 연산 흐름도를 보여준다. GoogleNet을 이용한 사전전이학습을 거친 데이터베이스의 합성곱방법계층과 전 결합계층의 사이에 LSTM계층이 위치하여 입출력시의 데이터양을 조절하게 된다.
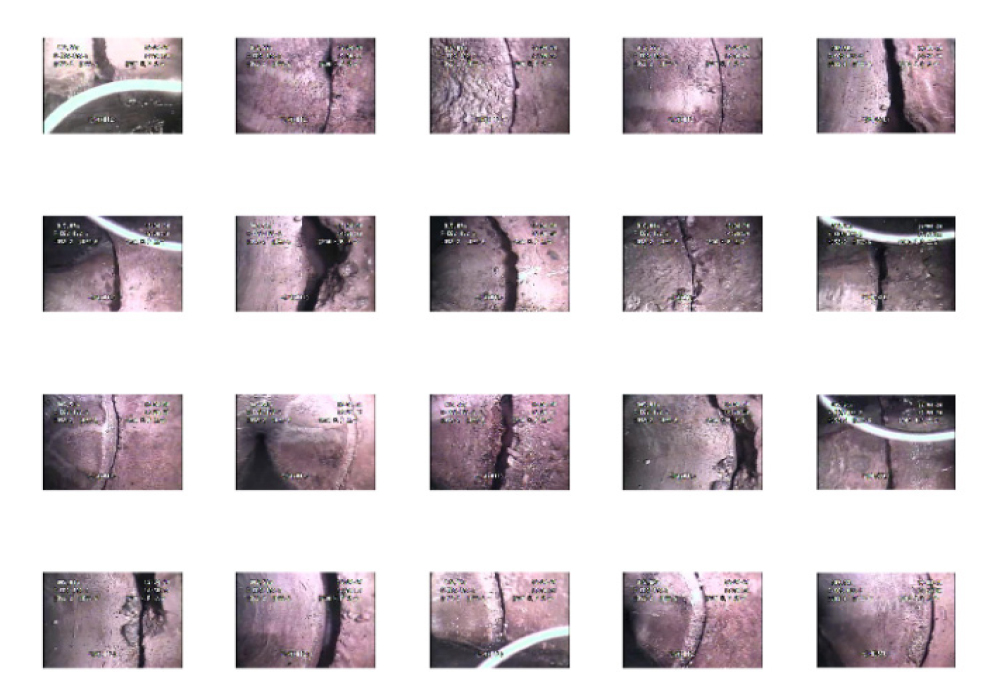
하수관거 CCTV영상 정보는 76,800화소(240×320)로 매우 저해상도이며 200초 영상이다. 초당 1개씩 총 200개의 영상에서 영상의 시작 부분 등 필요 없는 부분과 중복된 영상을 제외하여 총 110개 영상을 해석 대상으로 선정하였다. 110개 영상 중에서 균열 영상 55개(c1~c55), 비균열 영상 55개(n1~n55)이며, 샘플 데이터 20개씩을 Fig. 10 및 Fig. 11에 나타내었다(Son and Lee, 2017).
4. 균열탐지 결과 및 분석
4.1 예측데이터의 수렴성
균열탐지절차에 제시된 CNN-LSTM 합성모델의 수렴성을 Fig. 12 및 Fig. 13에 도시하였다. 아래 절 4.2에 논의된 바와 같이 최대 Epoch수가 증가함에 따라서 수렴성은 증가한다. 다만 수렴성에서 학습률의 영향도 큰데 학습률이 커질수록 수렴성의 초기 진동폭은 증가하고 있으며, Epoch수가 동시에 감소시킨 경우에 특히 진동폭이 증가하였다.
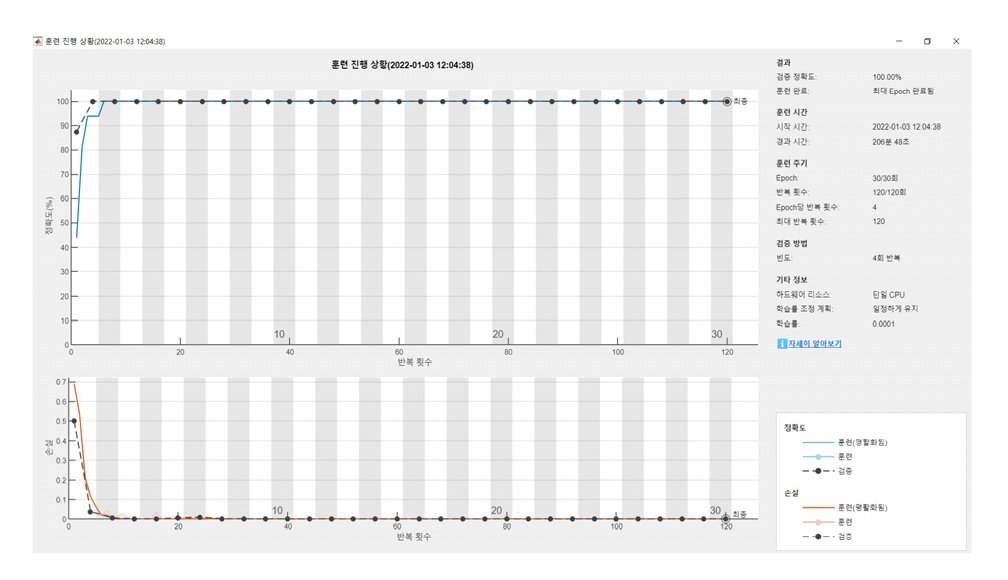
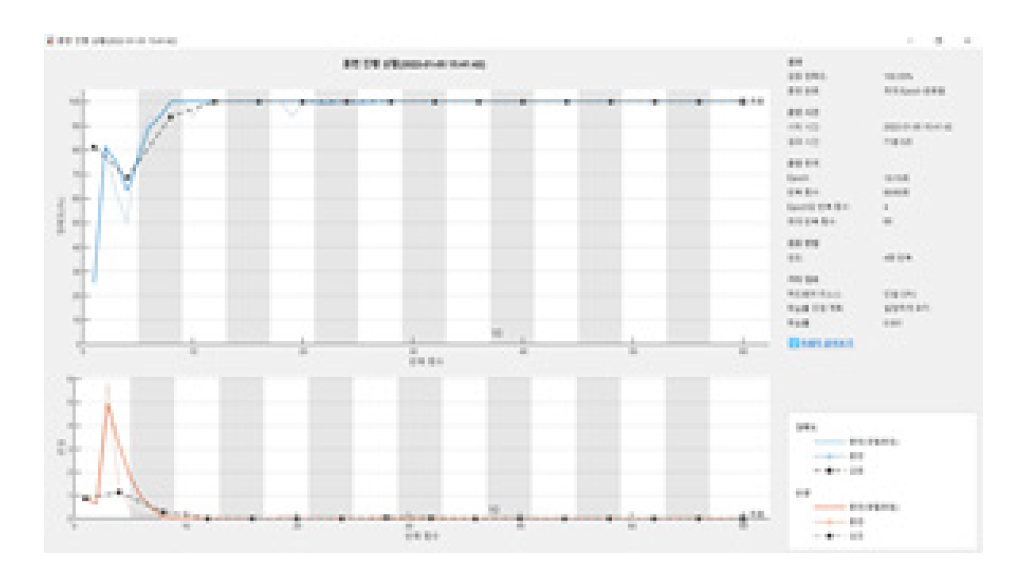
결과적으로 4.2절에서 관찰된 바와 같이 최대 Epoch수는 30이상으로, 훈련데이터는 70%이상으로, 학습률은 0.001이하로 결정하였다.
4.2 중요변수별 예측결과 비교
본 연구에서는 훈련데이터를 변화시키면서 동시에 Epoch수와 학습률을 변화시켜서 합성곱방법 및 CNN-LSTM 합성모델의 수렴성을 비교하였다. Fig. 14와 Fig. 15에 비교된 바와 같이 훈련데이터가 60%일 때 합성곱방법모델은 CNN-LSTM모델과 비교하여 낮은 수렴도를 보이고 학습률이 작아질수록 수렴성이 증가하였다. 수렴성의 비교를 RMSE(Root Mean Square Error)로 표시하면 10% 이상 증가된 오차율(증가된 오차율)을 보여주고 있다.
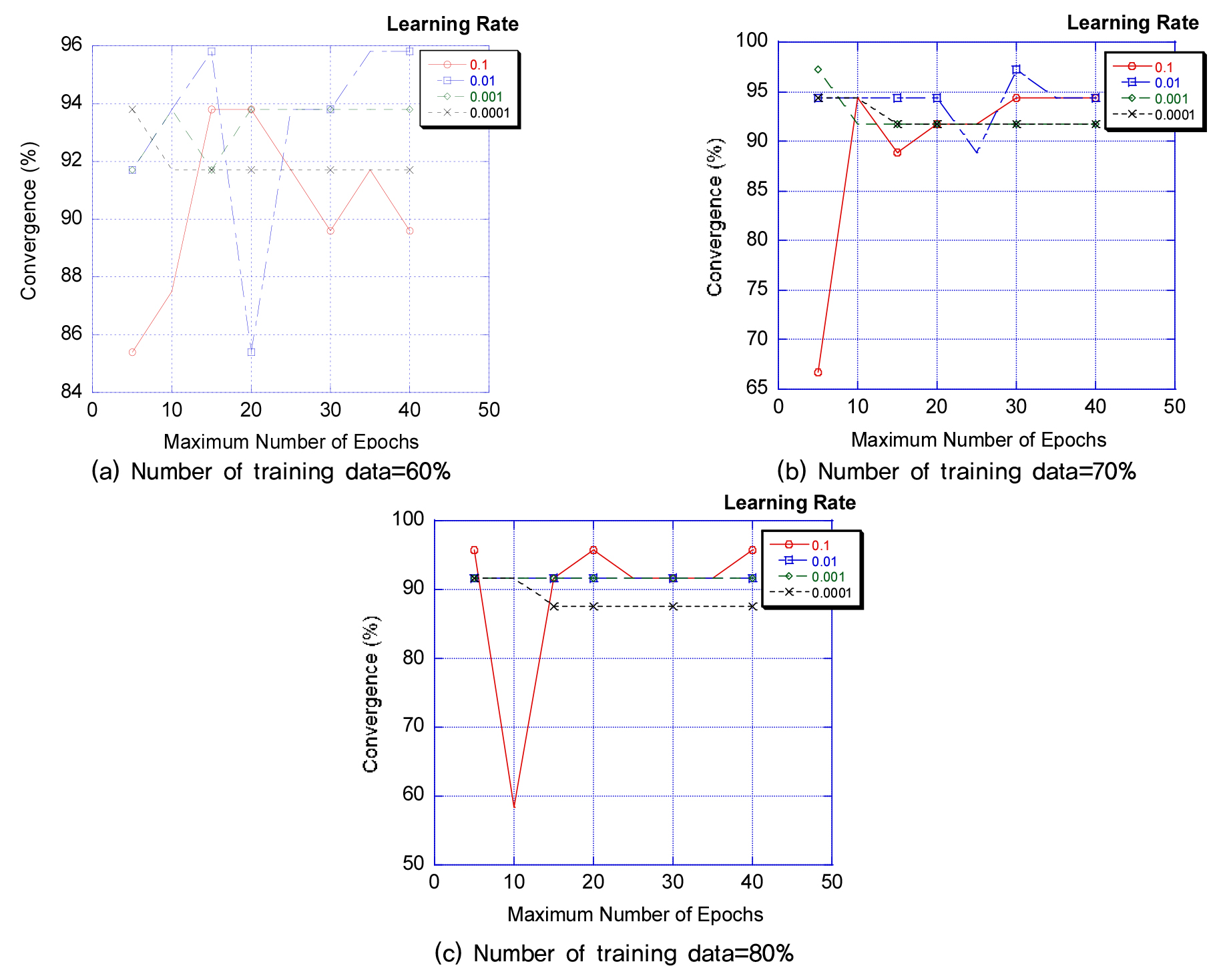
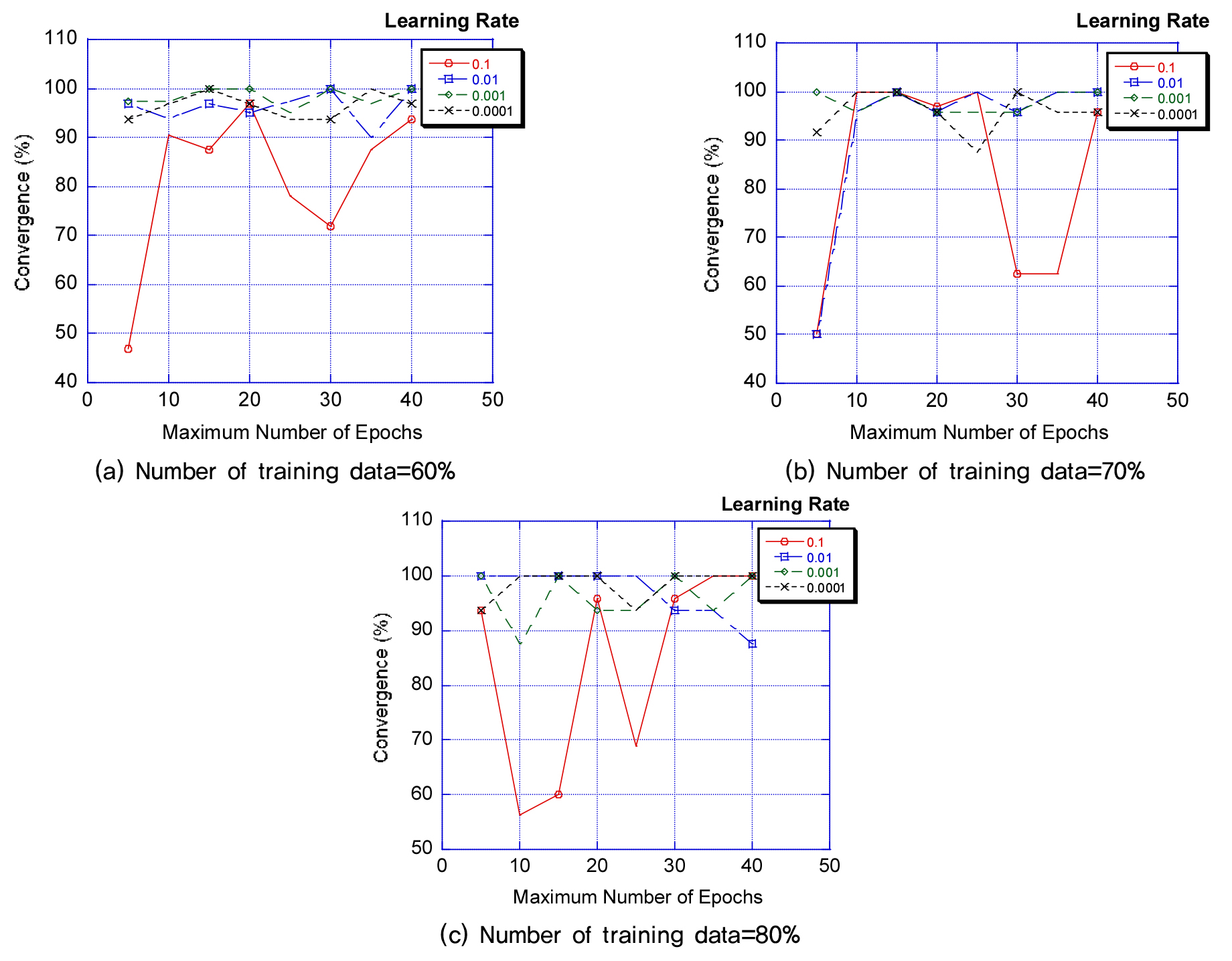
그러나 이러한 변수설계에서 초기학습률을 0.001에서 0.0001로 고정시키면 다른 결과를 보여주는데 이는 LSTM의 경우 작은 학습률을 사용하면 수렴성이 급격히 좋아지기 때문이다. 그러므로 초기 학습률 0.001과 0.0001을 사용하는 경우의 오차율 예측에서 87.5/95.9로 8%이상, RMSE는 오차율에서 7.77대 4.66으로 약 40% 감소된 에러를 보여준다.
Fig. 14와 Fig. 15에서는 훈련데이터가 60~80%까지 변화하는데 두 개의 모델 모두에서 초기학습률의 감소에 따른 수렴성의 개선을 볼 수 있으며, Fig. 14(a), (b), (c)와 Fig. 15(a), (b), (c)의 비교에서 합성곱방법의 균열탐지 결과는 최대 Epoch의 수가 작은 경우에는 CNN-LSTM보다 약간 개선된 예측을 보여주지만 Maximum Epochs가 증가할수록 수렴성이 비교적 저하되는 구간을 볼 수 있다. 특히 초기학습률이 0.001이하인 경우에는 앞서서 논의된 바와 같이 RMSE값이 비교적 큰 값을 보여서 CNN-LSTM 합성모델보다 부정확한 예측값을 보여준다.
Fig. 14와 Fig. 15에서 훈련데이터와 무관하게 Maximum Epochs가 증가할수록 두 개의 모델은 수렴성의 개선을 보여주지만 합성곱모델 예측결과는 90~95%의 수렴성을, CNN-LSTM모델은 95~100%의 수렴성을 보여준다.
5. 결 론
본 연구에서는 하수관거 내부에서 촬영된 균열 데이터를 활용하여 균열검출에 대한 시계열 예측 성능을 개선하기 위해 GoogleNet의 전이학습과 CNN-LSTM 합성 방법을 제안하였다. LSTM은 합성곱방법의 장기의존성 문제를 해결할 수 있으며 공간 및 시간적인 특징을 동시에 고려할 수 있다.
제안 방법의 성능을 검증하기 위해 하수관거 내부 균열 데이터를 활용하여 학습데이터, 초기학습률 및 최대 Epochs를 변화하면서 RMSE를 비교한 결과 모든 시험 구간에서 제안 방법의 예측 성능이 우수함을 알 수 있다. 초기학습률 0.001과 0.0001을 사용하는 경우의 오차율 예측에서 87.5/95.9로 8%이상, RMSE는 오차율에서 7.77대 4.66으로 약 40% 감소된 에러를 보여준다. 그러므로 균열검출의 예측에서 제안 방법이 효율적인 것을 검증하였다.
향후 연구에서는 Fig. 10과 Fig. 11의 영상 외에도 균열로 인식하기 어려운 Infiltration등의 영상데이터를 포함시켜 분류실행률을 검토해야 한다. 또한, 본 연구에서 수행한 하수관거 CCTV영상 정보는 76,800화소(240×320) 보다도 더 낮은 저해상도에 대한 균열 영상을 포함시켜 데이터에 대한 향상된 가공기술을 개발한다면 보다 나은 결과를 도출할 수 있을 것으로 예상된다. 기존 합성곱방법 단독 모델과 비교함으로써 본 연구를 통해 확보된 제안 방법과 실험 결과를 활용할 경우 콘크리트 구조물의 균열데이터뿐만 아니라 시계열 데이터가 많이 발생하는 환경, 인문과학 등 다양한 영역에서 응용이 가능하다.
