

1. 서 론
2. 연구 방법 및 절차
2.1 연구 프레임워크
2.2 머신러닝 및 딥러닝 모델
2.3 성능 평가 지표
3. 실험 및 결과
3.1 데이터 설명
3.2 실험 환경 및 구현 세부 사항
3.3 암석 분류 모델 분류 결과 분석
4. 결 론
1. 서 론
터널은 도로, 철도, 지하 인프라 등 다양한 사회기반 시설에서 핵심적인 역할을 수행하며, 터널의 안정성 확보는 경제적, 사회적 관점에서 매우 중요하다(Kim et al., 2005). 그러나 지하공간은 불균질하고 복잡한 지질 구조로 인해 굴착 과정 및 유지관리 과정에서 높은 불확실성을 가지며, 이로 인해 예기치 않은 지반침하나 심한 경우 붕괴와 같은 안전사고가 발생할 수 있다(Liu et al., 2023). 이러한 사고는 인명 피해와 더불어 경제적 손실을 초래할 수 있으며, 사회적 신뢰에도 부정적인 영향을 미친다. 따라서 터널 설계 및 유지관리 과정에서 암반의 특성을 정확히 파악하고, 이를 기반으로 안정성을 평가하는 것은 필수적인 과제이다. 기존에는 현장 지질조사와 광물학적·지구화학적 검토 등을 통해 암석을 분류해왔다(Fernandez-Gutierrez et al., 2021). 이를 위해 전문 분석 기기나 편광 현미경을 활용하였으며 이러한 장비를 이용한 결과를 전문가가 분석하여 암석을 분류하였다(Młynarczuk et al., 2013). 이러한 전문적인 기기 외에도 암석의 조직, 구성광물 종류, 입자 크기, 색 등을 육안으로 관찰하는 기준 또한 존재하나 전문적인 기기를 활용했을 때보다 경험과 역량에 더 의존할 수 밖에 없었다(Moon et al., 2005).
이 같은 한계점을 극복하기 위하여, 최근 다양한 산업 분야에서 급격히 발전하고 있는 빅데이터 및 인공지능(AI) 기술이 지질공학 분야에도 적극 도입되고 있다(Baghbani et al., 2022). 특히 이미지 인식, 음성 인식, 자연어 처리 등 다양한 응용 분야에서 탁월한 성능을 보이며 각광받고 있는 딥러닝(Deep Learning)은, 대규모 데이터를 바탕으로 복잡한 패턴을 스스로 학습하고 추론할 수 있다는 점에서 암석 분류 작업에도 큰 잠재력을 지닌다. 예컨대 현장에서 촬영된 암석 노출면 사진이나 실험실에서 얻은 암석 표면 이미지를 대량으로 확보하고 이를 딥러닝 모델에 학습시킴으로써, 모델이 암석 표면의 미세 구조나 색상·조직 차이 등을 인식·분석하여 암석 유형을 자동으로 분류할 수 있게 된다(De Lima et al., 2019; Ran et al., 2019; Carpenter, 2020). 이는 기존의 광물학적·지구화학적 조사 과정을 대체 또는 보완할 수 있을 뿐만 아니라, 현장 실시간 모니터링 시스템과 연계할 경우 시공 및 유지관리 효율을 획기적으로 높일 수 있다는 점에서 높은 활용도를 기대할 수 있다.
더욱이 적시성(timeliness) 있는 데이터를 기반으로 한 의사결정이 이루어져야 하는 실시간 분류 및 피드백 시스템의 중요성이 더욱 강조되는 시점에 딥러닝 모델을 통한 암석 분류는 시료 채취 및 분석에 걸리는 시간을 크게 단축시키고, 기존에 조사자가 광학 현미경 및 주관적 지식을 사용해 수행하던 분석 과정을 자동화함으로써, 시공 현장의 불확실성 감소와 위험 요소 사전 파악에 기여할 수 있다. 더 나아가 암반 분류가 정밀하고 일관성 있게 이루어지면, 터널 안정성 평가나 붕괴 위험 예측 등의 다운스트림(downstream) 작업에서 활용되는 입력 데이터의 품질도 높아진다. 이는 장기적으로 유지관리 전략 수립, 지하공간 재활용 계획, 안전 모니터링 시스템 구축 등 다양한 측면에서 시너지 효과를 가져올 것으로 기대된다(Hasegawa et al., 2019).
물론 딥러닝 기반 암석 분류 프레임워크를 구축하기 위해서는, 충실한 데이터세트 확보가 필수적이다. 암석 샘플의 다양성과 수가 충분히 확보되지 않는다면, 모델이 학습 과정에서 과적합(overfitting)되거나 특정 암석 유형에만 특화된 예측 결과를 내놓는 등 신뢰성이 저하될 위험이 존재한다(Chen et al., 2021). 또한 이미지나 물성 데이터의 전처리 방법, 모델 구조 선정, 하이퍼파라미터 튜닝, 평가 지표 선정 등 모델 개발 과정에서도 고려해야 할 사항이 다양하다. 나아가 실제 시공 현장 적용에 앞서, 실험실·현장 수준에서 파일럿 테스트를 통해 모델의 실효성 및 안정성을 검증해야 한다. 이런 점들을 종합적으로 고려할 때, 딥러닝을 통한 암석 분류 시스템이 전통적인 지질학적 분류 방법을 완전히 대체하기 위해서는 기술적·현장적 측면에서의 체계적인 연구와 검증이 필수적이다(Sun and Gu, 2022).
현재까지 딥러닝 기술을 활용한 연구에서는 주로 Convolutional Neural Networks(CNN) 기반 모델들이 암석 분류 작업에 적용되어왔다(Krizhevsky et al., 2012). ResNet 같은 CNN 모델은 비교적 단순한 구조를 가지면서도 효율적인 피처 추출과 높은 암종 분류 성능을 제공한다(He et al., 2016). 또한 경량화된 CNN 모델인 MobileNet (Howard, 2017)과 EfficientNet(Tan and Le, 2019)은 모델 크기와 계산량을 줄여 리소스 제약 환경에서도 우수한 성능을 보인다. 본 연구에서는 이러한 필요성과 배경을 토대로, 터널 안정성 모니터링 및 유지관리를 위한 딥러닝 기반 암석 분류 프레임워크를 제안한다. 구체적으로는 다음과 같은 두 가지 목적과 연구 범위를 설정하였다.
첫 번째는 다양한 딥러닝 모델 적용 및 성능 평가로 ResNet, MobileNet, EfficientNet 등 다양한 합성곱 신경망(CNN) 모델을 활용하여 암석 이미지를 분류하고, 각 모델의 분류 정확도와 장·단점을 비교·분석한다.
두 번째는 화성암·퇴적암·변성암을 비롯하여 세분화된 암석 유형(예: 대리암, 사암, 편암 등)에 이르는 단계적 분류 실험을 수행함으로써, 분류 난이도 차이 및 모델의 한계를 종합적으로 진단한다.
이를 통해 본 연구는 기존의 지질학적 분류 방법을 보완하거나 실시간 모니터링 시스템과 연계하여, 시공·유지관리 효율을 높일 수 있는 근거를 마련하고자 한다.
2. 연구 방법 및 절차
2.1 연구 프레임워크
본 연구는 머신러닝 및 딥러닝 모델을 활용하여 암석을 분류하고, 그 결과를 해석함으로써 분류 모델의 효율성과 한계를 파악하는 것을 목표로 하였다. 이를 위해 전체 연구 프로세스를 Fig. 1과 같은 네 단계로 구분하였다. 첫째, 데이터 선정 및 전처리 단계를 통해 적절한 데이터셋을 확보하고 전처리 과정을 거쳐 학습 가능한 형태로 변환하였다. 둘째, 앞서 준비된 데이터를 활용하여 암석 분류 모델을 학습·검증한 뒤, 최적 성능 모델을 선정하였다. 셋째로는 선정된 암석 분류 모델의 암석 분류 성능을 평가하였다. 마지막으로, 결과와 고찰 과정을 통해 분류 모델이 가진 강점과 단점을 분석하였다. 본 연구는 화성암, 퇴적암, 변성암의 세 종류 암석을 분류하는 실험을 중점적으로 진행하였으며 세부 암석 분류도 추가적으로 진행하여 그 성능을 검증하였다.
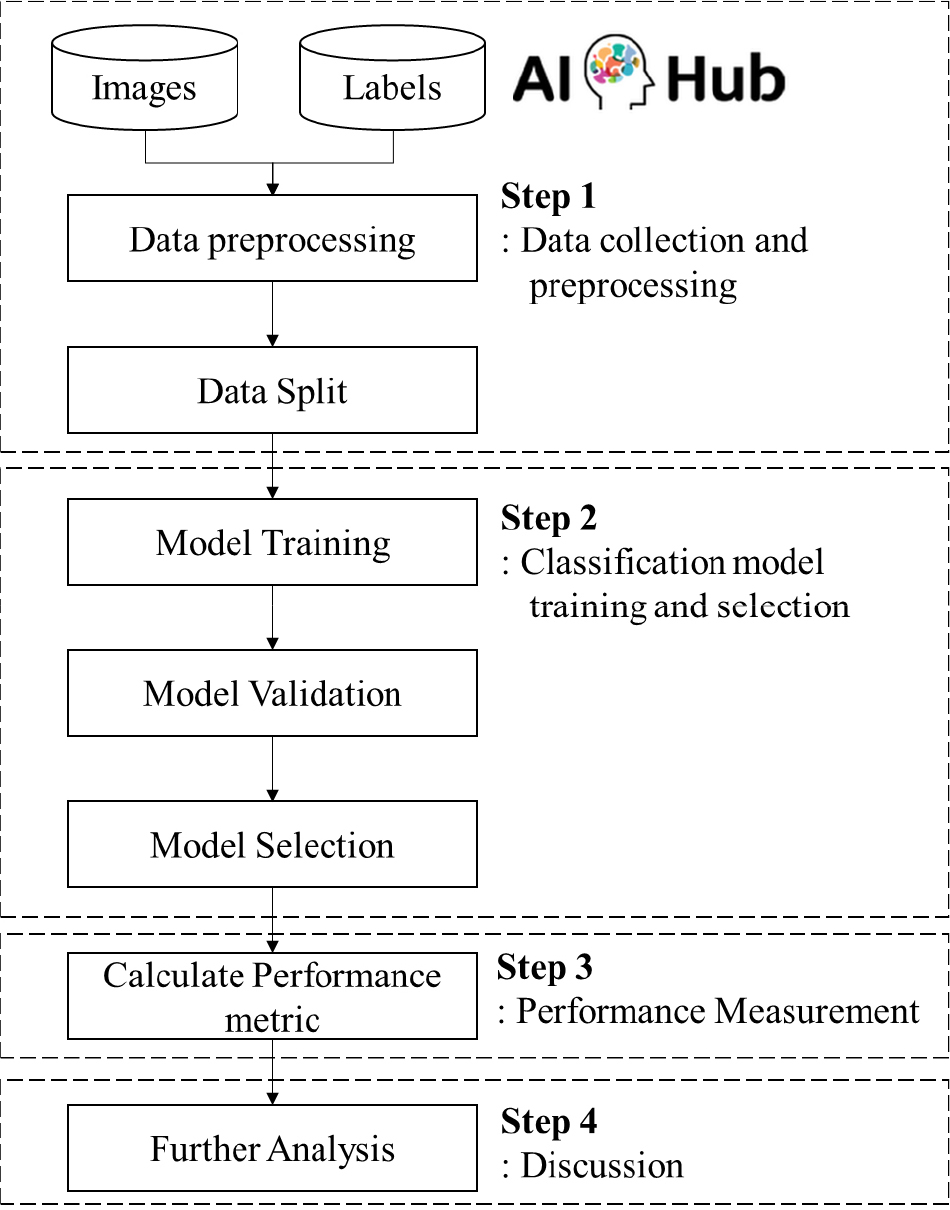
본 연구의 특징은, 일반적인 이미지 분류 프레임워크를 적용하면서도 (a) 터널 안정성 모니터링 및 유지관리라는 지반공학적 맥락에 중점을 두었다는 점, (b) 암석 이미지의 대분류(화성암, 퇴적암, 변성암)부터 세분류(18개 이상의 암석 유형)에 이르는 다단계 분류를 동시에 시도하여 과제 난이도와 실제 적용성을 평가했다는 점이다. 또한, 이미지만을 사용하는 기존 연구와 달리 터널 굴착·시공 단계에서 실시간 확보되는 영상 데이터와 연계할 수 있도록 경량 모델(MobileNet, EfficientNet)을 병행하여 적용했다는 차별성이 있다. 이를 통해 빠른 추론 시간과 현장 적용 가능성을 검토했다는 점에서 기존 딥러닝 기반 분류 연구와 구분된다.
2.2 머신러닝 및 딥러닝 모델
암석 분류 작업은 이미지의 부분적 특징과 전체적 특징을 균형 있게 반영해야 한다는 점에서, 모델 선택과 구조 설계가 결과에 큰 영향을 미칠 것으로 생각되었다. 본 연구에서는 전통적인 신경망 구조부터 최근 딥러닝 분야에서 우수성이 입증된 모델에 이르기까지, 여러 아키텍처를 선정하여 성능을 비교·분석하였다. 우선, 단순 신경망(Simple Neural Network)을 통해 암석 이미지 분류가 가지는 난이도를 확인하고, 합성곱 신경망(CNN)을 적용함으로 이미지 특징을 보다 높은 성능으로 추출하고자 하였다. 이후에는 CNN 기반의 대표적 모델인 ResNet과 EfficientNet, 그리고 경량화 모델로 널리 알려진 MobileNet을 단계적으로 적용함으로써, 모델의 구조가 분류 정확도뿐만 아니라 연산 효율과 실제 응용 가능성에 어떠한 영향을 미치는지를 체계적으로 평가하고자 하였다.
2.2.1 단순 신경망(Simple NN)
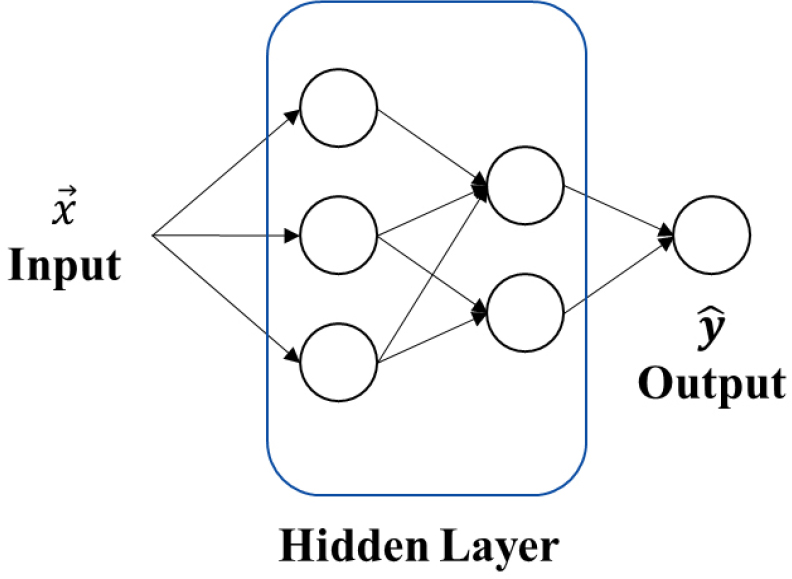
단순 신경망은 다층 퍼셉트론(Multi Layer Perceptron, MLP) 구조로 구성되며, 이미지 입력을 별도의 합성곱 연산 없이 전결합(Fully-connected) 형태로 처리한다. 일반적으로 입력층(Input layer), 출력 층(Output layer)외에 은닉층(Hidden layer)을 기본적인 구조로 가지며, 각 은닉층의 뉴런(Neuron) 수와 활성화 함수(Activation function)를 조정함으로써 모델 복잡도를 결정한다. 활성화 함수로는 ReLU(Rectified Linear Unit)나 Sigmoid, Tanh 등이 적용될 수 있고, 최적화 알고리즘으로는 SGD(Stochastic Gradient Descent)나 Adam(Adaptive Moment Estimation) 등을 사용한다.
단순 신경망은 구조가 간단하고 해석하기 용이하며, 비교적 적은 계산 자원으로도 구현이 가능하다는 장점이 있다(Fig. 2). 그러나 이미지 분류처럼 고차원 데이터에서 유의미한 공간적 패턴(예: 암석 표면의 조직이나 색상 변화)을 학습하기에는 한계가 명확하다(LeCun et al., 1998). 즉, 모든 픽셀 정보를 1차원화(Flatten)하여 입력하다 보니, 인접 픽셀 간의 국소적 특성이 사라지고 모델이 분류 결정에 활용할 수 있는 정보량이 제한된다. 따라서 본 연구에서는 단순 신경망을 초기 비교 대상으로 삼아, 이미지 분류 태스크에서의 난이도와 기본 성능 기준을 확인하는 기초 단계로 활용하였다.
2.2.2 합성곱 신경망(Convolutional NeuralNetwork, CNN)
합성곱 신경망은 이미지 처리에 특화된 구조로, 합성곱 계층(Convolution layer)을 통해 공간적 국소 영역에서 특징을 추출하고, 풀링 계층(Pooling layer)으로 특징 맵(Feature map)의 크기를 축소함으로써 불필요한 잡음을 억제하며 의미 있는 정보를 보존한다(LeCun et al., 1998; Krizhevsky et al., 2012). 합성곱 필터(커널, Kernel)는 학습 과정에서 자동으로 최적화되어, 암석 조직의 국소 패턴이나 밝기·색상 변화 등을 학습하는 데 유리하다. 이는 전결합층만 사용하는 단순 신경망과 달리, 이미지에서 공간적 상관관계를 자연스럽게 반영할 수 있음을 의미한다.
CNN 구조는 일반적으로 “합성곱 + 활성화(ReLU) + 풀링” 블록이 연속적으로 쌓이는 형태를 띤다. 블록이 깊어질수록 모델이 추출할 수 있는 특징은 더욱 복잡하고 추상화된 형태가 된다. 그러나 블록의 수가 증가함에 따라 파라미터 수가 폭발적으로 늘어나고, 학습에 필요한 계산량도 커진다는 단점이 있다. 또한 암석 이미지는 조직·색상의 다양성이 크며, 촬영 각도나 조명 상태가 달라지면 분류 난이도가 높아질 수 있으므로, 증강(Augmentation) 기법과 정규화(Regularization)를 적절히 병행해야 과적합을 방지할 수 있다. 정규화란 CNN의 가중치의 절대값 합을 식 (1)과 같이 비용 함수에 추가하여 가중치 크기를 제한하는 것을 뜻한다(Ng, 2004).
이 때, 는 기본 모델이 사용하는 원 손실함수(Original loss)를 의미하며 는 정규화항으로 모델 파라미터(가중치) 의 크기에 대한 페널티를 부여하여 과적합을 방지하는 역할을 한다. 결과적으로 최종 손실함수 를 최소화 하기 위해 모델 파라미터 𝜃는 과도하게 커지지 않게 된다.
2.2.3 ResNet(ResNet-18, ResNet-50)
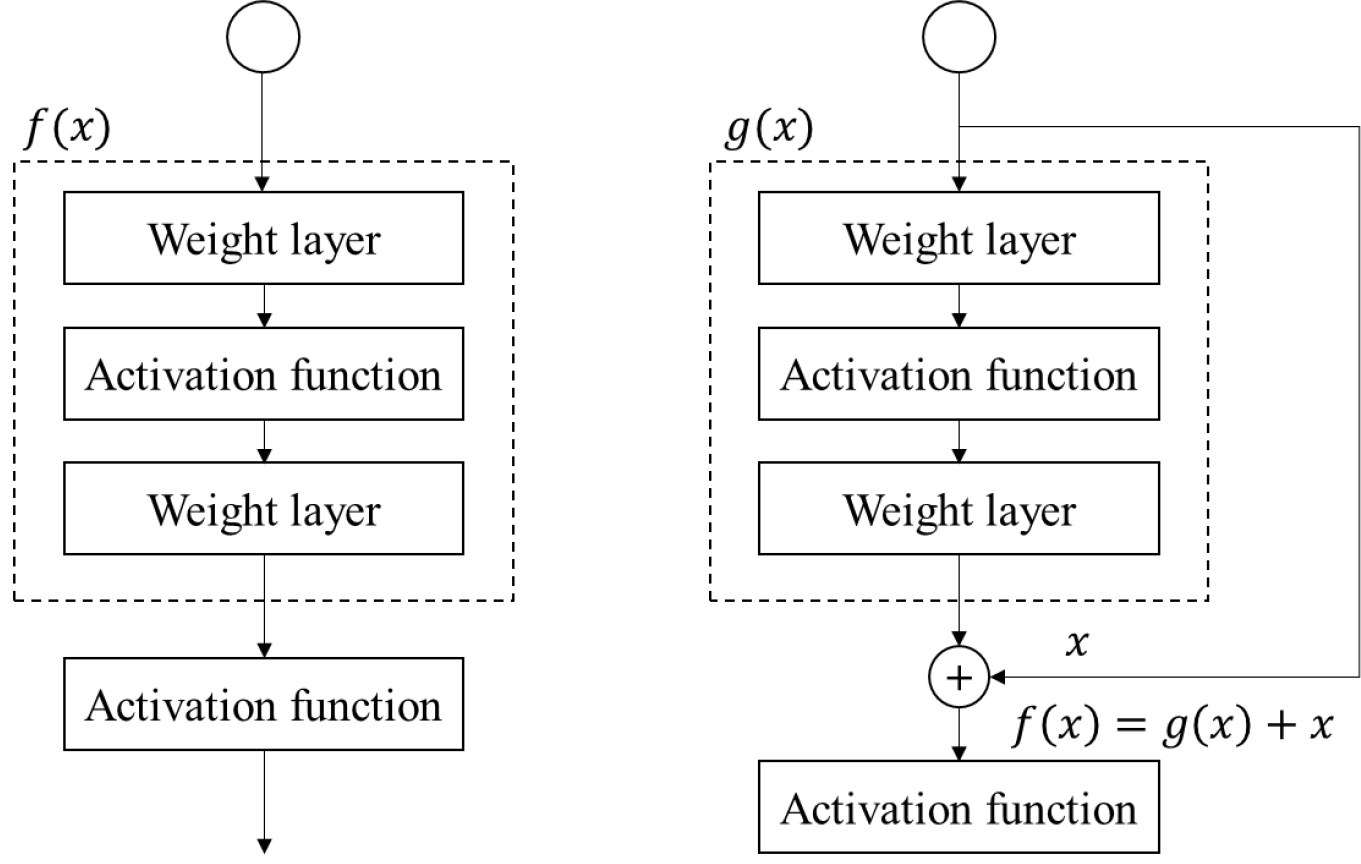
ResNet(Residual Network)은 딥러닝 모델의 심층화로 인한 기울기 소실 문제를 해결하기 위하여, 잔차 블록(Residual block) 내에 스킵 연결(Skip connection)을 삽입한 구조를 제안하였다(He et al., 2016). 스킵 연결은 입력 x를 일종의 우회 경로로 출력 F(x)에 더함으로써, 역전파 시 기울기가 보다 원활하게 전달되도록 만든다(Fig. 3). 이를 통해 기존 CNN보다 훨씬 깊은 네트워크를 안정적으로 학습할 수 있게 되었으며, ImageNet 등 대규모 이미지 데이터셋에서 획기적인 성능 향상을 달성하였다(He et al., 2016). 본 연구에서는 비교적 얕은 구조의 ResNet-18과, 더 깊은 레이어를 갖는 ResNet-50 두 가지를 실험 대상으로 선정하였다. ResNet-18은 파라미터 수와 연산량이 적어 학습 시간과 메모리 사용량에 있어 유리하며, ResNet- 50은 높은 표현력으로 인해 복잡한 암석 조직을 보다 효과적으로 추출할 것으로 기대되었다.
2.2.4 EfficientNet
EfficientNet은 모델의 깊이(Depth), 너비(Width), 해상도(Resolution)를 동시에 확장(Scaling)하되, 균형감을 유지하기 위한 컴파운드 스케일링(Compound scaling) 방법론을 제안함으로써, 파라미터 수 대비 높은 분류 정확도를 구현한다(Tan and Le, 2019). 이는 단순히 합성곱 채널 수나 레이어 수만 늘리는 데 그치지 않고, 다양한 차원을 동시에 조정함으로써 효율성을 극대화하는 접근이다. 또한 모델 내부의 핵심 연산으로는 모바일 환경에 최적화된 MBConv(Mobile inverted Bottleneck Convolution) 블록이 적용되어, 연산량이 감소하면서도 표현력이 유지된다. EfficientNet은 B0부터 B7까지 다양한 버전이 존재하며, B0는 상대적으로 파라미터 수가 적으면서도 표준 CNN이나 다른 딥러닝 모델 대비 우수한 분류 성능을 보이는 것으로 알려져 있다. 본 연구에서는 효율성과 정확도를 균형적으로 확보하기 위해, B0 버전을 중심으로 암석 분류 실험을 수행하였다.
2.2.5 MobileNet
MobileNet 계열은 스마트폰, 임베디드 디바이스 등과 같이 자원 제약이 있는 환경에서도 실시간 추론이 가능하도록 설계된 경량화 모델이다(Howard 2017; Sandler et al., 2018). 핵심 아이디어는 합성곱 연산을 Depthwise Convolution과 Pointwise Convolution으로 분리하는 “Depthwise Separable Convolution”을 통해, 전통적인 합성곱 대비 파라미터 수와 연산량(FLOPs)을 크게 줄인다는 점이다(Fig. 4). 또한 MobileNet-V2에서는 Inverted Residual 블록을 통해 입력·출력 채널을 적절히 축소·확장함으로써, 연산 효율과 분류 정확도를 모두 높이는 성능을 달성하였다.
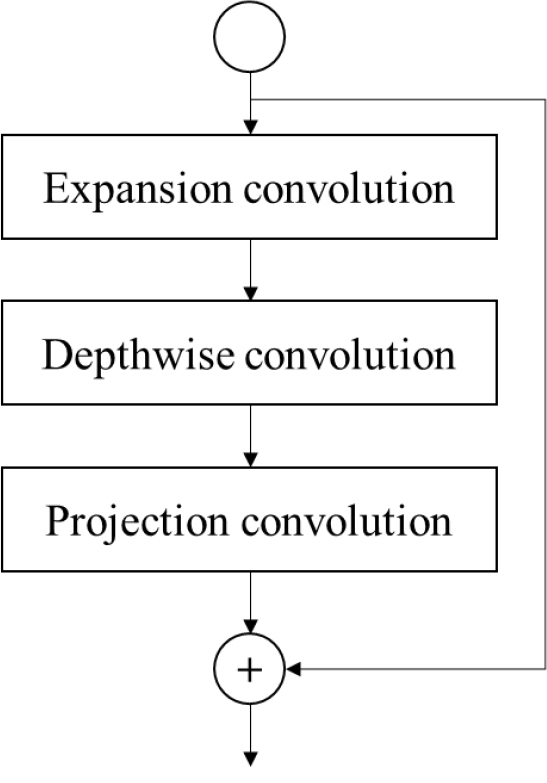
암석 분류 작업에서 MobileNet을 적용하는 이유는, 향후 현장 적용 시 휴대용 기기나 간단한 산업용 컴퓨터에서도 추론이 가능하도록 하기 위함이다. 기존의 대형 CNN이나 초심층(ultra-deep) 모델은 높은 정확도를 보장하지만, 계산 자원과 메모리가 충분치 않은 상황에서는 실시간 추론이 어려울 수 있다. MobileNet은 비교적 작은 모델 크기에 비해 이미지 특징 추출 성능이 우수해, 다양한 현장 적용 사례에서 각광받고 있다.
2.3 성능 평가 지표
암석 분류 모델의 성능을 정확하게 측정하고 비교하기 위해서는, 모델이 예측한 결과와 실제 라벨 간의 일치 정도를 다양한 관점에서 평가할 필요가 있다. 전통적으로는 정확도(Accuracy)가 가장 널리 사용되는 지표이지만, 데이터 분포의 불균형이나 특정 암석 유형 간 극명한 난이도 차이가 존재하는 경우, 정확도 하나만으로 모델의 성능을 완전히 파악하기는 어렵다. 따라서 본 연구에서는 클래스별 정확도를 구한 뒤 단순평균한 정확도와 정밀도(Precision), 재현율(Recall), F1-Score 등 모델의 세부 성능을 종합적으로 판단할 수 있는 지표들을 함께 고려하였다.
먼저, 정확도(Accuracy)는 전체 샘플 중에서 모델이 올바르게 분류한 비율로, 식 (2)와 같이 표현할 수 있다.
암석 분류 분야에서 정확도는 쉽게 해석 가능하고, 클래스 간 분포가 고르게 분포되어 있을 때 직관적인 판단 기준이 될 수 있다. 그러나 특정 암석(예: 화성암)이 다른 암석 대비 압도적으로 많이 포함되거나, 쉽게 구분되는 일부 암석이 모델 성능 전반을 좌우하는 경우에는 왜곡된 결과를 초래할 수 있어 주의가 필요하다.
이러한 한계를 보완하기 위해, 본 연구에서는 정밀도(Precision)와 재현율(Recall), 그리고 이 둘의 조화평균을 취한 F1-Score를 추가적으로 사용한다.
정밀도는 모델이 특정 암석 유형으로 예측한 샘플 중 실제 해당 암석인 비율을, 재현율은 실제로 해당 암석 유형에 속한 샘플 중 모델이 올바르게 검출해낸 비율을 의미하며 한 클래스 c에 대한 정밀도 및 재현율은 각각 아래의 식 (3) 및 식 (4)와 같이 나타난다.
여기서 는 클래스 c에 대해 올바르게 예측된 샘플 수(True Positive), 는 클래스 c에 대해 잘못 예측된 샘플 수(False Positive)를 나타내며, 는 클래스 c에 대해 놓친 샘플 수(False Negative)를 나타낸다. F1-Score는 정밀도와 재현율의 조화 평균으로, 0에서 1 사이의 값을 가지며 값이 클수록 분류 성능이 높다고 평가할 수 있다.
3. 실험 및 결과
3.1 데이터 설명
본 연구에서는 AI Hub에서 공개한 “기반암 시추 시료를 이용한 암반 등급 분류 데이터”를 활용하여 암석 분류 모델 학습에 활용하였다. 해당 데이터셋은 국내 여러 지질 연구기관이 협력하여 확보한 약 6,000상자 이상의 시추 코어 샘플을 기반으로 구성되었으며 최종적으로 약 55만장, 약 240GB에 달하는 고해상도 이미지를 포함한다.
원시 데이터는 시추 샘플에 부착된 파편을 제거한 뒤, 시료 박스를 수직으로 배치하고 3단계 조명 환경에서 4K급 카메라 2대를 이용해 촬영되었다(Fig. 5). 이렇게 수집된 이미지는 전문 지질학자가 직접 암석 종류를 분류, 라벨링하고 이후 검수 과정을 거쳐 최종적으로 JSON 파일 형태로 레이블 정보가 저장되어 있다(Fig. 6).

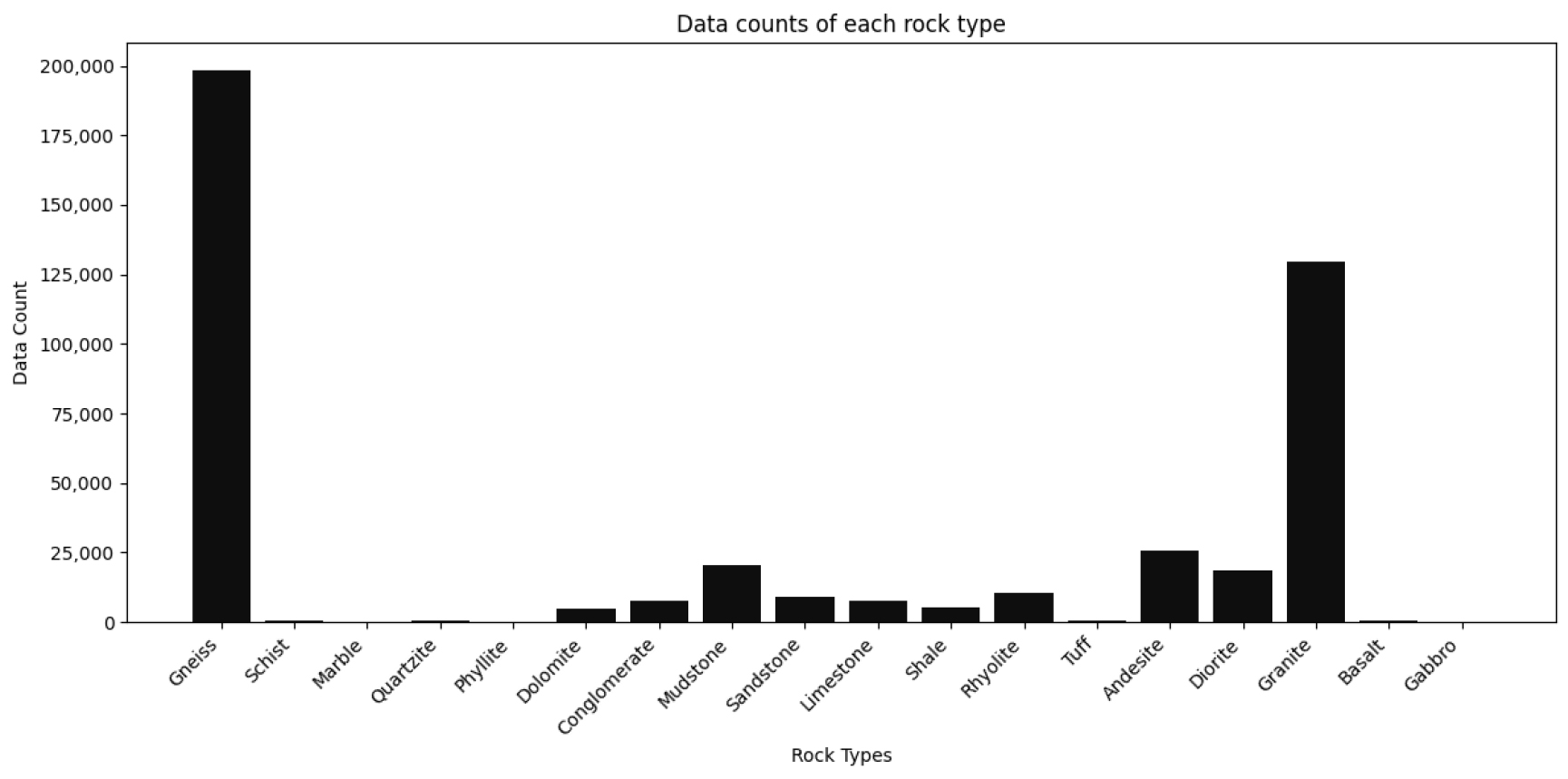
Table 1은 수집된 데이터를 대분류(변성암, 퇴적암, 화성암)로 나누고, 각 세부 암석명을 기준으로 데이터 개수를 정리한 결과이다. 변성암에서는 편마암이 198,267개로 가장 많은 데이터를 차지하며, 퇴적암에서는 이암(20,625개)과 사암(9,072개)이 주요 데이터를 구성하였다. 화성암 중에서는 화강암이 129,515개로 가장 큰 비중을 차지하며, 안산암(25,810개)이 그 뒤를 이었다 (Fig. 7).
Table 1.
Rock types and corresponding data counts categorized by major classification
데이터 수집 이후 전처리 단계에서는 모델이 암석 이미지의 핵심 특징(광물 조직, 결, 미세 균열 등)을 더욱 효율적으로 학습할 수 있도록 크기 재조정(Resizing) 및 색상 채널 정규화를 수행하였다. 또한 증강(Augmentation) 기법을 통해 이미지를 임의로 회전, 반전, 밝기·채도 변화 등을 적용함으로써 학습 데이터의 다양성을 확보하였다.
3.2 실험 환경 및 구현 세부 사항
본 연구에서는 대규모 암석 이미지를 효율적으로 처리하고, 모델 학습 과정의 속도를 더하기 위해 NVIDIA GPU가 장착된 컴퓨팅 환경에서 실험을 수행하였다(Table 2). 하드웨어 측면에서는 인텔 코어 i7-12700K 프로세서를 탑재하고, 64GB 메모리를 갖춘 시스템을 사용하였으며, 그래픽 연산을 위한 GPU로는 Geforce RTX 3070 Ti를 활용하였다. 이러한 사양은 딥러닝 모델을 학습하는 과정에서 충분한 연산 처리 능력과 메모리 여유를 제공하므로, 본 연구에서 시도한 다양한 모델의 학습 및 추론 과정이 원활하게 진행될 수 있도록 지원하였다. 소프트웨어 환경은 Window 10 운영체제에서 구축하였으며, 프로그래밍 언어로는 Python 3.10.10을 사용하였다. Python은 풍부한 머신러닝·딥러닝 생태계를 보유하고 있어, 본 연구에서 요구되는 이미지 전처리, 모델 구축, 시각화 및 분석에 이르기까지 전 과정에서 효율적인 개발 환경을 제공한다. 실제 코딩 및 결과 확인은 주피터 노트북(Jupyter Notebook)을 통해 진행하였는데, 이는 셀 단위 실행 및 시각화가 용이하여 데이터 전처리, 모델 학습, 성능 검증 과정을 직관적으로 살펴보기에 적합하다.
Table 2.
Development environment used for the experiment
딥러닝 프레임워크 및 라이브러리로는 Pytorch 2.2.2+ cu121 버전을 사용하였다. 이는 CUDA(CU) 기반 GPU 연산을 지원하는 버전으로, 모델 학습 시 GPU 가속을 통해 연산 시간을 크게 단축할 수 있다. 해당 프레임워크와 함께 NumPy, Pandas, Matplotlib, OpenCV 등의 추가 라이브러리도 활용하여, 데이터 로딩과 전처리, 모델 구현과 학습, 성능 지표 계산 및 시각화를 체계적으로 수행하였다. 또한 실험 결과의 재현 가능성을 높이기 위해, 학습 파이썬 스크립트와 노트북 전체에 무작위 시드(Random Seed)를 고정하는 방안을 적용하여, 동일 환경에서 반복 실험 시 일관된 결과를 얻을 수 있도록 하였다.
3.3 암석 분류 모델 분류 결과 분석
본 연구에서는 앞서 설명한 데이터셋(3.2절)을 기반으로 암석 이미지를 화성암, 퇴적암, 변성암의 3개 범주로 분류하는 머신러닝 및 딥러닝 모델을 구축하였다. 모델 학습 과정은 크게 전처리된 이미지 데이터의 입력, 각 모델별 하이퍼파라미터 설정, 학습 및 검증, 최종 성능 평가의 순서를 따른다. 먼저 전처리된 이미지들은 무작위 분할을 통해 학습(Training)·검증(Validation)·테스트(Test) 세트로 구분되었으며, 각 라벨의 데이터 분포를 유지(계층적 분할, Stratified Split)한채로 전체 데이터의 60%, 20%, 20%를 각각 학습, 검증, 테스트 데이터로 사용하였다. 데이터 증강 기법을 활용하여 모델이 실제 촬영 환경의 다양성(조명, 각도, 해상도 차이 등)에 강건하도록 만들었다. 학습 중에는 검증 세트를 활용해 최적의 하이퍼파라미터를 탐색하였고, 최종 모델의 성능은 테스트 세트에서 산출되는 분류 지표로 평가하였다.
본 연구에서는 이들 모델에 대해 학습률(Learning rate), 옵티마이저(Optimizer), 에포크(Epoch) 등 주요 하이퍼파라미터를 계층적으로 탐색하였으며, 검증 세트에 대한 오분류율 및 손실 함수를 모니터링하면서 손실 함수가 5번 이상 감소하지 않을 시 조기 종료(Early stopping)를 적용하였다.
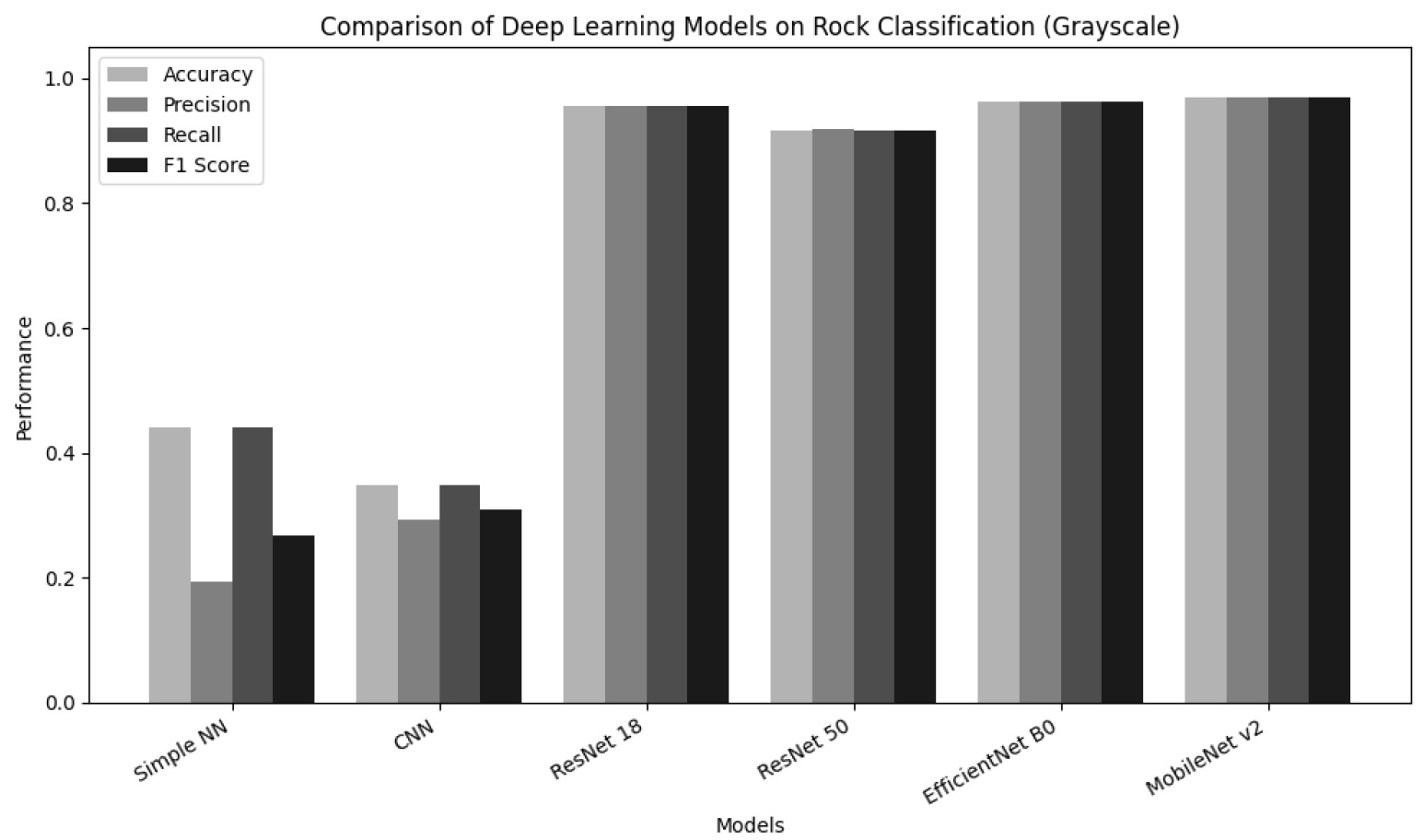
단순 신경망(Simple NN)의 경우 은닉층을 총 5개로 설정하고, 각 은닉층당 뉴런 수를 64, 128, 256개 등으로 변경하며 초기 실험을 수행하였다. 그 결과, 128개 뉴런을 사용했을 때 검증 데이터에서 가장 높은 예측 성능을 보였다. 활성화 함수는 ReLU, Tanh, Sigmoid를 각각 적용·비교한 뒤, ReLU가 가장 안정적인 학습을 보여 최종 선택하였다. 학습률은 0.01, 0.005, 0.001의 범위를 실험한 결과, 0.005에서 빠른 수렴 속도와 높은 예측 성능을 얻을 수 있음을 확인하였다. ResNet(ResNet-18, ResNet-50)와 EfficientNet (EfficientNet-B0), MobileNet(MobileNet-V2) 등은 Image Net으로 사전 학습된(Pretrained) 가중치를 초기 파라미터로 사용하여 전이학습(Transfer Learning) 기법으로 학습을 진행하였다. .ResNet-18, ResNet-50의 경우 학습률을 0.01, 0.005, 0.001로 실험한 결과, 두 모델 모두 0.005에서 최적 성능을 달성하였다. 최적화 알고리즘은 Adam을 사용하였으며, 배치 크기(Batch size)는 GPU 메모리 제약을 고려하여 ResNet-18은 32개, ResNet-50은 16개로 설정하였다. Dropout 비율은 0.1, 0.2, 0.3을 비교·평가하여, 0.2에서 가장 우수한 일반화 성능을 확보하였다. EfficientNet의 경우 ResNet과 마찬가지로 ImageNet 사전 학습 가중치를 사용하였으며, 학습률을 0.01, 0.005, 0.001로 탐색한 결과, 0.001에서 성능이 가장 높게 나타났다. Dropout 비율 또한 검증 세트 기반으로 비교하여 0.1이 최적임을 확인하였다. MobileNet도 동일한 전이학습 전략을 적용하고, 학습률 후보군(0.01, 0.005, 0.001, 0.0001)을 테스트한 뒤 0.0001에서 가장 우수한 결과가 도출되었다. Dropout 비율도 0.1로 설정하여 과적합을 효과적으로 억제하였다. 이러한 과정을 통해 각 모델별로 최적 학습률 및 Dropout 비율을 선정할 수 있었으며, 최종 학습 시 Adam 옵티마이저(β₁=0.9, β₂=0.999)와 크로스 엔트로피(Cross Entropy) 기반 손실 함수를 사용하여 학습을 진행하였다. 모델 구조별로 학습 시간을 절감하고 과적합을 방지하기 위해, 검증 세트에서 연속으로 손실 감소가 관측되지 않으면 조기 종료하는 방식을 도입하였다. Table 3은 최종 테스트 세트에 대해 산출된 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 점수를 요약한 결과이다. 분류 결과를 종합적으로 살펴보면, Simple NN과 CNN 모델은 각각 정확도가 0.440과 0.347에 그쳐, 화성암·퇴적암·변성암을 구분하는 데 어려움을 보였다. 이는 단순 신경망 구조가 이미지의 지역적 특징을 학습하기에 한계가 있고, 기본 CNN도 합성곱 층이 깊지 않아 암석 표면의 복잡한 조직과 광물적 특징을 충분히 반영하지 못했기 때문으로 추정된다. 반면, ResNet-18과 ResNet-50은 각각 0.956, 0.917의 정확도를 나타내어 딥러닝 모델이 가지는 심층 구조가 암석 표면의 미세한 차이를 포착하는 데 유리함을 시사한다. 더 나아가, EfficientNet-B0와 MobileNet-V2는 각기 0.962, 0.971의 정확도를 보이며 전반적으로 우수한 성능을 기록하였다. 특히 MobileNet-V2의 경우, 경량화 모델로 알려져 있음에도 불구하고 0.971에 달하는 정확도를 나타내어, 화성암·퇴적암·변성암 분류 태스크에서도 효율성과 정확도를 모두 충족할 수 있음을 확인하였다(Fig. 8). 이는 Mobile Net-V2의 Depthwise separable convolution 및 Inverted residual 구조가 이미지 패턴 학습에 유리하게 작용한 것으로 해석된다.
Table 3.
Performance metrics of machine learning and deep learning models for classifying igneous, sedimentary, and metamorphic rocks
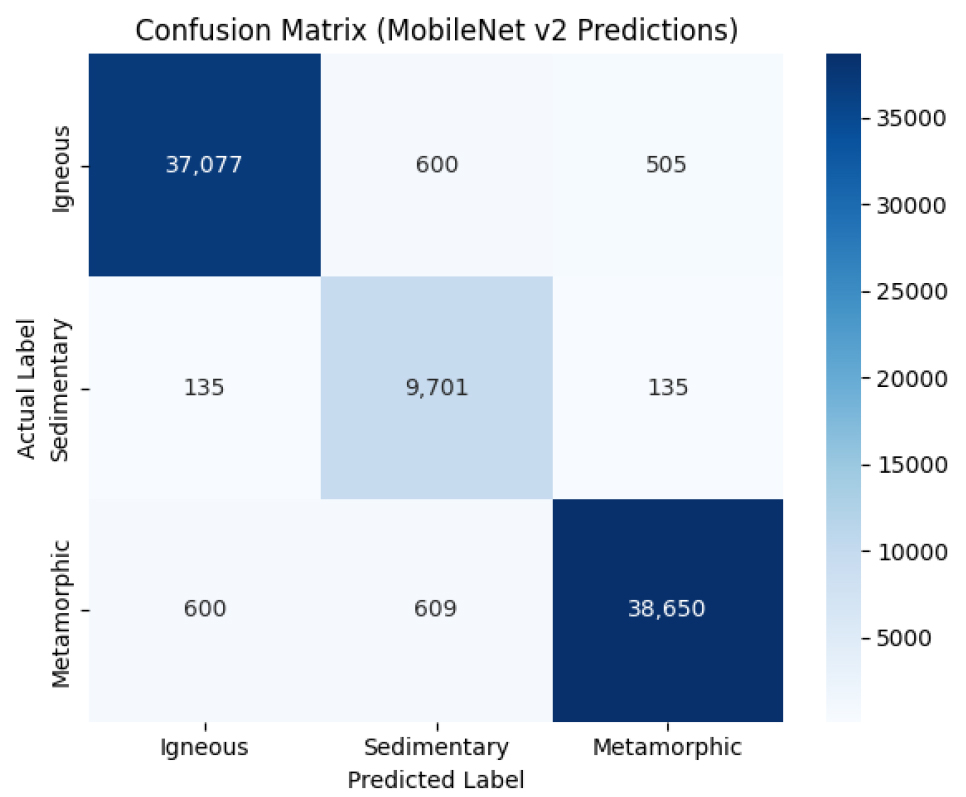
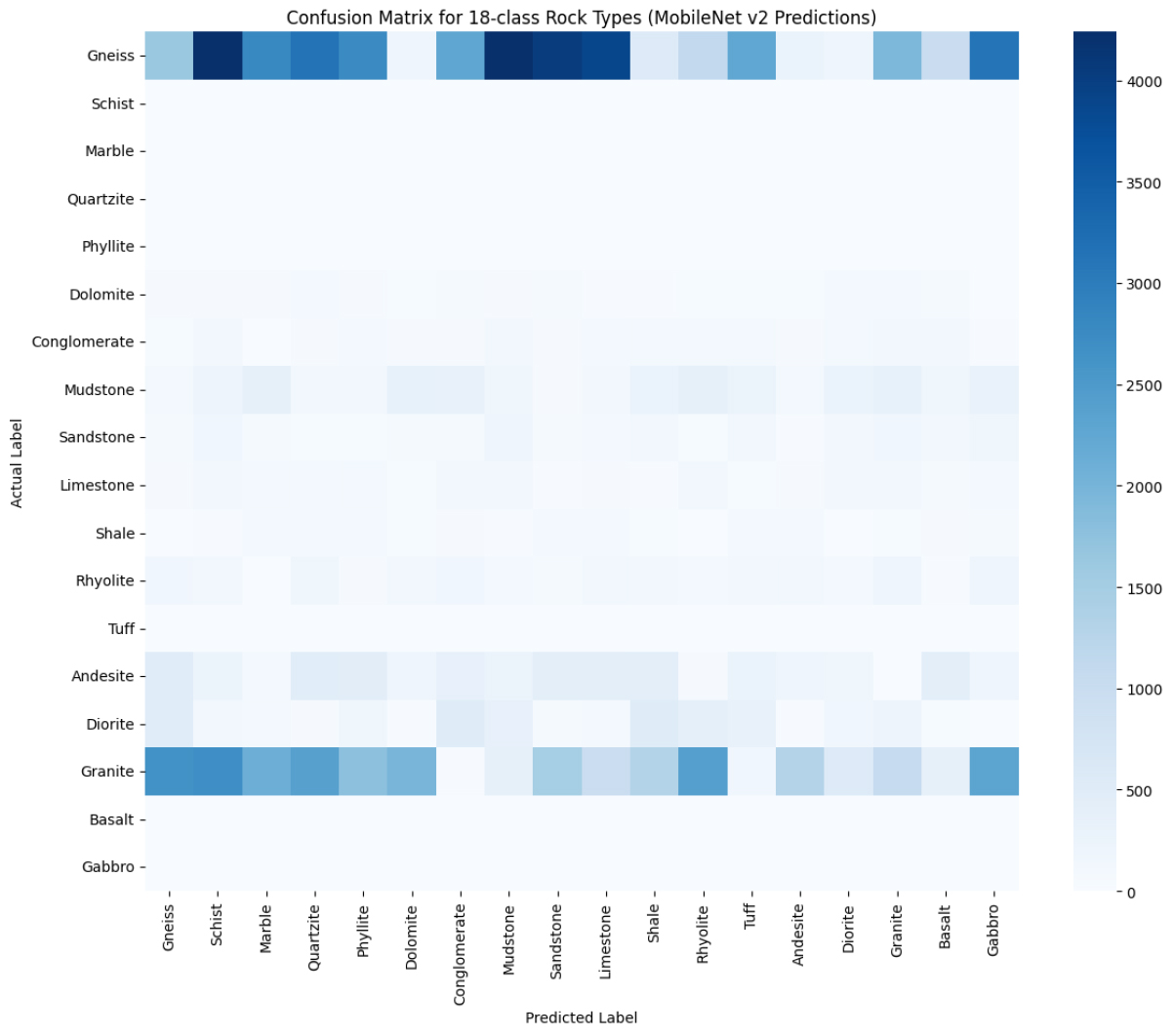
정밀도와 재현율, F1 Score 역시 정확도와 유사한 추이를 보이며, ResNet-18 이상의 모델에서는 전반적으로 0.90 이상의 높은 성능을 기록하였다. 이러한 결과는 세부 암석 조직이 유사한 변성암·퇴적암 사이에서도 모델이 높은 구분 능력을 갖출 수 있음을 의미한다. Fig. 9는 MobileNet의 예측결과에 대한 혼동행렬로 각 실제, 예측 레이블에 해당하는 데이터 개수를 표현한다.
세분화된 암석 분류 작업은 앞서 화성암·퇴적암·변성암을 분류했을 때와는 전혀 다른 양상의 결과를 보여주었다(Table 4). 규암, 대리암, 반려암, 백운암, 사암, 석회암, 섬록암, 셰일, 안산암, 역암, 유문암, 응회암, 이암, 천매암, 편마암, 편암, 현무암, 화강암 등 18개 범주로 확장한 뒤 모델을 학습시키자, 기존 딥러닝 구조(CNN, ResNet, EfficientNet, MobileNet, ShuffleNet 등)조차도 0.07 이하의 낮은 정확도를 기록하였다. 이는 3분류 단계에서 0.90 이상(일부 모델은 0.95 이상)의 정확도를 달성하던 성능과 극명한 대조를 이루며, 세분화된 암석 분류가 어려운 Task임을 증명한다. 특히 이러한 결과는 선행 연구(Moon et al., 2005)에서 전문가들조차 단순히 이미지만을 이용했을 때는 낮은 분류 정확도를 보인 것과 같은 결과이다. 규암과 사암, 백운암이나 대리암처럼 광물 조성이나 색채가 유사한 암석끼리는 조직과 표면 양상이 육안으로도 구분하기 어렵다. 또한 레이블링 과정에서 암석이 변성 과정을 겪거나 복합적인 광물 배합을 지닌 경우, 실제 라벨 자체도 전문가 간 이견이 발생하기 쉬워 학습된 모델이 혼란해할 가능성이 더욱 높아진다. 더욱이 데이터 양적 측면에서 각 암석 유형이 균일한 분포를 갖추지 못했기에, 특정 클래스는 충분히 학습되지 않아 분류 성능이 낮아진 원인으로 파악된다. 반면 상대적으로 특징적 무늬(결정립 크기 등)가 확연한 화강암 등 일부 클래스는 다른 암석 대비 높은 정확도를 보였다(Fig. 10). 결국 이러한 결과는 세분화된 암석 분류 작업이 아직까지 많은 연구·개선 여지가 있음을 보여준다. 특히 데이터 불균형은 세분화된 암석 분류 정확도를 낮추는 주요 원인 중 하나로 지목된다. 실제로 혼동행렬 분석에서, 데이터가 희소한 클래스(예: Phyllite)일수록 다른 암석 유형으로 오분류되는 비율이 높게 나타난다. 따라서 본 연구에서는 대분류(화성암·퇴적암·변성암) 단계에서 비교적 높은 정확도를 보이다가, 18종 세분류로 확장하였을 때 급격히 정확도가 떨어지는 현상을 데이터셋 구조상 한계로도 해석한다. 대규모 데이터를 확보하여 클래스별 균형을 맞추고, 각 암석의 특징적 조직이나 결을 더욱 선명히 보여줄 수 있는 이미지 전처리·데이터 증강 기법을 도입하며, 때로는 멀티모달 정보를 결합하는 등 다각도의 시도를 통해 문제 해결을 모색해야 한다. 궁극적으로는 현미경이나 스펙트럼 분석 데이터를 병행하는 방향으로 연구를 확장함으로써, 육안으로 식별하기도 어려운 암석 유형까지 더 높은 정확도로 분류하는 딥러닝 기반 자동화 시스템을 구축할 수 있을 것으로 기대된다.
Table 4.
Performance metrics of machine learning and deep learning models for classifying specific rock types
4. 결 론
본 연구에서는 다양한 머신러닝 및 딥러닝 모델을 적용하여 암석을 분류하는 자동화 시스템을 구축·평가하였다. 먼저 화성암·퇴적암·변성암의 대분류(3분류) 단계에서는 ResNet, EfficientNet, MobileNet 등 최신 딥러닝 모델이 전반적으로 90% 이상의 높은 정확도를 달성하여, 복잡한 암석 표면 특성과 광물적 변수를 효과적으로 학습할 수 있음을 확인하였다. 이는 심층 합성곱 구조가 지닌 우수한 특징 추출 능력이 고해상도 암석 이미지의 조직(texture), 색상, 결 등 다양한 정보를 효율적으로 파악하는 데 기여했기 때문으로 해석된다.
반면, 규암·대리암·반려암·백운암·사암·석회암·섬록암·셰일·안산암·역암·유문암·응회암·이암·천매암·편마암·편암·현무암·화강암 등 18개 세분류로 범위를 확장하자, 동일한 모델들조차 전반적으로 매우 낮은 정확도(0.07 이하)를 보여 극명한 성능 저하가 발생하였다. 이는 암석 세분류가 요구하는 미세 조직 및 광물학적 특성을 단일 이미지로 완전하게 파악하기가 쉽지 않으며, 변성 과정이나 광물 조합 등에 의해 클래스 경계가 모호해지는 경우가 다수 존재하기 때문으로 보인다. 또한 클래스별 데이터 불균형, 라벨링 난이도, 하이퍼파라미터 최적화 부족 등도 성능 저하에 복합적으로 작용했을 가능성이 크다.
이러한 결과를 통해, 본 연구는 딥러닝 접근법이 암석 분류 분야에서 실제 활용될 여지를 충분히 보여주는 동시에, 세분화된 암석 유형 식별에는 추가적인 연구·개선이 절실함을 시사한다. 향후 연구에서는 다음과 같은 개선 방안을 고려할 수 있다. 첫째, 계층적(Hierarchical) 분류 전략을 도입하여 먼저 화성암·퇴적암·변성암을 나눈 뒤, 각 범주 내에서 세밀한 분류를 수행함으로써 모델의 부담을 단계적으로 완화하는 방법이다. 둘째, 암석 표면 정보를 더욱 심층적으로 확보하기 위해 현미경 분석 이미지, 초분광 영상 등 멀티모달 데이터를 융합하여 모델이 얻을 수 있는 특징량을 극대화하는 전략이 필요하다. 셋째, 클래스별 편차를 줄이기 위해 충분한 데이터를 확보하거나, 데이터 증강 기법을 활용해 클래스 간 균형을 맞춤으로써, 모델이 일부 암석 유형에 과적합되거나 과소학습되지 않도록 하는 방안을 적극 강구해야 한다.
궁극적으로 본 연구는 딥러닝 기반 자동 분류 시스템이 암석 시료 분석 및 지반공학 전반에 걸친 디지털 혁신을 앞당기는 데 기여할 수 있음을 보여주었다. 다만, 높은 정확도가 요구되는 세분화 작업에는 여전히 해결해야 할 기술적·현장적 과제가 많으며, 향후에는 학계와 산업계 간 협력으로 데이터의 양적·질적 수준을 한층 높이고, 보다 정교한 모델 설계와 검증 절차를 마련할 필요가 있다. 이러한 후속 연구가 이루어진다면, 지질조사·터널 공학·광물 자원 탐사 등 다양한 분야에서 암석 분류의 자동화와 효율성을 크게 향상시키는 동시에, 인적 자원의 한계를 보완하고 과학적 신뢰도를 높이는 방향으로 발전할 수 있을 것으로 기대한다.
