

1. 서 론
2. 선행 연구 및 이론적 배경
2.1 선행 연구
2.2 워드 임베딩 벡터
2.3 코사인 유사도
3. 키워드 추출 및 검색 기법 생성
3.1 표본 기사 선정 및 키워드 추출
3.2 워드 임베딩 벡터 구축
3.3 유사도 검사 및 군집 생성
3.4 검색 기법 추출
3.5 최적의 키워드 및 군집 선정 결과
4. 결론 및 고찰
1. 서 론
4차 산업혁명이 대두됨에 따라 클라우드 서비스와 빅데이터를 기반으로 한 온라인 플랫폼 및 아카이브 서비스가 다양한 분야에 적용·확대되고 있다. 특히 언론 분야의 경우 한국언론진흥재단이 제공하는 ‘빅카인즈(BigKinds)’가 대표적인 사례라고 할 수 있다(BigKinds, 2023). 이는 종합일간지, 지역 일간지, 방송사 등 54개의 언론사로부터 텍스트 기사, 사진, PDF의 DB를 수집하여 뉴스 카테고리에 맞추어 자동 분류하고 핵심 키워드를 추출한다. 또한 ‘AND’와 ‘OR’ 및 형태소 단위의 검색 기능을 제공하여 원하는 기사를 세부적으로 분류할 수 있다. ‘AND’의 경우 앞뒤의 단어가 모두 포함된 기사를 분류하고, ‘OR’은 앞뒤의 단어 중 하나라도 포함된 기사를 분류하게 된다. 추가적으로 제외 키워드를 설정해 해당 기사를 제외하는 것도 가능하다. 또한, 사용자에 의해 분류된 기사를 통해 관계도 분석, 키워드 트렌드, 연관어 분석이 가능하며 시각화 자료로는 그래프, 워드 클라우드 등이 있다. 그러나 매일 최신화되어 축적되는 정보의 양에 비해 이를 분류하는 체계 및 검색 기법은 미약한 것이 현 실정이다. 예를 들어, 빅카인즈의 통합 분류 체계는 정치, 경제, 사회, 문화, 국제, 지역, 스포츠, IT_과학 등 총 8개의 카테고리로 이루어져 있으며, 여기에 추가적으로 결과 내 재검색을 통해 세부 분류가 가능하다. 그러나 실제로 사용자가 원하는 세부 목적에 맞는 기사를 추출하기 위해서는 어떠한 키워드 및 검색 식을 사용해야 하는지가 난제이다. 한 예로 ‘북한 건설 관련 동향 파악’을 위해 기사를 추출한다고 가정하면, 빅카인즈의 카테고리 및 검색 기능을 활용하여 기사 분류를 하였을 때 검색에 사용할 최적의 키워드에 대한 기준이 불명확하다. 또한, 이를 분류하는 기존의 8개의 카테고리 또한 광범위하다. 이와 더불어 최적의 키워드를 추출했다고 할지라도 키워드를 검색 양식에 맞추어 어떠한 방식으로 입력해야 되는지도 알 수 없다.
이러한 문제점을 해결하고자 본 논문은 사용자의 세부 목적에 따른 최적의 검색 키워드 추출과 함께 검색 기법을 생성하는 방법론을 제안하고 있으며, ‘국내외 북한 건설 관련 동향 파악’을 예시로 적용하여 검증하였다. 우선 목적에 맞는 표본 기사를 선정하여 빈도수를 기준으로 키워드를 선정하였고, 이에 워드 임베딩(Word Embedding) 벡터를 구축하였다. 구축된 벡터들을 활용하여 키워드 간의 코사인 유사도(Cosine Similarity) 검사를 진행하였으며, 이를 통해 군집을 형성하였다. 형성된 군집은 군집 내의 키워드 간에는 ‘AND’를, 군집 간에는 ‘OR’을 사용하였으며 시각화 자료 및 정석적인 평가를 통해 최적의 키워드 추출 및 검색 기법 생성에 대한 작업을 수행하였다.
2. 선행 연구 및 이론적 배경
2.1 선행 연구
자연어 처리 분야는 같은 모델이라 할지라도 언어에 따라 다른 성능을 보인다. 특히 한국어는 교착어라는 특성을 갖고 있어 자연어 처리에 비교적 한계가 많다(An and Kim, 2015). 따라서 한국어를 대상으로 한 워드 임베딩 및 유사도 검사 활용 연구를 이공계열, 사회과학계열, 인문계열에 대해 조사·분석하였다. 이공계열에서는 건축물 설계 품질 자동 검토의 고도화를 위한 기초 연구(Song and Lee, 2018), 한국 법령정보를 워드 임베딩에 적용하여 연관 정보 검색 방법 연구(Kim and Kim, 2017), 교량 점검보고서에서 손상 및 손상 인자를 자동으로 식별하는 방법 연구(Chung et al., 2018) 등이 수행되었다. 사회과학계열에서는 북한 관련 뉴스들에 대한 매체별 의제 설정 효과 측정 연구(Kim et al., 2020), 기업가 정신 관련 연구논문을 대상으로 한 동향 분석 연구(Yoo and Sung, 2021), 텍스트 마이닝을 활용한 소비자학 동향 분석 연구(Kim, 2020) 등이 있다. 인문계열에서는 노동신문의 이념적 어휘 연구를 통한 북한 사회문화 변화 양상 분석 연구(Cheong et al., 2020), 기술용어 분산 표현을 활용한 특허문헌 분류에 관한 연구(Choi and Choi, 2019), 온라인 뉴스 기사에서 추출된 키워드를 활용한 세부 주제별 토픽 추출 연구(Choi and Choi, 2018)가 진행되었다. 또한 워드 임베딩 벡터 구축 이후 코사인 유사도를 활용한 사례로는 게임 리뷰를 보다 명확하고 운영에 유용한 주제들로 자동 분류하는 시스템을 개발하는 연구(Yang et al., 2019) 등이 있다.
선행연구를 조사하고 분석한 결과, 워드 임베딩 및 코사인 유사도의 활용 방안은 대체적으로 토픽 모델링(Topic Modeling) 및 문헌 분류에 주로 사용되었다. 그러나 이를 기반으로 한 검색 기법 생성 연구는 미비하였다. 이에 따라 본 논문에서는 워드 임베딩 기법 및 코사인 유사도를 활용하여 최적의 검색 기법 생성 방안을 제안하고 검토하였다.
2.2 워드 임베딩 벡터
자연어 처리를 위해 기존에는 원-핫 인코딩(One-Hot Encoding)의 방식을 사용해왔다. 원-핫 인코딩이란 표현하고자 하는 단어의 인덱스(Index)에 1을 부여하고 다른 인덱스에는 0을 대입하는 것이다. 이로부터 얻어진 벡터를 원-핫 벡터(One-Hot Vector)라고 한다. 예를 들면 개, 고양이, 사자라는 3개의 단어가 있고 각각의 인덱스가 순차적으로 1, 2, 3이라고 할 때, 개에 대한 원-핫 벡터는 [1, 0, 0]이며 사자에 대한 원-핫 벡터는 [0, 0, 1]이 된다. 이러한 원-핫 벡터는 단어가 추가되는 개수에 따라 크기가 증가하며 해당하는 단어에 대한 인덱스를 제외하고는 모두 0의 값을 가져 저장 공간 측면에서 비효율적이다(Yoo and An, 2023). 또한 원-핫 인코딩으로 표현 시에는 의미적으로 유사한 값들을 분별해내지 못한다는 단점이 있다. 예를 들면 위에서 제시한 원-핫 벡터의 경우 사자와 유사성이 높은 단어에 대한 판단이 불가하다. 이러한 한계를 해결하기 위해 0, 1로만 표현했던 벡터를 실수화하였고 이를 밀집 벡터(Dense Vector)라고 한다. 예를 들면 10000개의 단어를 원-핫 벡터로 표현하면 [1 0 0 … 0]으로 표현되고 벡터의 차원은 10000이 된다. 이를 밀집 벡터로 표현하면 사용자가 지정한 차원으로 크기가 결정되고 각 인덱스에 실수값이 들어가게 된다. 예시로 개를 밀집 벡터로 표현하면 [0.2 0.5 0.1 0.6 –1.1 ...] 이 된다. 가령 차원을 128로 설정한다면 숫자의 개수는 128개가 된다. 이렇게 단어를 밀집 벡터 형식으로 표현하는 것을 워드 임베딩이라 하며 이로부터 얻어진 벡터를 워드 임베딩 벡터라 한다. 워드 임베딩 기법은 분산 표현(Distributed Representation)이라고도 하는데 이는 의미가 비슷한 단어 간의 벡터들이 비슷한 값을 가진다는 분포 가설(Distributional Hypothesis)(Harris, 1954)을 배경으로 하여 벡터 간 유사도 검사가 가능하다. 워드 임베딩 기법의 대표적인 모델로는 LSA, Word2Vec, FastText, Glove 등이 있다. Word2Vec의 대표적인 모델로는 CBOW(Continuous Bag of Words)와 Skip-gram이 있다. CBOW는 전체 문맥을 고려하여 중심 단어를 예측하는 방법이며 이와 반대로 Skip-gram은 중심 단어를 고려하여 전체 문맥을 예측하는 방법이다. 본 논문에서는 Word2Vec 모델 중 CBOW를 활용하였으며 구조는 Fig. 1과 같다.
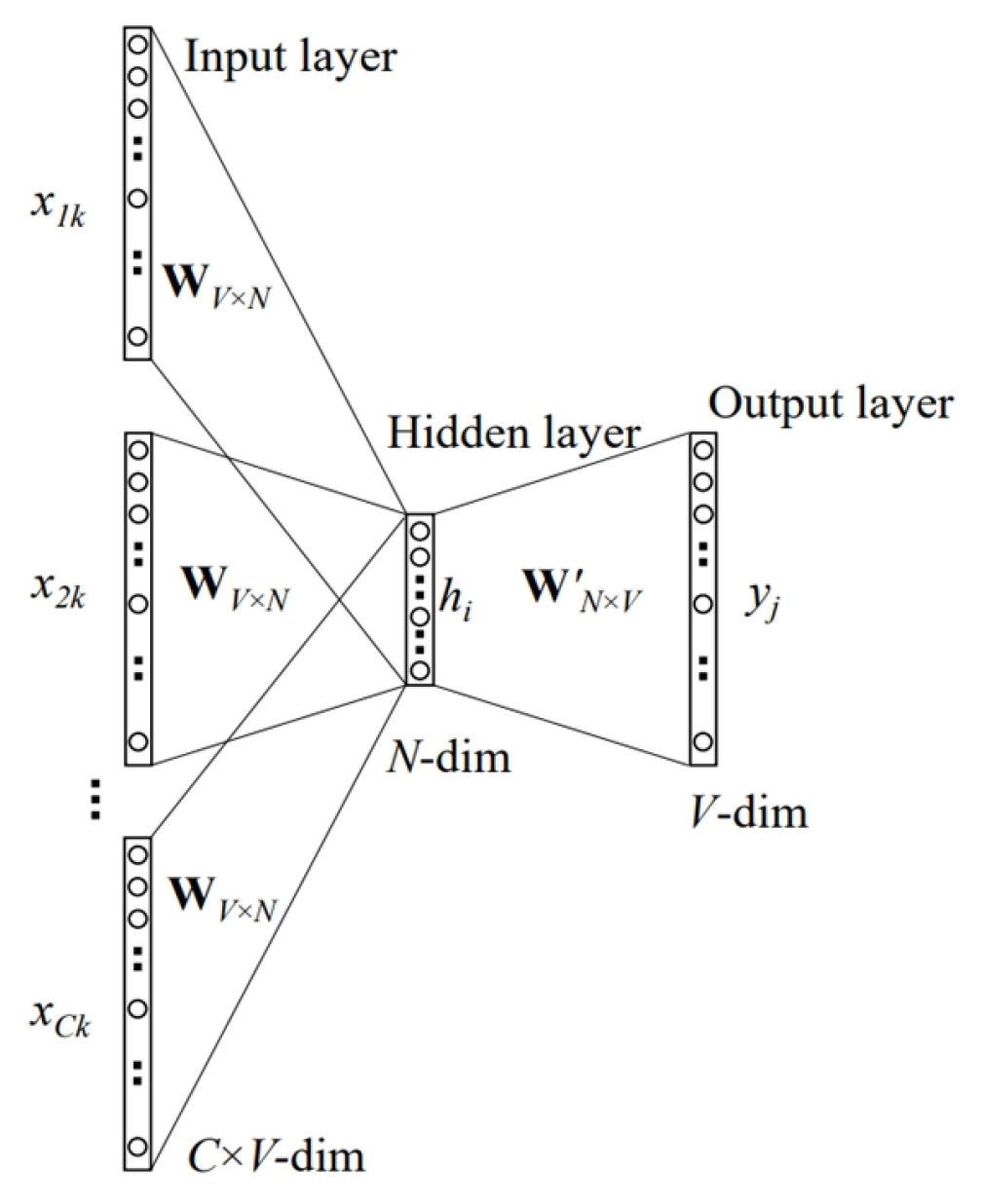
CBOW는 총 3개의 층으로 이루어져 있고 각각 Input layer, Hidden layer, Output layer가 있다. Input layer는 사용자가 정한 중심 단어의 주변 단어에 대한 원-핫 벡터가 입력으로 들어간다. 입력으로 들어간 벡터는 가중치 W와 곱해진다. 이때 입력 벡터가 i번째 인덱스에 대한 원-핫 벡터이므로 W의 i 번째 행이 결과로 나오게 된다. Input layer의 가중치를 통과한 벡터들은 Hidden layer에서 평균값을 구하게 된다. 구해진 평균 벡터는 가중치 행렬 W’와의 연산을 통해 V 차원을 가진 벡터로 변환되어 Output layer으로 보내진다. Output layer로 보내진 벡터는 Soft-max 함수를 적용하여 0과 1사이의 실수값으로 표현된다. 이를 기반으로 역전파를 통해 가중치가 재설정이 되고 반복 학습을 하며 최종적으로 워드 임베딩 벡터가 형성된다.
2.3 코사인 유사도
벡터의 유사도를 검사하는 방법에는 코사인 유사도, 유클리드 거리(Euclidean Distance), 자카드 유사도(Jaccard Similarity) 등이 있다. 본 논문에서는 코사인 유사도를 사용하였다. 코사인 유사도는 두 벡터 A, B 간의 각을 기준으로 유사도를 측정하는 방법으로 계산식은 식 (1)과 같다. 같은 방향일 경우는 1, 90°일 경우는 0, 반대 방향의 경우는 -1을 갖게 된다. 분모에는 각각의 벡터의 크기가 곱의 형태로 들어가고 분모는 두 벡터의 내적이 들어간다. 이로 인해 두 벡터의 사이각을 코사인 함수에 넣은 값이 유사도로 표현된다. 일반적으로 정보 검색 및 텍스트 마이닝 분야에서 활용되며 차원이 클수록 유사도를 명확히 구분할 수 있으며 벡터의 크기 값은 결과에 영향을 끼치지 않는다.
3. 키워드 추출 및 검색 기법 생성
검색 키워드 추출 및 기법 생성 과정은 Fig. 2와 같다. 빅카인즈의 기사를 분류하기 위한 최적의 검색 키워드 추출 및 기법 생성을 목적으로, ‘국내외 북한 건설 관련 동향 파악’을 예시로 검증하였다. 첫째로, 기사를 직접 추출하여 표본 기사를 선정하여 중요 키워드를 생성하였다. 키워드 생성은 빅카인즈의 키워드 추출 알고리즘인 토픽랭크 알고리즘을 사용하였다. 둘째로, 추출된 키워드에 대한 워드 임베딩 벡터를 생성하였다. 셋째로, 생성된 워드 임베딩 벡터를 활용하여 키워드 간의 유사도 검사를 실시하였다. 유사도 검사에서는 코사인 유사도를 활용하였다. 넷째로 빈도수 상위 10개에 대한 키워드를 기준으로 유사도가 0.5 이상인 키워드들을 포함시켜 10개의 군집을 생성하였다. 마지막으로, 생성된 군집들을 활용하여 빅카인즈의 검색 양식에 맞추어 최적의 검색 기법을 생성하였다.

3.1 표본 기사 선정 및 키워드 추출
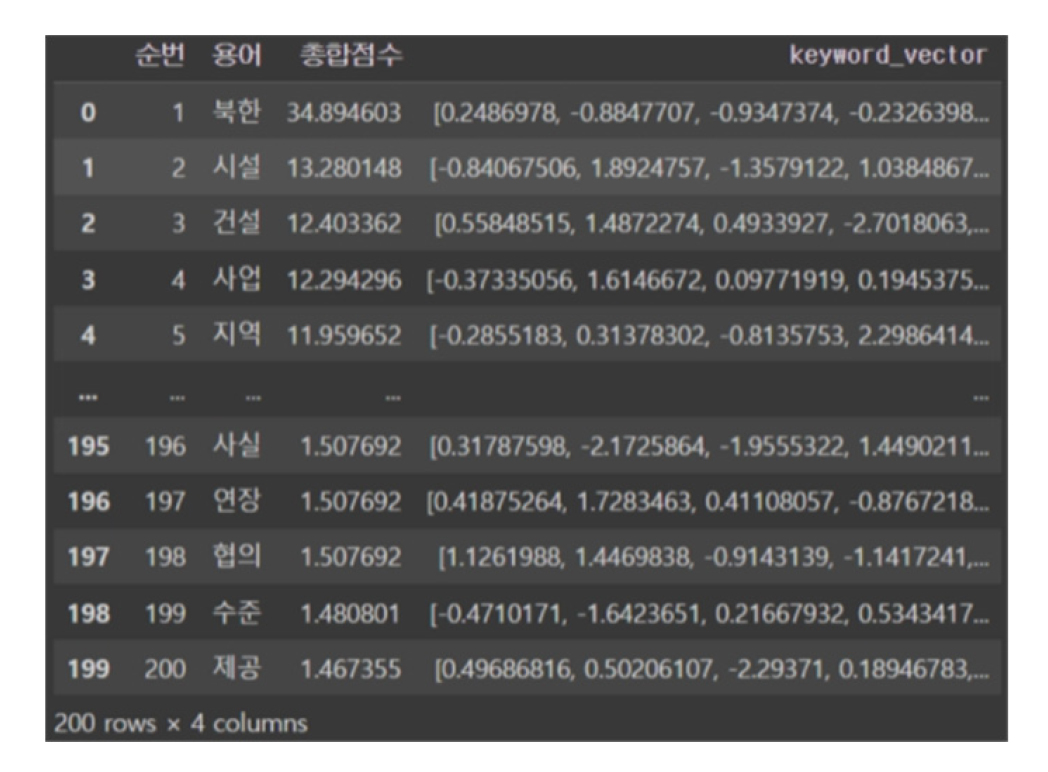
키워드 추출을 위한 표본 기사를 선정함에 있어 기간을 2022.09.01.~2022.11.30.으로 설정하고 기본 검색 키워드를 ‘북한’으로 지정하였다. 이후 ‘국내외 북한 건설 관련 동향 파악’에 부합하는 기사를 직접 추출하여 120개의 기사를 표본 기사로 선정하였다. 선정된 표본 기사에 빅카인즈의 토픽랭크 알고리즘을 적용하여 키워드 추출을 진행하였다. 추출된 키워드는 총 6787개이나 빈도수가 낮은 키워드는 성능 저하를 일으킬 수 있다고 판단하였다. 따라서 빈도수 기준 상위 200개의 키워드를 우선적으로 선정하였다. 상위 키워드 200개는 Table 1에서 확인할 수 있다.
Table 1.
List of top 200 keywords by frequency
3.2 워드 임베딩 벡터 구축
3.1에서 생성된 키워드를 기반으로 한국어 기반 사전학습(Pre-trained) 모델을 활용해 워드 임베딩 벡터를 구축하였으며, Fig. 3을 통해 관련 내용을 확인할 수 있다. 워드 임베딩 벡터 구축에 사용한 모델은 CBOW 모델로 vector size는 200, corpus size는 339M, Vocabulary size는 30185이다(Park, 2023). Fig. 4는 키워드 ‘북한’의 워드 임베딩 벡터 예시로 200개의 숫자로 표현되었다.

3.3 유사도 검사 및 군집 생성
키워드 간의 유사도를 검사하기 위해 코사인 유사도를 활용하였다. Fig. 5와 같이 Correlation matrix를 활용하여 빈도수 상위 10개의 키워드와 유사도가 0.5 이상인 키워드를 같은 군집으로 포함하였다. 결과적으로 Table 2와 같이 총 10개의 군집을 형성하였으며, 모든 키워드에 대해 군집을 형성하는 것은 기사 분류에 성능 저하를 일으킬 수 있으므로 제외하였다.
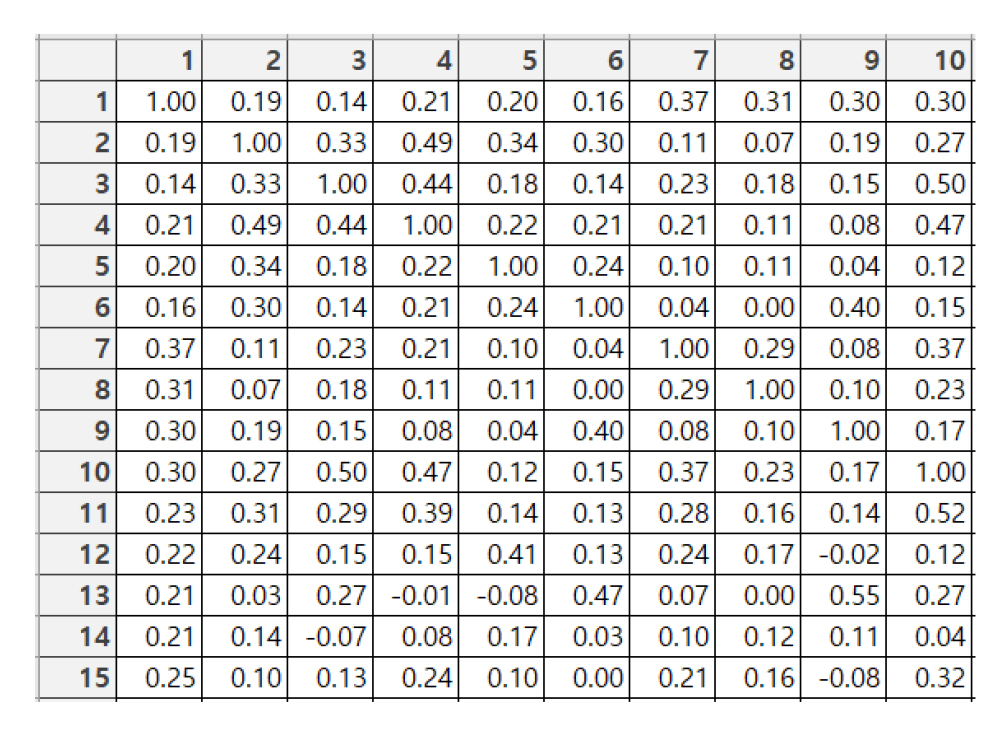
Table 2.
Top 10 Keywords Cluster For Frequency
3.4 검색 기법 추출
빈도수 상위 10개의 키워드에 대한 유사 키워드를 검토한 결과, 알맞게 배열되어 있음을 확인하였다. 이후 Table 3과 같이 빅카인즈 검색 양식을 적용하여 군집 내에는 ‘OR’, 군집 간에는 ‘AND’를 대입하였다. 이와 더불어 키워드의 개수와 분류 성능은 상위 순위의 군집부터 시작하여 아래 순위의 군집을 포함하는 형식으로 진행하였다. ‘국내외 북한 건설 관련 동향 파악’에 부합하는 기사 추출을 목적으로 한 군집 적용 1차 방법으로 군집 1, (2, 3)과 군집 1, 2, 3을 비교하였다. 여기서 괄호는 해당 군집을 하나의 군집으로 가정함을 의미하며 이로 인해 군집 (2, 3)은 AND가 아닌 OR로 연결이 된다. 관련 내용은 Table 2, 3을 통해 확인할 수 있다. 비교 결과 군집 1, 2, 3의 기사가 군집 1, (2, 3)에 포함되며, 중복 기사를 삭제해 본 결과 6124개의 기사가 추출되었다. 추출 기사 내용 중 건설과 무관한 정치적 내용이 대부분을 이루어 군집 1, 2, 3을 선정하였다.
군집 적용 2차 방법으로 군집 1, 2, 3과 군집 1, 2, 3, 4를 비교하였다. 비교 결과 군집 1, 2, 3, 4의 기사가 군집 1, 2, 3에 포함되었다. 포함된 기사를 삭제해 본 결과 379개의 기사가 추출되었다. 추출 기사 내용 중 DMZ, 북한 관련 관광지에 대한 내용이 다수 포함되었다. 불필요한 기사도 존재하였으나 건설과 관련한 유의미한 기사가 다수를 차지하여 군집 1, 2, 3을 선정하였다. 군집 적용 3차 방법으로 군집 1, 2, 3과 군집 1, 2, (3, 4)를 비교하였다. 비교 결과 군집 1, 2, 3의 기사가 군집 1, 2, (3, 4)에 포함되었다. 포함된 기사를 삭제해 본 결과 588개의 기사가 추출되었다. 추출 기사 내용 중 미사일 관련 정치적인 요소가 대부분이며, 필요 부분은 군집 1, 2, 3에 포함되는 내용임을 확인하였다. 군집 적용 4차 방법으로 군집 1에 키워드 ‘한반도’를 제외한 경우와 포함한 경우를 비교하였다. 비교 결과 ‘한반도’를 제외한 경우가 ‘한반도’를 포함한 경우에 모두 포함되었다. 포함된 기사를 삭제해 본 결과 453개의 기사가 추출되었다. 기사 내용 중 태풍 피해는 한반도 중심으로 서술되어 태풍 기사가 다수를 차지하였으며, 외교 관련 기사에서 대한민국을 지칭할 때 한반도를 사용하여 건설과 관련이 없는 내용이 다수 포함되었다. 따라서 한반도 키워드를 제외한 군집 1, 2, 3을 최종 군집으로 선정하였다.
Table 3.
Search Technique for Clusters Using Bigkinds search form
3.5 최적의 키워드 및 군집 선정 결과
‘국내외 북한 건설 관련 동향 파악’에 부합하는 최적의 군집은 1, 2, 3(‘한반도’ 제외)이 선정되었다. 이에 따른 실제 검색 기법은 (북한) AND (시설 OR 물류 OR 인프라 OR 건물) AND (건설 OR 설치 OR 조성 OR 공사 OR 구축)으로 형성되었다. 최적의 검색 기법을 빅카인즈에 입력해 본 결과 2022.09.01.~2022.11.30. 기간의 북한 관련 기사 28272개 중 771개의 기사로 압축되었다.
분류된 기사를 분석한 결과 771개 중 271개의 기사가 불필요한 기사로 분류되었으며 주요 특징은 다음과 같다. ① 하나의 기사 내에 다양한 주제가 있는 브리핑의 형식이다. 이러한 형식은 해당 날짜의 주요 이슈를 전반적으로 다루게 된다. 주요 키워드가 하나의 기사 내에 있다고 할지라도 다른 주제에 분포하고 있어 유의미한 기사로 보기에 한계가 있다. 이 경우 기사의 제목이 “브리핑”으로 시작하므로 일괄적인 삭제가 가능하다. ② 본인의 의견을 서술하는 ‘칼럼’의 형식이다. 이러한 경우 북한이라는 주제를 건설 이외에도 다양하게 접근하게 된다. 특히 건설과 관련한 글이라 할지라도 사실이 아닌 의견을 서술하였으므로 동향 파악에 적합한 형식이라고 하기에는 신뢰성이 부족하다. 이 경우 기사 제목이 ‘칼럼’으로 시작하므로 일괄적인 삭제가 가능하다. ③ 기사의 끝 단락에 북한의 비핵화에 대한 언급이 있다. 특히 정치 분야의 기사에서 북한과 무관한 주제이지만 마지막 단락에 북한의 비핵화를 언급하며 ‘북한’이라는 주요 키워드를 충족하게 된다. 이 경우 일괄적인 삭제는 불가하나 제목을 통해 불필요한 기사임을 확인할 수 있다.
4. 결론 및 고찰
본 논문에서는 다양한 목적에 맞춰 자료 조사·분류가 가능한 검색 기법을 제안하고 검증하였다. 우선 목적에 맞는 기사 일부를 선택하여 표본 기사를 생성하였으며, 토픽랭크 알고리즘을 통해 표본 기사의 키워드를 추출하였고 빈도수를 기준으로 상위 200개의 키워드를 선정하였다. 이를 기반으로 워드 임베딩 벡터를 구축하였고 코사인 유사도를 활용해 키워드 간 유사도를 검사하였다. 빈도수 상위 10개의 키워드를 기준으로 유사도가 0.5 이상인 키워드를 선별해 총 10개의 군집을 생성하였다. 생성된 군집에 빅카인즈의 검색 양식을 사용하여 최적의 검색 기법을 도출하였다. 제안한 방법은 ‘국내외 북한 건설 관련 동향 파악’을 중심으로 검증하였으며, 다음과 같은 결론을 도출하였다.
(1) 키워드 추출 시 토픽랭크 알고리즘과 빈도수를 기준으로 사용하였다. 그러나 이로 인해 사용자의 목적에 부합하지 않는 키워드가 추출될 가능성이 존재한다. 이에 따라 필수 포함 키워드를 사전에 지정하거나 중요 키워드에 가중치를 높인다면 키워드 순위에 신뢰성이 확보될 것이다.
(2) 워드 임베딩은 한국어 기반 사전학습 모델을 활용하였다. 기사로부터 추출된 키워드들에 워드 임베딩 벡터를 구축하여 유사도 검사를 실시한 결과, 실제로 비슷한 의미를 갖는 값들이 군집으로 형성되었다. 그러나 워드 임베딩 벡터는 트레이닝 셋에 따라 다르게 형성될 수 있다. 따라서 본 논문에서 제시한 방법론을 통해 얻은 기사를 기반으로 전이 학습(Transfer learning)을 진행한다면 세부 목적에 맞는 워드 임베딩 벡터가 구축될 것이다.
(3) 군집화 생성과정에서 코사인 유사도 및 유사도 0.5 이상을 군집화의 기준으로 하였다. 코사인 유사도는 크기 값이 결과에 영향을 끼치지 않는다. 이로 인해 필요한 정보가 누락될 가능성이 있다. 또한 0.5라는 기준은 기사 분류 결과에 적합한 기준으로 보였으나 최적의 기준임을 보장하기에 한계가 있다. 따라서 다양한 유사도 검사 및 군집화 기법들을 추가 검토한다면 보다 좋은 성능을 낼 수 있는 군집화가 가능할 것이다.
(4) 기사 분류의 세부 목적은 ‘국내외 북한 건설 관련 동향 파악’이지만, 북한과의 교류가 직접적이지 않은 현 상태에서 충분한 표본 기사를 확보하는 것에는 한계가 있다. 따라서 본 논문에서 제안한 방법을 활용하여 1차적으로 기사를 추출한 이후 불필요한 기사를 삭제하고 이를 표본 기사로 활용하여 제안한 방법을 반복적으로 수행한다면 비교적 좋은 분류 성능을 내는 검색 기법을 생성할 수 있을 것이다. 특정 전공뿐만 아니라 모든 분야에서 방대하고, 다양한 자료들(논문, 기준 등)을 조사하고 분류하기 위한 검색 방법으로 활용 가능할 것으로 판단된다.
향후 다양한 주제에 대한 검증, 다른 분석 기법과의 비교 연구가 필요하며, 표본 기사 추출, 유사도 검사 기준과 같이 사용자가 직접 수행하거나 선택해야 하는 부분에 대한 자동화 연구가 수행된다면 사용자가 세부 목적을 입력하는 것만으로도 기사 분류가 가능해질 것으로 기대된다.
