

1. 서 론
국내 설계에서는 실내 및 현장 시험 등을 통해 심도별 비배수전단강도에 대한 데이터를 취득한 후 대표 단일 값을 주로 설계에 사용한다. 지반의 심도가 낮은 경우 심도와 관계없이 단일 값을 적용하고, 심도가 깊은 경우 깊이에 따른 선형적으로 변하는 값을 사용하고 있다. 단일 값은 지반이 가지고 있는 특성을 충분히 나타내지 못하므로 설계자는 안전율 개념을 추가로 적용하여 설계하고 있다. 설계 및 안정성 평가에서 과소 평가된 단일 값을 적용하면 안정성을 충분히 확보하지 못하여 구조물의 붕괴나 침하로 이어질 수 있고, 반대로 과대 평가된 값을 설계에 적용하면 불필요한 비용으로 경제적 손실을 초래할 수 있다. 특히, 다층지반 혹은 불균질 지반이 광범위하게 분포되어 있는 국내 연안 지반의 경우 심도에 따른 강도의 비례관계가 성립되지 않아 그 영향은 더욱 크게 나타날 가능성이 있다(Park et al., 2006).
이와 같은 문제점을 줄이기 위하여 유럽에서는 단일 값 대신 심도별로 산정된 상한값(Upper estimate, UE)과 하한값(Lower estimate, LE)을 설계에 적용하고 있으며 특히, 해양에 설치하는 석션앵커를 설계할 때도 이 방법이 활용된다. DNV-RP-C207(Det Norske Veritas, 2010), DNV- RP-E303(Det Norske Veritas, 2021)에 따르면 하한값(Lower estimate)은 일반적으로 낮은 강도가 불리한 궁극적 상태에 대한 설계를 위해 사용하고, 상한값(Upper estimate)은 일반적으로 큰 강도가 불리한 경우를 고려할 때 주로 사용한다. 한 예로, 요즘 부각이 되는 부유식 해상풍력의 석션앵커를 보면, 하한값(Lower estimate)은 석션앵커의 지지력(pullout capacity)를 산정하는 데 사용되고, 상한값(Upper estimate)은 앵커 설치 시 관입 저항을 평가하는 데 사용된다(Allan et al., 2014).
DNV-RP-C207(Det Norske Veritas, 2010)에서는 토양 데이터의 통계적 분석 방법과 설계 시 특성 값으로 상한값과 하한값을 적용한 예시에 대해 제시하고 있으나, 특정 상황에서 적용해야 하는 지반 데이터의 분석 방법 및 상한값(Upper estimate)과 하한값(Lower estimate)의 산정 방법 등에 대한 구체적인 지침(Manual)은 제시하지 않고 있다. 통계적 방법의 원칙, 권장 사항 등을 제시하고 지반 데이터의 불확실성(공간 평균화 및 공간 추정 등)에 대해 설명하며 매개변수에 대한 추정 공식을 제공하고 있을 뿐이다.
본 연구에서는 DNV-RP-C207에 제시된 내용을 참고하여 국내 연안 지반에서 획득한 CPT 데이터를 기반으로 산정된 비배수전단강도의 상한값(Upper estimate)과 하한값(Lower estimate)을 파이썬을 이용한 통계 분석을 통해 도출하고 이를 제시하였다.
2. 연구 데이터
국내 광양항 지역에서 획득한 CPT 데이터를 기반으로 산정된 심도별 비배수전단강도를 연구 대상으로 하였다. CPT 결과는 총 289개의 자료로 약 G.L (-)0m - (-)7.4m에 대해 심도에 따른 콘저항, 슬리브 마찰 저항 등의 측정값이 열로 구성되어 있으며, 값은 일반적으로 정규압밀점토와 과압밀점토의 경우 10~20을 실용적으로 많이 이용하고 있다. 이 연구에서는 삼축압축시험 결과를 바탕으로 비배수전단강도 산정을 위해 =16.3을 적용하였으며, 현장베인시험결과값을 이용하여 값을 산정하였다.
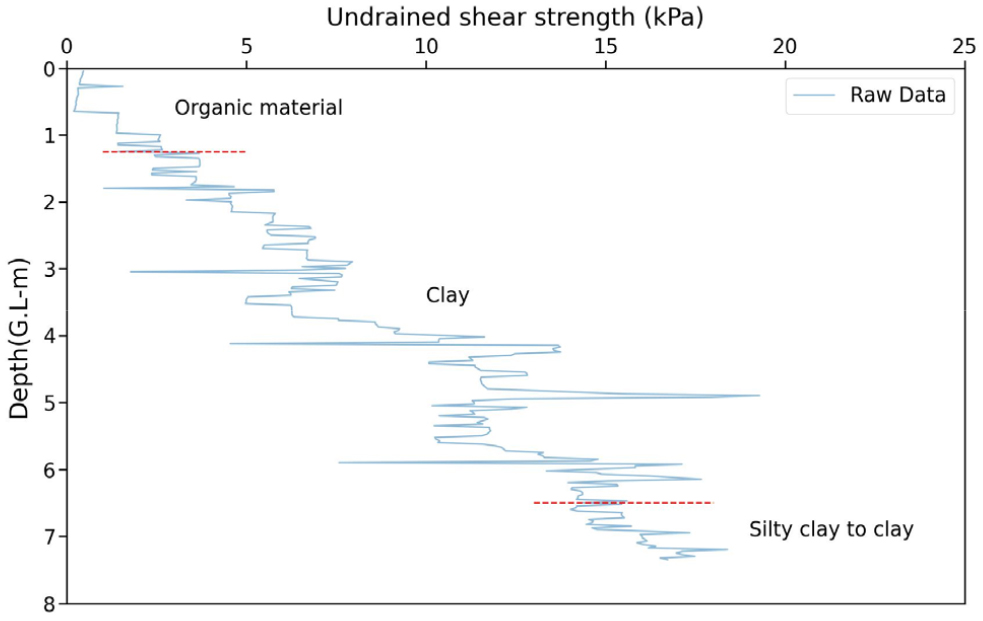
심도에 따른 비배수전단강도를 분석하기 전 데이터의 분포를 확인하기 위해 시각화하였으며 직관적인 데이터 해석과 토층 경계와 같은 심도별 속성 변화를 효과적으로 파악하기 위해 세로축에 심도(Depth), 가로축에 비배수전단강도(Undrained shear strength)를 나타내었다(Fig. 1). 해당 데이터의 비배수전단강도는 0.2kPa에서 19.3kPa의 범위를 가지며 G.L (-)0m - (-)1.25m는 유기물, G.L (-)1.25m - (-)6.325m는 점토, G.L (-)6.325m - (-)7.35m는 실트질 점토로 구성되어 있는 다층지반으로, 서론에서 언급한 바와 같이 심도에 따른 비례관계가 성립하지 않는 특징을 가지고 있다.
3. 데이터 분석
상한값과 하한값의 산정은 국내 연안 지반의 특성과 데이터의 불확실성을 효과적으로 다루기 위한 접근법이며, 사용되는 목적이 상이하므로 각 목적에 적합한 방법을 적용하였다. 상한 값은 큰 강도가 불리한 경우를 고려할 때 사용되지만, 과도한 값을 설계에 적용할 경우 과대설계로 인한 경제적 손실을 초래할 위험이 있다. 특히, 국내 연안 지반은 다층적이고 불균질한 특성을 가지고 있어 심도와 비배수전단강도가 비례하지 않으며, 토층 경계 등에서 급격하게 변동하는 특성이 있다. 이러한 특성으로 인해 전체 데이터를 단일 분석할 경우 통계적 특성이 왜곡되거나 노이즈로 인해 정확도가 저하되는 문제가 발생할 수 있다. 이를 해결하기 위해 심도별 비배수전단강도 데이터를 특성이 유사한 몇 개의 구간으로 분류하고 각 구간의 변동계수를 산정하였다. 그 후 구간별 특성을 반영하여 평균 혹은 선형회귀를 적용하는 방식으로 상한값을 산정하였다.
반면, 하한값은 설계에서 낮은 강도가 불리한 상태를 대비하기 위해 사용되므로, 데이터의 낮은 경계에 초점을 맞추어야 한다. 이를 위해 특정 분위수에 기반한 경향을 추정하는 통계 기법인 분위수 회귀(Quantile Regression)를 적용하였다. 분위수 회귀는 데이터의 하위 경계에 집중하여 불리한 조건을 반영할 수 있도록 설계되었으며, 이를 통해 하한값을 산정하여 설계 안전성을 확보하고자 하였다.
3.1 상한 결정(Upper estimate)
3.1.1 데이터 분류(Data classification)
파이썬은 1991년 귀도 반 로섬(Guido Van Rossum)이라는 프로그래머에 의해 개발된 고급 프로그래밍 언어로, 인터프리터 방식을 채택하고 동적 자료형을 특징으로 하며, 객체 지향, 함수형, 절차적 프로그래밍을 지원한다(Lee, 2014). 파이썬은 다양한 분야의 문제를 해결하기 위한 라이브러리를 제공하며, 시계열 데이터의 변화점을 탐지하기 위한 CPD(Change Point Detection) 알고리즘을 구현한 다양한 라이브러리를 사용할 수 있다(Kim and Baek, 2022). CPD 알고리즘 중 하나인 CUSUM 방법은 누적합 변화를 기반으로 임계값을 초과하는 시점을 변화점으로 간주하여 분석한다(Lee et al., 2020). 또한, 스무딩 기법(Smoothing techniques)은 데이터의 경향성을 파악하고 노이즈를 제거하는 데 사용되며, CPD 분석 전에 데이터 전처리 과정으로 활용될 수 있다(Park and Sim, 2023).
이 외에도 CPD 알고리즘에는 다양한 방법이 존재하며, 대표적인 방식으로 PELT, KernelCPD(Linear, RBF)가 있다(Fig. 2). PELT(Pruned Exact Linear Time) 알고리즘은 통계적 모델을 기반으로 변화점을 탐지하며, 불필요한 계산을 가지치기(Pruning)하여 연산속도를 효율적으로 개선하는 특징이 있다(Killick et al., 2012). 이 방식은 대량의 데이터에서도 빠르게 변화점을 찾을 수 있는 장점이 있지만, 독립성 및 정규성 등의 가정이 만족되지 않으면 탐지 정확도가 저하될 수 있다. 반면, KernelCPD는 데이터 간의 유사성을 측정하는 커널 함수(Kernel function)를 활용하여 데이터 분포나 경향성이 변하는 지점을 탐지하는 방법으로 비선형적 변화가 있는 데이터를 분석하는 데 유용하며, 다양한 커널을 적용할 수 있는 유연성을 가진다. 본 연구에서는 연안 지반의 비배수전단강도가 심도에 따라 선형적인 변화를 보이지 않고 다층적 특성을 가지므로, 비선형적 변화를 효과적으로 반영할 수 있는 KernelCPD를 적용하였다.
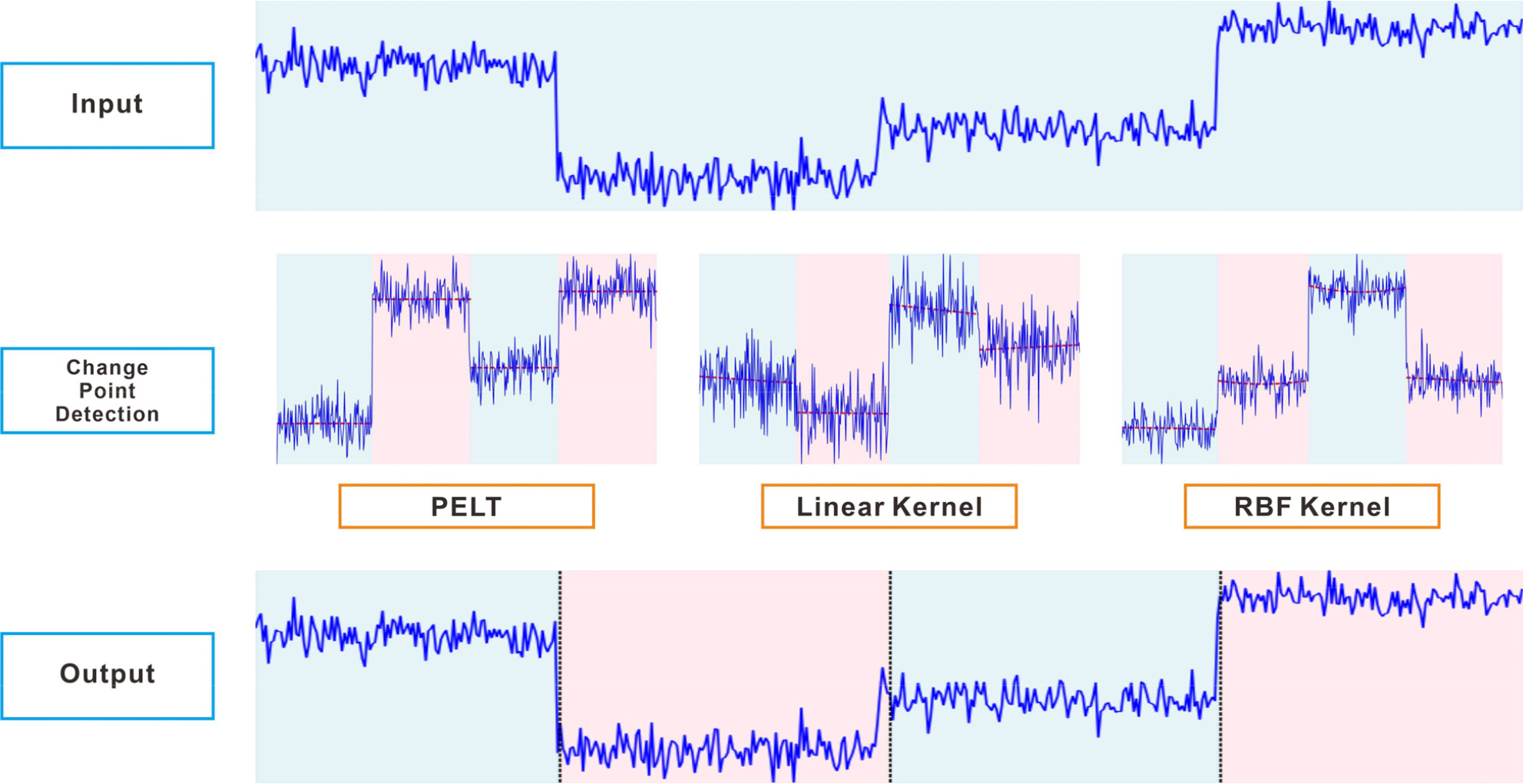
커널 함수는 머신러닝과 통계학에서 데이터 간 유사도를 계산하거나 고차원 공간으로 매핑하여 복잡한 패턴을 학습하는 데 사용되는 함수로, 대표적으로 선형 커널(Linear Kernel)과 RBF(Radial Basis Function) 커널이 있다(Bouchikhi et al., 2019; Fan et al., 2015). 선형 커널은 가장 간단한 형태의 커널로 데이터가 선형적으로 분리 가능한 경우에 적합하며, 계산이 간단하고 빠른 장점이 있지만 복잡한 비선형 데이터에서는 성능이 제한적이다. RBF 커널은 가우시안 함수에 기반하여 데이터 간 유사성을 측정하므로 복잡한 패턴을 학습할 수 있으며, 비선형적으로 분포한 데이터에 효과적이다.
KernelCPD 알고리즘은 데이터의 특성에 맞게 다양한 커널 함수를 선택할 수 있어 선형적, 비선형적 데이터 모두에 대해 효과적으로 변화점을 탐지할 수 있다. 또한, 데이터 변화점의 개수를 사용자가 직접 지정하거나 자동으로 탐지할 수 있어 목적에 따라 유연하게 활용할 수 있다. 파이썬의 강력한 라이브러리와 간단한 코드 작성 방식을 통해 분석의 자동화와 재현성을 높일 수 있으므로, 설계 과정에서 반복적으로 활용하기에 적합하다.
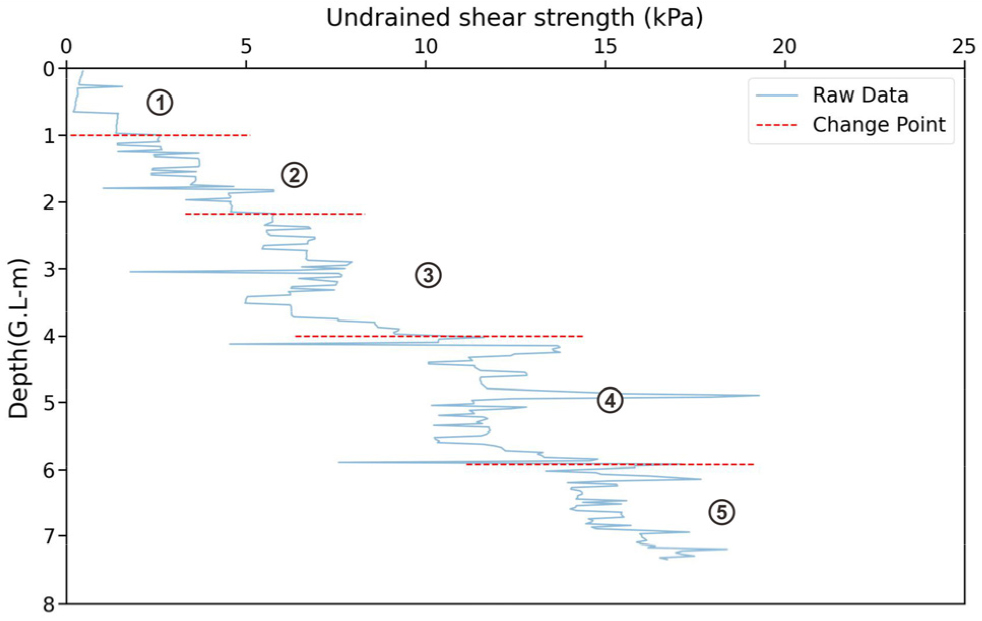
Fig. 3은 심도에 따른 비배수전단강도 데이터에 Kernel CPD 알고리즘을 적용하여 취득한 결과이며 빨간색 점선은 데이터 변화점으로 구간의 경계에 해당하는 심도(1m, 2.175m, 3.9m, 5.925m)를 나타낸다. 연구에 사용한 데이터는 급격한 전단강도의 변화를 가지는 특성이 있으므로 이를 고려하여 RBF 커널을 적용하였으며 예측하고자 하는 변화점의 개수는 4개로 가정하였다. 전체 데이터에 대해 4개의 변화점을 선정한 결과 처음과 마지막 구간을 포함하여 5개의 영역으로 구분되었다(Fig. 3). 전체 데이터는 심도가 증가함에 따라 비배수전단강도가 점진적으로 증가하는 경향을 보이지만, 구간별 패턴이 다소 차이 나는 것으로 나타난다. Fig. 3의 ①은 낮은 전단강도가 완만하게 증가하는 경향을 보이며 Fig. 1에서 Organic material의 특성을 가지는 것으로 판단되고 ②는 전단강도가 다소 급격히 증가하는 구간으로 Fig. 1에서 Clay로 토층이 변화하는 구간에 해당하여 상부와 다른 특징을 보이며 압밀에 의한 영향이 반영된 것으로 보인다. ③은 변화율이 비교적 불규칙한 패턴을 보이며 데이터의 분산이 높게 나타나 다양한 입도 분포의 토층으로 불규칙한 퇴적 환경일 가능성이 있는 것으로 판단되며 ④는 ③에 비해 강도는 증가하였으나 마찬가지로 불규칙한 패턴을 보이는 구간으로 나타난다. ⑤는 강도가 가장 높은 구간으로 다시 심도에 따른 강도의 증가가 안정적으로 나타나며 변동폭이 적어지고 압밀이 대부분 완료된 토층으로 판단된다. 이와 같이 KernelCPD 알고리즘의 적용은 심도별로 토층과 압밀 상태 등에 의한 통계적 특성이 유사한 구간을 적절히 구분할 수 있다.
3.1.2 변동계수(Coefficient of variation)
변동계수(Coefficient of variation, CV)는 표준편차를 평균으로 나눈 값으로, 평균이 커질 때 표준편차가 과대평가되는 문제를 해결하기 위해 사용되는 통계 지표이다. 이는 데이터의 상대적인 변동성을 측정하며, 단위(Unit)나 스케일(Scale)이 다른 데이터 간에도 변동성을 비교할 수 있는 장점이 있다.
KernelCPD 알고리즘으로 데이터의 변화점을 탐지하고, 탐지된 변화점을 경계로 영역을 구분하여 각 구간별 통계적 특성을 분석하였다. 변동계수가 낮을수록 데이터의 변동성이 적으며 값들이 평균에 가까운 분포를 보이고, 반대로 변동계수가 높을수록 데이터가 더 많이 분산되어 있음을 나타낸다.
Kim(2019)은 우리나라의 경우 소지역 통계는 CV 25%를 기준으로 사용하고 있다고 언급하였으며 Rheem and Rheem(2012)은 보통 30% 보다 크면 데이터의 변동성이 크다고 인정됨을 서술하였다. 본 연구에서는 변동계수를 활용한 선행연구에서 제시한 기준을 참고하고 데이터의 특성과 분석 목표에 부합하도록 30%를 기준으로 하여 분석하였다. 연구 데이터를 구간별로 분류하고 변동계수를 계산한 결과 ①에서 ⑤까지 순서대로 0.75, 0.32, 0.19, 0.16, 0.07에 해당하며 ①, ②는 기준보다 큰 변동계수를 가지고 ③, ④, ⑤는 기준보다 작은 변동계수를 가지는 것으로 나타났다(Fig. 4).
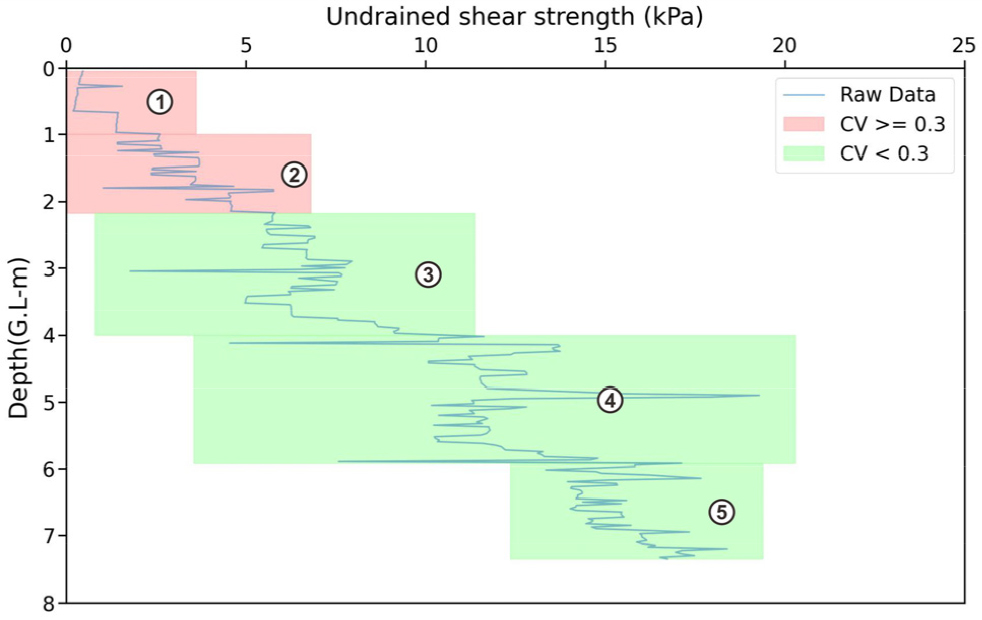
특히 연안 지역의 비배수전단강도는 심도별로 급격히 변화하는 특성을 가지므로, 변동계수를 적용하여 변화점 탐지 결과의 신뢰성을 평가하고, 구간별 특성을 분석함으로써 적합한 산정 방식을 채택할 수 있다.
3.1.3 평균 및 선형회귀
DNV-RP-C207(Det Norske Veritas, 2010)은 토양 변수를 독립 변수와 종속 변수로 구분하고, 평균값 또는 선형회귀(Linear Regression)를 통해 매개변수를 추정하는 방법을 제시한다. 본 연구에서는 전체 데이터를 기반으로 변화점을 탐지하고, 이를 바탕으로 구간을 분류하여 각 구간별 변동계수를 계산하고 상한값 산정에 반영하였다.
변동계수가 작은 경우, 데이터가 평균값을 중심으로 균일하게 분포되어 있음을 의미하며, 이는 데이터가 안정적이고 일정한 특성을 가짐을 나타낸다. 따라서 이와 같은 구간은 독립변수의 특성을 가지며, 평균값을 상한값으로 적용하였다. 반면 변동계수가 큰 경우, 데이터의 변화폭이 크고 심도에 따른 변화량이 크다는 것을 의미한다. 이러한 구간에서는 데이터의 불균질성과 경향성을 반영하기 위해 선형회귀를 통해 상한값을 산정하였다.
Fig. 5는 변화점을 기반으로 구간을 나누고, 각 구간별 변동계수를 계산하여 이를 반영한 상한값 산정 결과를 나타낸다. 심도 2.175m 이내의 구간에서는 변동계수가 0.3 이상으로 나타나 불균질한 데이터 특성을 보였으며, 이 구간에서는 선형회귀를 통해 상한값을 산정하였다. 이는 데이터의 경향성을 잘 반영하고, 과대 설계의 위험을 줄이는 데 기여할 수 있음을 보여준다. 반면 심도 2.175m 이후 구간에서는 변동계수가 0.3 미만으로 나타나 데이터가 상대적으로 안정적인 분포를 보였고, 평균값을 상한값으로 적용하였다. 이 결과는 각 구간의 상한값이 변동성을 효과적으로 반영하고 있으며, 심도별 데이터의 경향성과 물리적 특성을 잘 설명하는 것으로 판단된다.
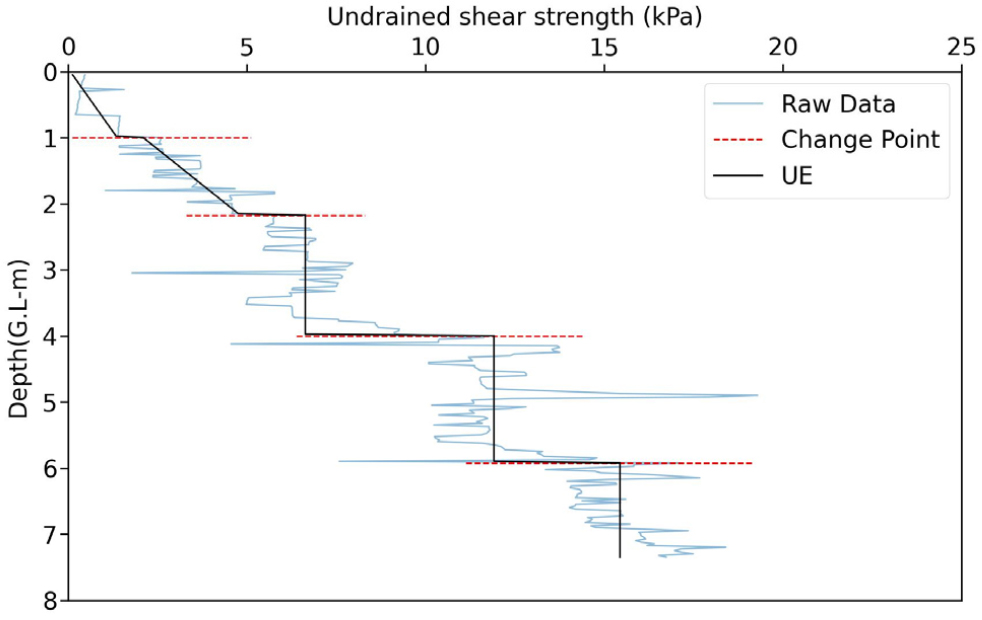
3.2 하한 결정(Lower estimate)
하한 값은 설계에서 낮은 강도가 불리한 조건을 고려할 때 사용되므로, 안정성을 확보하기 위해 데이터의 낮은 경계를 반영할 필요가 있다. 이를 위해 본 연구에서는 분위수 회귀(Quantile Regression)를 적용하여 특정 분위수에 기반한 경향을 추정하였다. 일반적인 선형회귀는 데이터의 평균을 설명하는 데 초점을 맞추는 반면, 분위수 회귀는 특정 분위수를 분석하는 데 사용되며, 극단값(하위 데이터)을 반영하여 하한값을 산정하는 데 적합한 통계 기법이다.
이 방법은 비배수전단강도가 선형적으로 변화하지 않는 경우에도 유연하게 적용할 수 있으며, 낮은 강도를 정확히 반영한다. 특정 분위수는 설계자가 목적에 따라 직접 설정할 수 있으며, 본 연구에서는 안정성과 경제성의 균형을 맞추기 위해 하위 20% 데이터를 기반으로 하한값을 산정하였다.
Fig. 6는 분위수 회귀를 적용하여 비배수전단강도의 하한값을 산정한 결과로, 하위 20% 데이터를 기반으로 산정된 하한값이 심도별 경향성을 선형적으로 반영하고 있음을 보여준다. 또한, 분위수 회귀를 통한 하한값 산정이 낮은 강도 데이터를 충분히 반영하고, 과대 설계를 방지하여 실용적이고 경제적인 설계를 가능하게 할 것으로 판단된다.
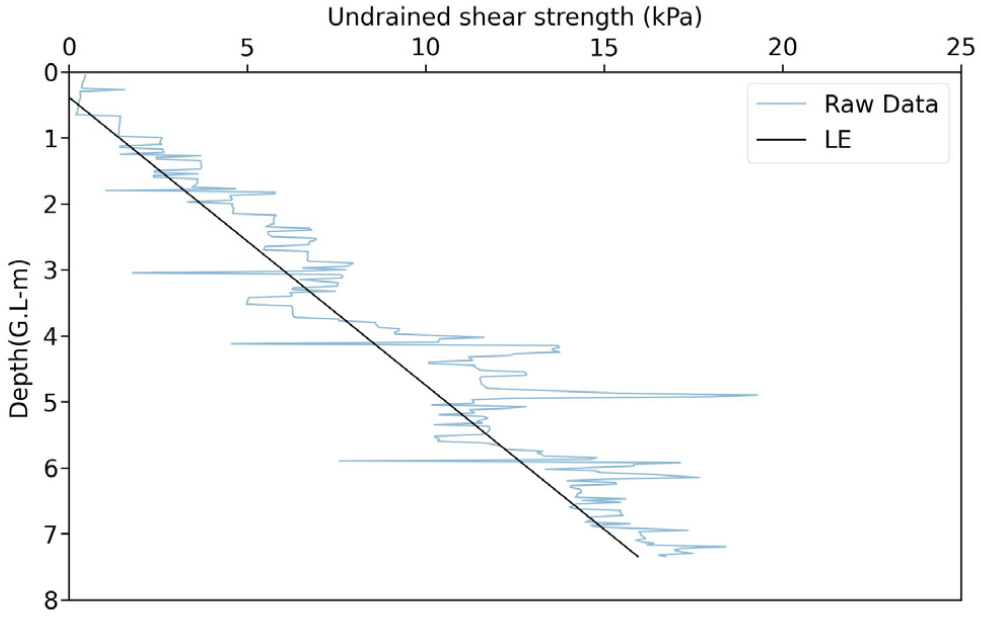
설계자는 목적에 따라 안정성을 강조하려면 하위 10% 데이터를, 경제성을 중점적으로 고려하려면 하위 30% 데이터를 기반으로 분위수 회귀를 적용할 수 있다. 이를 통해 분위수 회귀를 활용한 하한값 산정은 데이터의 특성과 설계 목적을 효과적으로 반영하며, 극단적인 최소값을 기반으로 한 과대 설계의 위험을 줄이는 동시에 데이터의 불확실성을 고려하여 신뢰할 수 있는 설계를 가능하게 한다.
4. 결 론
본 연구에서는 DNV-RP-C207에서 제시하는 통계적 방법을 기반으로 국내 연안 지반의 비배수전단강도 데이터를 분석하여 상한값과 하한값을 산정하였다. 상한값은 KernelCPD 알고리즘으로 데이터의 변화점을 탐지하고 구간별 변동계수를 기준으로 평균값과 선형회귀를 활용하였다. 데이터는 5개의 구간으로 분류하였으며 선행연구를 참고하여 변동계수의 기준을 0.3으로 설정하였다. 그 결과 약 2m 이하의 심도에 해당하는 2개의 구간은 기준보다 큰 변동계수로 선형회귀를 적용하였고 약 2m 이상의 심도에 해당하는 3개의 구간은 기준보다 작은 변동계수로 평균값을 적용하였다. 하한값은 분위수 회귀(하위 20% 데이터)를 적용하여 심도가 깊어질수록 점진적으로 증가하며 데이터의 낮은 경계를 효과적으로 반영하였다. 상한값 산정에 있어 변동계수를 활용한 평균 및 선형회귀의 적용은 데이터의 불확실성을 효과적으로 줄이며 과대설계의 위험을 방지할 수 있고 하한값 산정에서 분위수 회귀를 적용함으로써 극단값을 반영한 설계가 가능하다. 이러한 결과는 데이터의 특성을 반영하면서 설계 안정성을 확보하기 위한 적합한 설계 변수를 제공하며 국내 연안 지반의 특성을 고려한 설계 안정성을 확보하는 데 크게 기여할 수 있다.
본 연구는 광양항 지역의 연안 지반 데이터를 대상으로 하였으며, 데이터의 한정성으로 인해 다양한 지반 조건에 대한 적용 가능성은 추가적인 연구가 필요하다. 또한, 상한값 및 하한값 산정에서 변동계수 기준값과 분위수 설정이 설계자에 의해 선택된 만큼, 보다 체계적인 기준 설정을 위한 연구가 요구된다. 향후 연구에서는 다양한 지역의 지반 데이터를 활용하여 상한값 및 하한값 산정 방법의 적용 가능성을 검토하고, 비선형적인 데이터 분포를 반영할 수 있는 고도화된 기법의 적용을 검토할 필요가 있다. 또한, 설계 기준값의 최적화를 위한 체계적인 분석과 함께, 실제 설계 사례를 통해 본 연구의 방법론을 검증하는 과정이 필요할 것이다.
